Kimi K2.5 vs Claude Opus 4.5 vs Gemini 3 Pro: Native Multimodal Showdown
Moonshot AI just released Kimi K2.5—a native multimodal agentic model with a massive 1 trillion parameter MoE architecture, 262K context window, and the ability to coordinate up to 100 sub-agents. But how does this Chinese frontier model stack up against established leaders like Claude Opus 4.5 and Gemini 3 Pro? This comprehensive analysis compares capabilities, pricing, and strategic positioning to help you decide when to use each model.
We'll evaluate these three flagship models across:
- Kimi K2.5 - Moonshot AI's native multimodal model with Agent Swarm
- Claude Opus 4.5 - Anthropic's latest flagship for complex reasoning
- Gemini 3 Pro - Google's most powerful agentic and vibe-coding model
Time to read: 12-15 minutes
What is Kimi K2.5?
Kimi K2.5 is Moonshot AI's flagship native multimodal agentic model, released on January 27, 2026. It represents a significant leap in model architecture and capabilities, specifically designed for real-world agentic workflows and complex multi-step reasoning tasks.
Core architecture:
- Mixture-of-Experts (MoE) with 1 trillion total parameters, 32 billion activated
- Native multimodality supporting vision, text, and video understanding
- Ultra-long context of 262,144 tokens (262K)
- Agent Swarm capability coordinating up to 100 parallel sub-agents
- Thinking Mode and Instant Mode for flexible reasoning depth
Key differentiators:
K2.5 is the first model to natively integrate vision-language understanding at this scale while maintaining competitive pricing. Unlike models that bolt on vision capabilities post-training, K2.5's multimodal architecture is foundational, enabling more coherent cross-modal reasoning. The Agent Swarm feature allows the model to decompose complex tasks into parallel sub-problems and synthesize results—a capability unique to Moonshot AI's approach.
Why it matters:
For AI Crucible users building ensemble workflows, K2.5's massive context window (262K) means you can include extensive conversation history, multiple documents, or large codebases without compression. Combined with competitive pricing ($0.60 input / $3.00 output per 1M tokens), it offers a viable alternative to Western models for teams comfortable with Moonshot AI's platform.
How Do These Models Compare on Specifications?
Understanding the technical differences between these three flagship models helps inform when to use each one. Here's a comprehensive side-by-side comparison:
| Specification | Kimi K2.5 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|
| Provider | Moonshot AI (China) | Anthropic (USA) | Google (USA) |
| Architecture | MoE (1T total, 32B active) | Dense (undisclosed) | Dense (undisclosed) |
| Context Window | 262,144 tokens | 200,000 tokens | 2,000,000 tokens |
| Vision Support | Yes (Native) | Yes (Images + PDFs) | Yes (Images + Video) |
| Video Support | Yes | No | Yes |
| Input Cost (per 1M) | $0.60 (miss) / $0.10 (hit) | $5.00 | $2.00 |
| Output Cost (per 1M) | $3.00 | $25.00 | $12.00 |
| Cache Discount | 90% | 90% | N/A |
| Latency Class | Medium | High | Medium |
| Reasoning Model | Yes (3.5x) | No | Yes (4x) |
| Release Date | Jan 2026 | Nov 2025 | Dec 2024 |
| Agent Capabilities | Agent Swarm (100 agents) | Limited | Advanced |
| API Compatibility | OpenAI-compatible | Anthropic API | Google Vertex AI |
Pricing analysis highlights:
- Kimi K2.5 is 88% cheaper than Claude Opus 4.5 for input ($0.60 vs $5.00)
- Kimi K2.5 is 70% cheaper than Gemini 3 Pro for input ($0.60 vs $2.00)
- Cache optimization: K2.5 and Opus 4.5 both offer 90% discounts on cache hits
- For a typical ensemble run: Using K2.5 instead of Opus 4.5 could save ~$0.20 per round
Context window comparison:
- Gemini 3 Pro leads with 2M tokens (ideal for extremely long documents)
- Kimi K2.5 offers 262K tokens (sufficient for most use cases, including large codebases)
- Claude Opus 4.5 provides 200K tokens (standard for current-generation models)
What Are the Key Capability Differences?
Beyond specs and pricing, understanding the qualitative differences in model capabilities helps optimize your ensemble strategies:
Multimodal Understanding
Kimi K2.5: Native Multimodal Architecture
- Vision-language fusion from pre-training enables coherent cross-modal reasoning
- Video understanding processes temporal sequences, not just static frames
- Visual coding translates UI mockups, diagrams, or screenshots directly into code
- Limitation: Newer model with less public validation compared to competitors
Claude Opus 4.5: Post-Training Vision
- Image analysis excels at detailed visual descriptions and reasoning
- PDF understanding processes complex documents with layout comprehension
- Limitation: No video support; vision capabilities added post-training may lack deep integration
Gemini 3 Pro: Google's Multimodal Heritage
- Video + image mastery leverages Google's DeepMind research in multimodal learning
- Spatial reasoning understands 3D relationships and complex visual structures
- Wide MIME support handles PDFs, audio, JSON, YAML beyond just images
- Limitation: Less explicit agent orchestration compared to K2.5's Agent Swarm
Agent Orchestration
Kimi K2.5: Agent Swarm
Moonshot AI's standout feature allows K2.5 to:
- Decompose complex tasks into up to 100 parallel sub-agents
- Coordinate specialized agents for research, coding, analysis, and synthesis
- Recombine results into coherent final outputs
Example workflow: "Analyze this market" could spawn agents for competitor research, financial analysis, customer sentiment analysis, and regulatory review—all running in parallel before synthesis.
Claude Opus 4.5: Sequential Excellence
Opus excels at deep, sequential reasoning chains rather than parallel decomposition. It's better suited for:
- Linear thinking tasks that require step-by-step analysis
- Ethics and philosophy where reasoning depth matters more than breadth
- Creative writing where narrative coherence is paramount
Gemini 3 Pro: Agentic Coding
Google positions this as their "most powerful agentic and vibe-coding model," optimized for:
- Autonomous software engineering with tool use and execution
- Iterative refinement of code based on test results
- Large-scale refactoring across entire codebases
How Does Pricing Impact Ensemble Strategies?
For AI Crucible users building multi-model ensembles, cost optimization is critical. Here's how these models compare in typical workflows:
Single Round Cost (3-Model Ensemble)
Assuming a typical prompt with 1,000 input tokens and 2,000 output tokens per model:
| Configuration | Total Input | Total Output | Total Cost |
|---|---|---|---|
| 3x Kimi K2.5 | $0.0018 | $0.0180 | $0.0198 |
| 3x Claude Opus 4.5 | $0.0150 | $0.1500 | $0.1650 |
| 3x Gemini 3 Pro | $0.0060 | $0.0720 | $0.0780 |
| Mixed (K2.5 + Opus + Gemini) | $0.0076 | $0.0880 | $0.0956 |
Note: Cost calculations assume standard output tokens. If Kimi K2.5 or Gemini 3 Pro are used in Reasoning Mode, output tokens may effectively increase by 3.5x-4x, increasing output costs significantly (e.g., K2.5 output cost would rise to ~$0.063 per round).
Cost savings potential:
- Using K2.5 instead of Opus 4.5 saves ~88% per run ($0.0198 vs $0.1650)
- Using K2.5 instead of Gemini 3 Pro saves ~75% per run ($0.0198 vs $0.0780)
- For 10,000 queries/month, switching from Opus to K2.5 saves ~$1,450/month
7. Head-to-Head: Enterprise Architecture Challenge
To test these models in a complex, real-world engineering scenario, we ran a "Competitive Refinement" session in AI Crucible Public chat .
The Prompt:
"Our application needs to integrate with 15+ third-party services... We're experiencing API rate limits, inconsistent error handling... I need a robust integration architecture."
This prompt requires deep systems design knowledge, not just code generation. It demands a strategy for resilience, observability, and scaling.
The Approaches
| Model | Strategy Name | Key Concept | Score (est) |
|---|---|---|---|
| Gemini 3 Pro | Vendor Insulation Layer (VIL) | Treat vendors as "hostile" entities. Isolate them in "Provider Cells" with dedicated queues. | 9.5/10 |
| Claude Opus 4.5 | Context-Aware Integration Mesh | Sovereign cells with intent-based orchestration. | 9.1/10 |
| Kimi k2.5 | Adaptive Mesh Approach | Integrations as first-class citizens with lifecycle & health metrics. | 9.5/10 |
Gemini 3 Pro took the early lead with its "Vendor Insulation Layer" concept. Judges praised it for being "highly actionable" and providing concrete patterns like the "Hospital Queue" for failed events. Usefulness was rated at a near-perfect 9.8/10.
Kimi k2.5 (Moonshot) demonstrated its "System 2" capabilities by proposing an "Adaptive Mesh", focusing on the lifecycle of integrations. It correctly identified that "most integration failures aren't technical — they're contextual," aligning well with senior engineering intuition.
The Verdict: Synthesis Wins
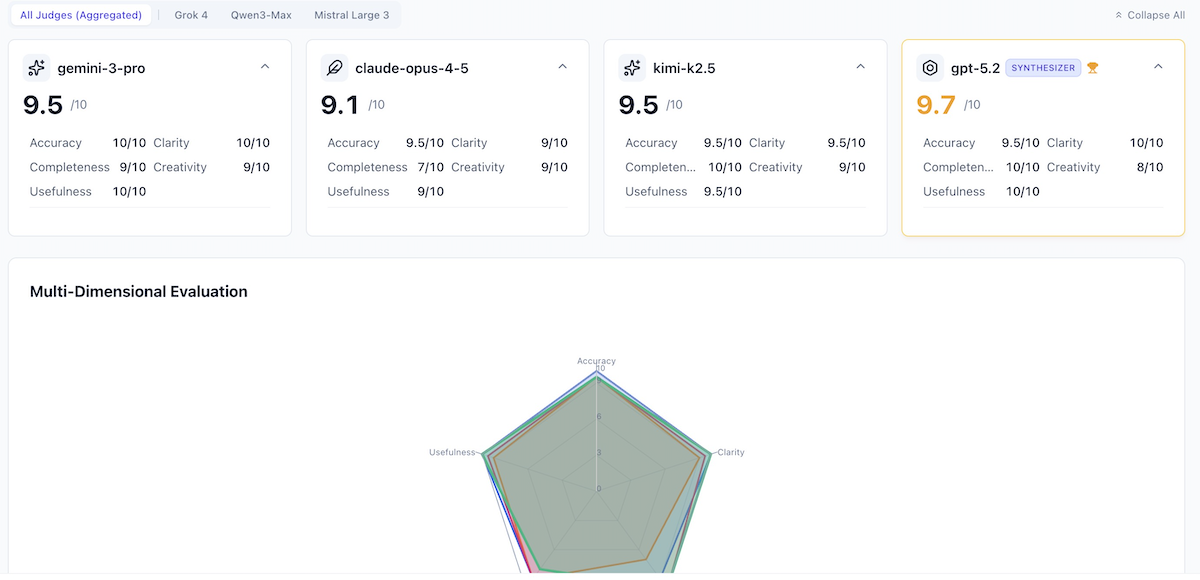
The AI Crucible Arbiter (GPT-5.2) synthesized these approaches into a final "Robust Integration Strategy", achieving a Synthesized Score of 9.7/10.
"Scaling from 3 to 15+ integrations transforms a coding problem into a distributed systems problem... To succeed, we must decouple your core application from this chaos." — Arbiter Verdict
The final synthesis combined Gemini's rigid isolation ("Provider Cells") with Kimi's adaptive lifecycle management, resulting in a guide that judges called "technically sound," "exceptionally accurate," and "immediately applicable to any integration project."
Related Articles
- Chinese AI Models Compared: DeepSeek vs Qwen vs Kimi K2 - In-depth Chinese model analysis
- Gemini 3 Flash vs 2.5 Flash, 2.5 Pro & 3 Pro - Complete Gemini benchmark
- GPT-5.2 vs 5.1: Quality, Cost, and Speed Benchmark - Latest GPT comparison
- Seven Ensemble Strategies Explained - Optimize your ensemble workflows
- Getting Started Guide - New to AI Crucible? Start here