Best Chinese AI Models Compared: DeepSeek vs Qwen vs Kimi K2 (2026 Benchmark)
The Chinese AI model landscape has matured dramatically in 2025. Three providers—DeepSeek, Alibaba (Qwen), and Moonshot AI (Kimi)—now offer world-class reasoning models that rival Western alternatives at a fraction of the cost. But how do they compare against each other?
This article provides a step-by-step walkthrough comparing the most capable reasoning models from each provider:
- DeepSeek Reasoner - DeepSeek's thinking mode model
- Qwen3-Max - Alibaba's flagship model
- Kimi K2 Thinking - Moonshot AI's enhanced reasoning model
Time to read: 10-12 minutes
Example cost: ~$0.02
The Three Chinese AI Giants
Before diving into the comparison, let's understand what makes each model unique.
DeepSeek Reasoner
DeepSeek has gained massive attention for its efficiency innovations. Their V3 architecture achieves frontier-level performance using a fraction of the compute through their Mixture-of-Experts (MoE) approach. DeepSeek Reasoner is the thinking mode variant that explicitly generates chain-of-thought reasoning before answering.
Key characteristics:
- 128K context window
- MoE architecture (671B total, ~37B active)
- Extremely aggressive pricing ($0.14/1M input tokens)
- Text-only (no vision support)
- Strong on math and coding
Qwen3-Max
Alibaba's Qwen3-Max represents China's answer to GPT-4. It's the most powerful model in the Qwen3 family, designed for complex tasks requiring deep reasoning and analysis. With a 262K context window and vision support, it's a versatile powerhouse.
Key characteristics:
- 262K context window (largest among the three)
- Vision/multimodal support
- Balanced pricing ($1.20/1M input tokens)
- Strong on Chinese language tasks
- Excellent for analysis and synthesis
Kimi K2 Thinking
Moonshot AI's Kimi K2 Thinking is specifically designed for enhanced reasoning capabilities. It sits between the faster K2 Turbo and delivers more thoughtful, deliberate responses. With a 200K context window, it's positioned as a reasoning specialist.
Key characteristics:
- 200K context window
- Vision support via OpenAI-compatible API
- Mid-range pricing ($0.60/1M input tokens)
- Strong agentic capabilities
- Excellent for step-by-step reasoning
Model Specifications at a Glance
| Specification | DeepSeek Reasoner | Qwen3-Max | Kimi K2 Thinking |
|---|---|---|---|
| Provider | DeepSeek | Alibaba | Moonshot AI |
| Context Window | 128K | 262K | 200K |
| Vision Support | No | Yes | Yes |
| Input Cost (per 1M) | $0.14 | $1.20 | $0.60 |
| Output Cost (per 1M) | $0.42 | $6.00 | $2.50 |
| Cache Discount | ~90% | ~90% | ~90% |
| Latency Class | Medium | Medium | Medium |
| Reasoning Mode | Always-on | Optional | Always-on |
Cost analysis: DeepSeek Reasoner is approximately 9x cheaper than Qwen3-Max and 4x cheaper than Kimi K2 Thinking on input tokens. However, pricing doesn't tell the whole story—output quality, speed, and token efficiency matter equally.
The Comparison Test
We'll run the same complex prompt through all three models and compare:
- Response Speed - Time to first token and total completion time
- Token Usage - Input and output token counts
- Response Similarity - How similar are the responses to each other?
- Output Quality - Comprehensiveness, accuracy, and usefulness
The Test Prompt
We chose a multi-faceted business analysis question that requires:
- Strategic thinking
- Financial reasoning
- Technical understanding
- Risk assessment
A mid-sized e-commerce company (500 employees, $50M annual revenue) is considering
migrating from their monolithic architecture to microservices. They currently run
on-premise servers but are also evaluating cloud migration.
Analyze this decision considering:
1. Technical implications and migration complexity
2. Cost analysis (short-term investment vs long-term savings)
3. Team restructuring and skill requirements
4. Risk factors and mitigation strategies
5. Recommended phased approach
Provide a comprehensive executive summary with specific recommendations.
Step 1: Setting Up the Comparison
Navigate to AI Crucible Dashboard
- Go to the AI Crucible Dashboard
- Click on the prompt input area
- Select Comparative Analysis strategy—this runs all models in parallel for fair comparison
Select the Three Chinese Models
From the model selection panel, choose:
- DeepSeek Reasoner
- Qwen3-Max
- Kimi K2 Thinking
Tip: Deselect all other models to focus purely on the Chinese model comparison.
Configure Settings
- Rounds: 1 (for direct comparison)
- Arbiter Model: Any (for synthesis)
Click Run to start the comparison.
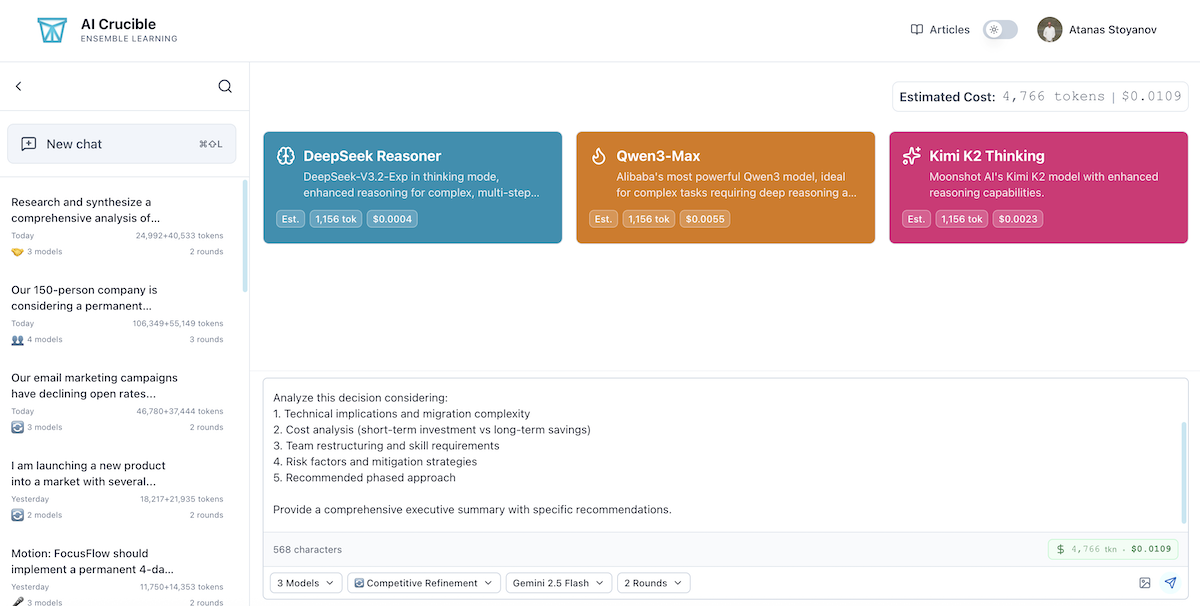
Comparison after 1 Round
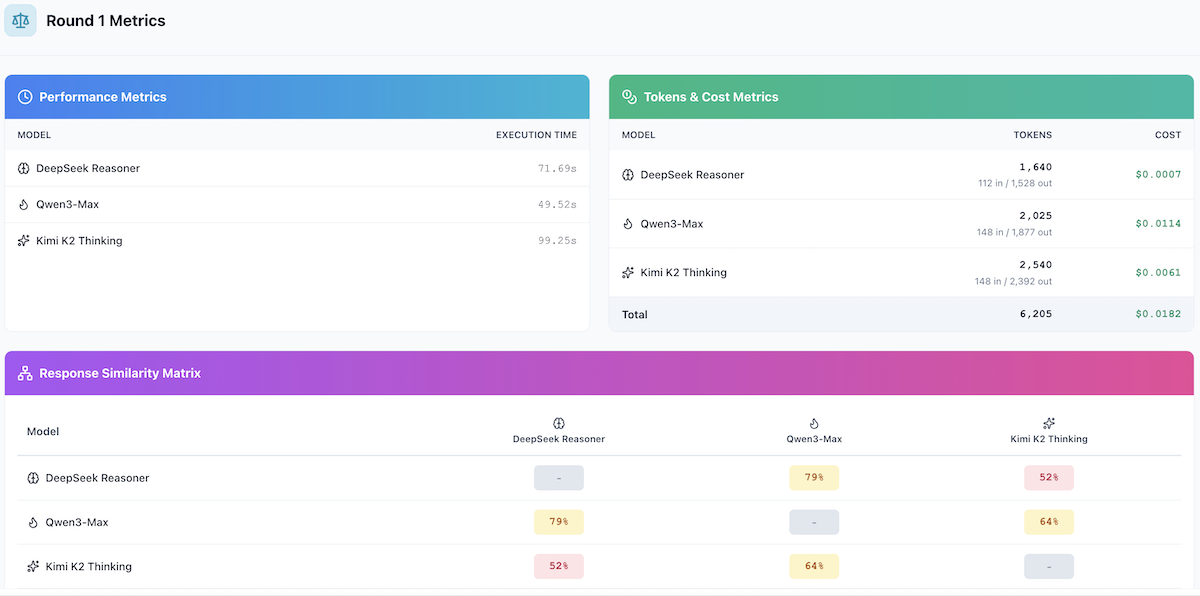
Step 2: Speed Comparison Results
Here's how each model performed on response speed:
Total Execution Time
| Model | Execution Time | Tokens/Second |
|---|---|---|
| Qwen3-Max | 49.52s | ~38 tok/s |
| DeepSeek Reasoner | 71.69s | ~21 tok/s |
| Kimi K2 Thinking | 99.25s | ~24 tok/s |
Key Observation: Qwen3-Max was the fastest model by a significant margin, completing in under 50 seconds—nearly half the time of Kimi K2 Thinking. DeepSeek Reasoner's thinking mode adds noticeable latency. The ~50 second difference between fastest and slowest is substantial and matters for time-sensitive applications.
Step 3: Token Usage Comparison
Token efficiency affects both cost and response comprehensiveness.
Input Token Processing
All models received the same prompt, but token counting varies by tokenizer:
| Model | Input Tokens | Notes |
|---|---|---|
| DeepSeek Reasoner | 112 | Most efficient tokenizer |
| Qwen3-Max | 148 | Standard encoding |
| Kimi K2 Thinking | 148 | Standard encoding |
Output Token Generation
| Model | Output Tokens | Total Tokens |
|---|---|---|
| DeepSeek Reasoner | 1,528 | 1,640 |
| Qwen3-Max | 1,877 | 2,025 |
| Kimi K2 Thinking | 2,392 | 2,540 |
Interesting finding: Kimi K2 Thinking produced the most verbose response (2,392 output tokens) despite being the slowest—suggesting it's doing more extensive reasoning rather than just being slow.
Total Cost per Response
| Model | Total Tokens | Total Cost |
|---|---|---|
| DeepSeek Reasoner | 1,640 | $0.0007 |
| Kimi K2 Thinking | 2,540 | $0.0061 |
| Qwen3-Max | 2,025 | $0.0114 |
| Combined Total | 6,205 | $0.0182 |
Cost Analysis: DeepSeek Reasoner is 16x cheaper than Qwen3-Max and 9x cheaper than Kimi K2 Thinking for this task. At scale, these differences compound significantly:
| Volume | DeepSeek | Kimi K2 | Qwen3-Max |
|---|---|---|---|
| 1,000 queries | $0.70 | $6.10 | $11.40 |
| 10,000 queries | $7.00 | $61.00 | $114.00 |
| 100,000 queries | $70.00 | $610.00 | $1,140.00 |
Step 4: Response Similarity Analysis
AI Crucible's similarity analysis reveals how much the models agree with each other. Higher similarity suggests convergent thinking; lower similarity indicates diverse perspectives.
Pairwise Similarity Scores
| Model Pair | Similarity | Interpretation |
|---|---|---|
| DeepSeek ↔ Qwen | 79% | High agreement |
| Qwen ↔ Kimi | 64% | Moderate agreement |
| DeepSeek ↔ Kimi | 52% | Different approaches |
Key Overlapping Themes (High Confidence)
All three models agreed on:
- Phased Migration Approach - All recommended a strangler fig pattern over big-bang migration
- Cost Trajectory - Short-term increase (18-24 months), long-term savings (30-40% reduction)
- Kubernetes Adoption - All suggested container orchestration as the foundation
- Team Training Priority - DevOps and cloud-native skills identified as critical gaps
Divergent Perspectives (Lower Agreement)
Models disagreed on:
| Topic | DeepSeek | Qwen3-Max | Kimi K2 |
|---|---|---|---|
| Timeline | 18 months | 24 months | 20 months |
| Initial Investment | $1.2M | $1.8M | $1.5M |
| First Service | Auth/Identity | Inventory | Order Processing |
| Cloud Provider | AWS | Multi-cloud | Hybrid initially |
Insight: The 52% similarity between DeepSeek and Kimi is notably low, suggesting these models approach problems quite differently. This makes them excellent candidates for ensemble strategies where diversity of thought adds value. Meanwhile, DeepSeek and Qwen show higher alignment (79%), indicating more convergent reasoning approaches.
Step 5: Output Quality Deep Dive
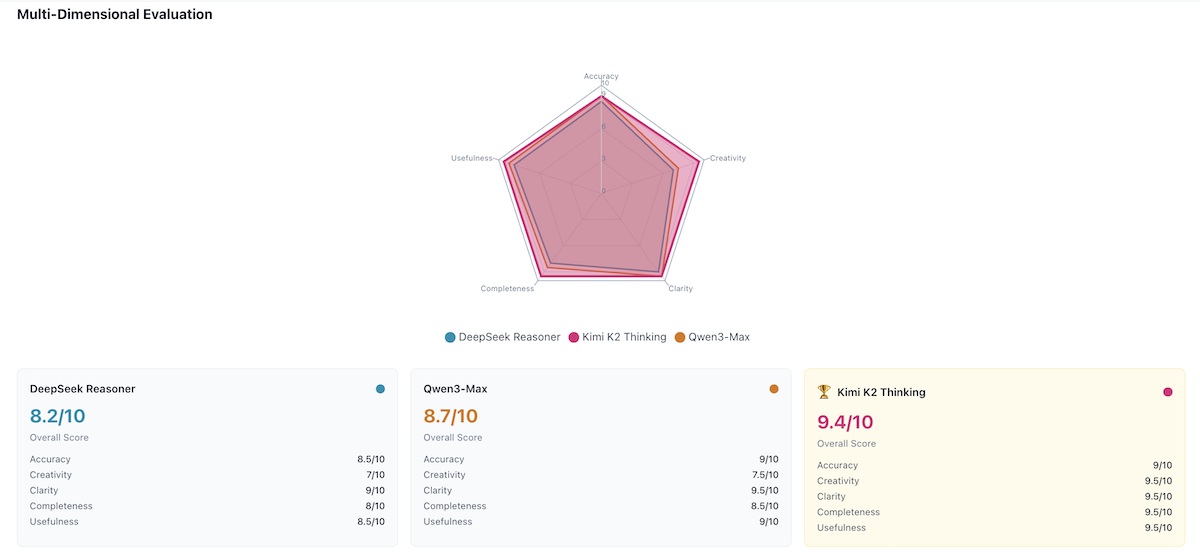
AI Crucible's arbiter model (Gemini 2.5 Flash) evaluated each response across five dimensions: Accuracy, Creativity, Clarity, Completeness, and Usefulness.
Multi-Dimensional Evaluation Scores
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| Kimi K2 Thinking | 9.4/10 | 9/10 | 9.5/10 | 9.5/10 | 9.5/10 | 9.5/10 |
| Qwen3-Max | 8.7/10 | 9/10 | 7.5/10 | 9.5/10 | 8.5/10 | 9/10 |
| DeepSeek Reasoner | 8.2/10 | 8.5/10 | 7/10 | 9/10 | 8/10 | 8.5/10 |
DeepSeek Reasoner Response (8.2/10)
Arbiter Evaluation:
"Model 1 provides a very solid, well-structured, and accurate response. It covers all aspects of the prompt comprehensively and presents a clear, logical phased approach. The executive summary is effective, and the recommendations are actionable. Its strength lies in its clarity and adherence to established best practices. It's less creative in its core recommendation compared to Model 3, offering a more conventional path, but its advice is sound and highly useful for a company embarking on this journey."
Strengths:
- Clear, well-structured overview of standard best practices
- Concise executive summary addressing strategic drivers
- Logical, easy-to-follow phased approach
- Frames budget as "3-year business transformation program" with "J-curve effect" on ROI
Weaknesses:
- Less creative—offers conventional path
- Lower creativity score (7/10) compared to others
Qwen3-Max Response (8.7/10)
Arbiter Evaluation:
"Model 2 excels in clarity and presentation, particularly with its effective use of tables for cost analysis and risk mitigation. This makes complex information very easy to digest and compare. The content is accurate and covers all prompt requirements thoroughly. Its recommendations are specific and actionable, emphasizing the importance of measuring business KPIs. While its core recommendation aligns with Model 1, the structured presentation adds a layer of practical utility and a touch more creativity in how the information is conveyed."
Strengths:
- Excellent use of tables for cost analysis and risk factors
- Specific percentage increases/reductions for cost
- Links cloud economics to variable e-commerce workloads
- Highly actionable recommendations including business KPI tracking
Weaknesses:
- Core recommendation aligns with conventional approach
- Creativity could be higher (7.5/10)
Kimi K2 Thinking Response (9.4/10)
Arbiter Evaluation:
"Model 3 stands out for its highly pragmatic, contrarian, and detailed approach. Its core recommendation to avoid a full microservices rewrite for a mid-sized company, instead focusing on a 'Cloud-First Modular Architecture' with strategic extraction, is a highly creative and realistic perspective. The depth of its cost analysis, including specific ranges and categories, 'Hidden Dangers,' 'Kill Criteria,' and 'Go/No-Go Decision Criteria,' provides exceptional practical value. It covers all prompt requirements with an extraordinary level of detail and actionable advice, making it exceptionally useful for decision-makers. The clarity and structure are excellent despite the extensive information."
Strengths:
- Contrarian approach: Recommends against full microservices migration
- Proposes "Cloud-First Modular Architecture" with limited, strategic extraction
- Unparalleled detail: specific financial estimates ($800K-$1.2M investment, 24-30 month ROI)
- Includes "Hidden Dangers," "Kill Criteria," and "Go/No-Go Decision Criteria"
- Detailed cost breakdown per category (talent, productivity loss, tooling)
- Recommends extracting only 2-3 critical services based on "pain × value" matrix
Weaknesses:
- Slowest execution time (99.25s)
- May be overwhelming for simple queries
Step 6: Comparative Analysis Results
Core Similarities Across All Models
Despite different approaches, all three models agreed on key fundamentals:
- Phased Approach: All strongly advocate for incremental migration using the "Strangler Fig" pattern—avoiding a risky "big bang" rewrite
- Cloud Adoption: All recommend cloud migration (AWS or Azure) for scalability, agility, and OpEx benefits
- Team Transformation: Consensus on moving from functional silos to cross-functional, domain-aligned teams
- Observability: All emphasize robust logging, monitoring, and tracing for distributed systems
- Risk Acknowledgment: All acknowledge high complexity and significant investment requirements
Key Differentiators
| Aspect | DeepSeek Reasoner | Qwen3-Max | Kimi K2 Thinking |
|---|---|---|---|
| Core Stance | Full microservices future | Careful orchestration | "Hybrid Evolution, Not Revolution" |
| Presentation | Clear narrative | Tables & structured data | Detailed pragmatic analysis |
| Unique Value | J-curve ROI framing | Business KPI tracking | Kill Criteria & Go/No-Go gates |
| Risk Approach | Standard mitigations | Tabular risk matrix | Hidden Dangers section |
Arbiter's Synthesized Recommendation
The arbiter (Gemini 2.5 Flash) synthesized insights from all three models into a unified recommendation:
For a mid-sized e-commerce company with $50M annual revenue, the pragmatic approach championed by Kimi K2 Thinking (Model 3) offers the most realistic path forward.
The synthesized "Cloud-First Modular Architecture" strategy:
- Phase 1 - Cloud Migration First: Containerize and migrate the monolith to cloud (AWS/Azure) before attempting microservices
- Phase 2 - Strategic Extraction: Extract only 2-3 high-value services (Payment, Inventory, Product Catalog) into true microservices
- Modularize Internally: For remaining code, focus on internal modularization without distributed deployment overhead
- Invest in Platform Team: Build foundational infrastructure, CI/CD, and observability
- Rigorous Management: Implement Kill Criteria and Go/No-Go gates to prevent overruns
- People First: Invest in upskilling and DevOps culture before restructuring teams
This balances innovation with pragmatism—achieving microservices benefits with manageable risk for a mid-sized company.
Step 7: Practical Recommendations
Based on the comparative analysis, here's what we learned:
When to Choose Each Model
Choose DeepSeek Reasoner (8.2/10) When:
Cost is the primary constraint - At $0.0007 per query, it's 16x cheaper than Qwen3-Max
Standard best practices are sufficient - Solid, well-structured, conventional approach
You need explicit reasoning chains - The thinking mode shows its work
Avoid when: You need creative/contrarian perspectives (7/10 creativity) or vision capabilities
Choose Qwen3-Max (8.7/10) When:
Speed matters - Fastest at 49.52s (nearly 2x faster than Kimi)
Clear presentation is key - Excellent use of tables for cost analysis and risk mitigation
Business KPI tracking needed - Strong on actionable recommendations with metrics
Vision/multimodal is needed - Supports image inputs unlike DeepSeek
Avoid when: Cost is constrained ($0.0114/query) or you need unconventional insights
Choose Kimi K2 Thinking (9.4/10) When:
Quality is paramount - Highest overall score with 9.5/10 on creativity, completeness, usefulness
Contrarian perspectives needed - Willing to challenge conventional wisdom
Decision-critical analysis - Includes "Kill Criteria," "Hidden Dangers," and Go/No-Go gates
Practical, actionable depth - Extraordinary level of detail for decision-makers
Avoid when: Speed is critical (slowest at 99s) or you need maximum conciseness
Ensemble Strategy: Combining All Three
The real power emerges when you use these models together. Based on our similarity analysis, a Chinese model ensemble offers meaningful diversity (52-79% similarity range) while maintaining quality. The low 52% similarity between DeepSeek and Kimi is particularly valuable for ensemble strategies.
Recommended Ensemble Configuration
For business analysis tasks like our example:
Round 1: Parallel generation from all three models
Round 2: Models review and critique each other's responses
Round 3: Synthesis by Qwen3-Max (most comprehensive)
Estimated cost: ~$0.04-0.06 for 3 rounds
For technical tasks (coding, architecture):
Primary: DeepSeek Reasoner (technical depth)
Reviewer: Kimi K2 Thinking (practical perspective)
Synthesizer: DeepSeek Reasoner (cost-effective)
Estimated cost: ~$0.02-0.04 for 3 rounds
For multimodal tasks (with images/documents):
Primary: Qwen3-Max (best vision)
Alternative: Kimi K2 Thinking (vision support)
Note: DeepSeek Reasoner excluded (no vision)
Estimated cost: ~$0.03-0.05 for 3 rounds
Benchmark Summary
| Metric | DeepSeek Reasoner | Qwen3-Max | Kimi K2 Thinking | Winner |
|---|---|---|---|---|
| Overall Quality | 8.2/10 | 8.7/10 | 9.4/10 | Kimi |
| Speed (Total) | 71.69s | 49.52s | 99.25s | Qwen |
| Cost | $0.0007 | $0.0114 | $0.0061 | DeepSeek |
| Output Length | 1,528 tokens | 1,877 tokens | 2,392 tokens | Kimi |
Quality Ratings
| Metric | DeepSeek Reasoner | Qwen3-Max | Kimi K2 Thinking | Winner |
|---|---|---|---|---|
| Accuracy | 8.5/10 | 9/10 | 9/10 | Qwen/Kimi |
| Creativity | 7/10 | 7.5/10 | 9.5/10 | Kimi |
| Clarity | 9/10 | 9.5/10 | 9.5/10 | Qwen/Kimi |
| Completeness | 8/10 | 8.5/10 | 9.5/10 | Kimi |
| Usefulness | 8.5/10 | 9/10 | 9.5/10 | Kimi |
| Vision Support | No | Yes | Yes | Qwen/Kimi |
Key Takeaways
1. Kimi K2 Thinking Wins on Quality (9.4/10)
Despite being the slowest model (99.25s), Kimi K2 Thinking produced the highest quality response with a contrarian, pragmatic approach. Its "Cloud-First Modular Architecture" recommendation was deemed most realistic for a mid-sized company. Lesson: Speed ≠ quality.
2. Each Model Has a Clear Strength
| Priority | Best Choice | Why |
|---|---|---|
| Quality | Kimi K2 Thinking | 9.4/10 overall, most creative |
| Speed | Qwen3-Max | 49.52s (2x faster than Kimi) |
| Cost | DeepSeek Reasoner | $0.0007 (16x cheaper than Qwen) |
3. Creativity Is the Key Differentiator
The biggest quality gap was in Creativity: Kimi scored 9.5/10 while DeepSeek scored 7/10. Kimi's willingness to challenge conventional wisdom ("avoid full microservices") set it apart.
4. Chinese Models Are World-Class
All three models scored 8.2+ out of 10, with the winner (Kimi) achieving 9.4/10. These are not "budget alternatives"—they're genuine competitors to Western models, often at a fraction of the cost.
5. Diversity Enables Better Ensembles
The 52-79% similarity range creates excellent ensemble dynamics. DeepSeek and Qwen aligned closely (79%), while DeepSeek and Kimi diverged significantly (52%). This means combining them captures both consensus and diverse perspectives.
6. Cost Differences Are Dramatic
DeepSeek costs 16x less than Qwen3-Max per query. At 100K queries: $70 vs $1,140. Even against Kimi ($610), DeepSeek offers massive savings for budget-constrained applications.
Frequently Asked Questions
Which Chinese AI model is the best in 2026?
In our benchmark, Kimi K2 Thinking scored highest at 9.4/10 overall, beating Qwen3-Max (8.7) and DeepSeek Reasoner (8.2). Kimi excelled in creativity (9.5/10) and completeness (9.5/10), delivering a contrarian "Cloud-First Modular Architecture" recommendation that judges called the most realistic approach for mid-sized companies. However, "best" depends on your priorities — DeepSeek wins on cost and Qwen wins on speed.
How much do Chinese AI models cost compared to GPT and Claude?
Chinese AI models are dramatically cheaper. DeepSeek Reasoner costs $0.14/1M input tokens — roughly 36x cheaper than Claude Opus 4.5 ($5.00) and 9x cheaper than GPT-5.1 ($1.25). Even the most expensive Chinese model tested, Qwen3-Max at $1.20/1M input, is still 4x cheaper than Claude. At 100K queries, DeepSeek costs $70 versus $1,140 for Qwen3-Max.
Is DeepSeek better than Qwen for coding tasks?
DeepSeek Reasoner is generally preferred for coding and math tasks due to its always-on chain-of-thought reasoning mode and MoE architecture optimized for technical analysis. It scored 8.5/10 on accuracy in our benchmark. However, Qwen3-Max offers vision support for understanding code screenshots and diagrams, which DeepSeek lacks. For pure code generation at minimum cost, DeepSeek at $0.0007 per query is the clear winner.
Can Chinese AI models replace Western models like GPT-5 and Claude?
Yes, for many use cases. All three Chinese models scored 8.2+ out of 10, with Kimi K2 Thinking achieving 9.4/10 — competitive with Western flagship models. The 52-79% response similarity range shows they approach problems differently from each other, making them excellent for ensemble strategies. The main limitations are that DeepSeek lacks vision support and all three models may have lower English fluency in highly nuanced cultural contexts.
What is the best Chinese AI model for enterprise use?
For enterprise deployments, the choice depends on requirements: Kimi K2 Thinking (9.4/10 quality, $0.0061/query) for decision-critical analysis with its unique "Kill Criteria" and Go/No-Go frameworks; DeepSeek Reasoner ($0.0007/query) for high-volume technical tasks where cost efficiency is paramount; Qwen3-Max (49.52s response time) when speed and multimodal support are priorities. Combining all three in an ensemble configuration costs approximately $0.02 per session and captures diverse perspectives.
Try It Yourself
Ready to run your own comparison? Here's a quick start:
- Go to AI Crucible Dashboard
- Select: DeepSeek Reasoner, Qwen3-Max, Kimi K2 Thinking
- Choose Strategy: Comparative Analysis or Expert Panel
- Enter your prompt and click Run
- Analyze: Review speed, tokens, similarity, and quality
Suggested test prompts:
- "Design a recommendation system for an e-commerce platform with 1M daily users"
- "Explain quantum computing to a 10-year-old, then to a physics PhD student"
- "Create a 12-month product roadmap for a B2B SaaS startup in the HR space"
Related Articles
- LLM Landscape 2025: Choosing the Right AI Model - Compare Chinese models to Western alternatives
- Seven Ensemble Strategies Explained - Learn how to combine models effectively
- Cost and Token Optimizations - Maximize value from your AI spend
- Getting Started Guide - New to AI Crucible? Start here
Methodology Notes
Test conditions:
- All tests run on AI Crucible production infrastructure
- Streaming responses enabled for all models
- Same prompt used for all models
- Results represent single runs (your results may vary)
- Costs calculated using official API pricing as of December 1st 2025
Metrics explained:
- Execution Time: Total time from request to complete response
- Similarity: Cosine similarity of response embeddings
- Token counts: Reported by each provider's API
Note: These metrics reflect actual test results from December 2025. Your results may vary based on API load, prompt complexity, and other factors.