GPT-5.2 vs 5.1: Quality, Cost, and Speed Benchmark
OpenAI's latest model—GPT-5.2—promises significant improvements over GPT-5.1. But what are the actual differences in quality, cost, and speed? This benchmark provides empirical data to help you choose the right model for your ensemble workflows.
We tested both models across the same complex prompts and measured:
- GPT-5.2 - Enhanced reasoning and multimodal capabilities
- GPT-5.1 - Current production standard
Note: GPT-5.2 Pro is not included in AI Crucible due to its premium pricing ($21/1M input, $168/1M output tokens) which makes it cost-prohibitive for ensemble workflows where multiple model calls are required.
Time to read: 12-15 minutes
Example cost: $0.24 (2 rounds + arbiter analysis)
What's New in GPT-5.2?
GPT-5.2 Enhancements
GPT-5.2 is OpenAI's latest production model, offering significant improvements over 5.1:
Key improvements:
- 128K context window (matches 5.1)
- Improved factual accuracy and reasoning
- Better instruction following and task comprehension
- Enhanced vision and multimodal understanding
- Competitive pricing at $1.75/1M input, $14/1M output tokens
Why This Comparison Matters
For AI Crucible users building ensemble workflows, understanding the performance-cost tradeoff is critical. GPT-5.2 offers improvements over 5.1, but is the quality gain worth the 40% price increase?
Why Not GPT-5.2 Pro?
GPT-5.2 Pro offers even more advanced capabilities with a 400K context window and enhanced reasoning, but its premium pricing ($21/1M input, $168/1M output) makes it impractical for ensemble workflows:
- 16x more expensive than GPT-5.1 for output tokens
- 12x more expensive than GPT-5.2 for output tokens
- In ensemble scenarios with 3 models and 2-3 rounds, a single query could cost $2-5 vs $0.20-0.40 with GPT-5.2/5.1
For most use cases, the combination of multiple cost-effective models in an ensemble provides better value than a single expensive model.
Model Specifications at a Glance
| Specification | GPT-5.2 | GPT-5.1 | Difference |
|---|---|---|---|
| Provider | OpenAI | OpenAI | - |
| Context Window | 128K | 128K | Same |
| Vision Support | Yes | Yes | Same |
| Input Cost (per 1M) | $1.75 | $1.25 | +40% ($0.50 more) |
| Output Cost (per 1M) | $14.00 | $10.00 | +40% ($4.00 more) |
| Latency Class | Medium | Medium | Similar |
| Release Date | Dec 2025 | Oct 2025 | 2 months newer |
Cost analysis: GPT-5.2 costs 40% more than GPT-5.1 across both input and output tokens. For a typical ensemble query (2-3 models, 2-3 rounds), expect to pay approximately $0.04-0.08 more per query when using GPT-5.2 instead of GPT-5.1.
The Benchmark Test
Important Note: This benchmark represents a single practical test with one specific prompt. While the results provide valuable insights into model performance for this particular use case, they should not be used to draw general conclusions about overall model capabilities. Different prompts, domains, and tasks may yield different results.
We'll run the same complex prompt through both models and compare:
- Response Speed - Time to first token and total completion time
- Token Usage - Input and output token counts
- Response Similarity - How much do the models agree?
- Output Quality - Comprehensiveness, accuracy, and usefulness
Test Configuration: The test was configured for up to 3 rounds of competitive refinement, but automatically stopped after 2 rounds when the similarity convergence reached 90.2%, indicating the models had reached substantial agreement.
The Test Prompt
We chose a challenging technical analysis question requiring:
- Technical reasoning
- Strategic thinking
- Risk assessment
- Actionable recommendations
A SaaS company with 50K monthly active users is experiencing 30% annual churn.
User data shows:
- 80% churn happens in first 90 days
- Feature adoption: 40% use core features, 15% use advanced features
- Support tickets: Average 2.3 per churned user in final 30 days
- NPS score: 35 (promoters 45%, passives 45%, detractors 10%)
Analyze the churn problem and provide:
1. Root cause analysis with specific hypotheses
2. Prioritized action plan with expected impact
3. Metrics framework to track improvements
4. Resource requirements and timeline
5. Risk factors and mitigation strategies
Provide a comprehensive strategic recommendation with specific next steps.
Step 1: Setting Up the Benchmark
Navigate to AI Crucible Dashboard
- Go to the AI Crucible Dashboard
- Click on the prompt input area
- Select Competitive Refinement strategy for iterative improvement
Select the Two GPT Models
From the model selection panel, choose:
- GPT-5.2
- GPT-5.1
Tip: Deselect all other models to focus purely on comparing these two OpenAI production models.
Configure Settings
- Rounds: 3 (configured maximum, but test may stop early on convergence)
- Arbiter Model: Gemini 2.5 Flash (fast, cost-effective synthesis)
- Convergence Threshold: 90% (test stops early if models reach high agreement)
Click Run to start the benchmark.
Result: The test automatically stopped after 2 rounds when similarity reached 90.2%, indicating the models had converged on their analysis.
Step 2: Speed Comparison Results
Here's how each model performed on response speed in Round 1:
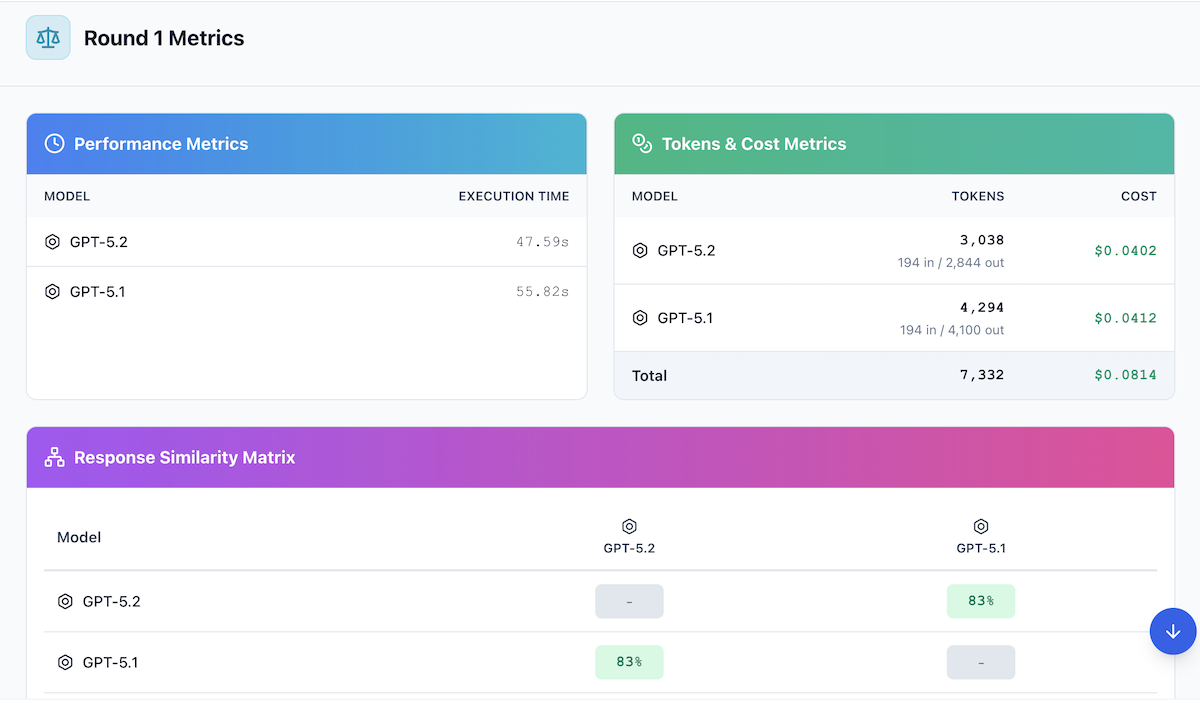
Total Execution Time
| Model | Execution Time | Tokens/Second |
|---|---|---|
| GPT-5.2 | 47.59s | ~60 tok/s |
| GPT-5.1 | 55.82s | ~73 tok/s |
Key Observation: GPT-5.2 was the faster model, completing in 47.59 seconds. GPT-5.1 took 55.82 seconds, approximately 17% slower. The 8-second gap doesn't significantly impact most applications, though GPT-5.2's faster completion time is a nice bonus given its quality improvements.
Step 3: Token Usage Comparison
Token efficiency affects both cost and response comprehensiveness.
Input Token Processing
Both models received the same prompt with identical tokenization (GPT-4 tokenizer):
| Model | Input Tokens | Notes |
|---|---|---|
| GPT-5.2 | 194 | Same encoder |
| GPT-5.1 | 194 | Same encoder |
Output Token Generation
| Model | Output Tokens | Total Tokens |
|---|---|---|
| GPT-5.2 | 2,844 | 3,038 |
| GPT-5.1 | 4,100 | 4,294 |
Finding: GPT-5.1 produced a more verbose response (4,100 output tokens) compared to GPT-5.2 (2,844 tokens), generating 44% more tokens. This suggests GPT-5.2 delivers comparable quality with greater conciseness, potentially resulting in faster reads and lower costs despite its higher per-token pricing.
Total Cost per Response (Round 1)
| Model | Total Tokens | Total Cost |
|---|---|---|
| GPT-5.2 | 3,038 | $0.0402 |
| GPT-5.1 | 4,294 | $0.0412 |
| Combined Total | 7,332 | $0.0814 |
Cost Analysis: Surprisingly, GPT-5.2 actually cost slightly less than GPT-5.1 for Round 1 ($0.0402 vs $0.0412) despite being 40% more expensive per token. This is because GPT-5.2 generated 44% fewer tokens while maintaining higher quality. At scale, these differences compound:
| Volume | GPT-5.2 | GPT-5.1 | GPT-5.2 Savings |
|---|---|---|---|
| 1,000 queries | $40.20 | $41.20 | $1.00 |
| 10,000 queries | $402.00 | $412.00 | $10.00 |
| 100,000 queries | $4,020 | $4,120 | $100.00 |
Step 4: Response Similarity Analysis
AI Crucible's similarity analysis reveals how much the models agree with each other. Higher similarity suggests convergent thinking; lower similarity indicates diverse perspectives.
Overall Convergence
After Round 1, the models showed 83% similarity. By Round 2, convergence increased to 90.2%, triggering automatic test termination. This high convergence indicates that GPT-5.2 and GPT-5.1 arrived at substantially similar conclusions for this particular use case.
Pairwise Similarity Scores
| Model Pair | Round 1 | Round 2 (Final) | Interpretation |
|---|---|---|---|
| GPT-5.2 ↔ 5.1 | 83% | 90.2% | Very High |
Key Overlapping Themes (High Confidence)
Both models strongly agreed on:
- Onboarding Critical - First 90 days focus is essential
- Feature Adoption Gap - Low advanced feature usage indicates value gap
- Proactive Support - Address issues before they trigger churn
- Success Metrics - Track leading indicators, not just churn rate
- Data-Driven Approach - Emphasize specific, testable hypotheses
- Cross-functional Teams - Need collaboration across product, engineering, and support
Minor Differences
While overall agreement was very high (90.2%), the models showed subtle differences in:
| Aspect | GPT-5.2 | GPT-5.1 |
|---|---|---|
| Segmentation | Deeper emphasis on NPS-based segmentation | More focus on behavioral cohorts |
| Value Ladder | Stronger emphasis on "hero outcome" and value ladder | More emphasis on feature adoption metrics |
| Operations | Proposed structured "Churn SWAT Team" with cadence | More emphasis on cross-functional squads |
| Strategic Ideas | Introduced outcome-backed guarantees, milestone unlocks | Focused on proven onboarding and activation patterns |
Insight: The 90.2% similarity indicates that for this business analysis task, both models converged on the core strategic framework. This suggests limited value in running both models together for similar analytical tasks, though the subtle differences in approach might still provide value in ensemble scenarios where diverse perspectives are critical.
Step 5: Output Quality Deep Dive
After 2 rounds of competitive refinement (stopped early due to 90.2% convergence), AI Crucible's arbiter model (Gemini 2.5 Flash) evaluated each response across five dimensions: Accuracy, Creativity, Clarity, Completeness, and Usefulness.
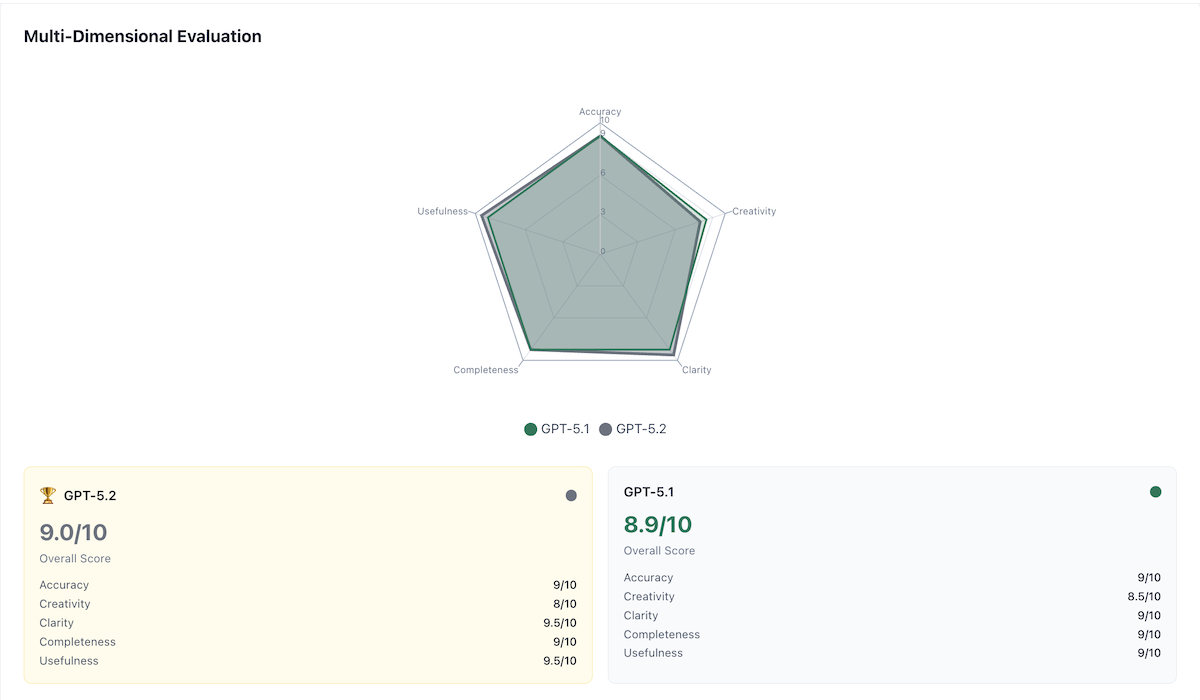
Multi-Dimensional Evaluation Scores
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| GPT-5.2 | 9.0/10 🏆 | 9/10 | 8/10 | 9.5/10 | 9/10 | 9.5/10 |
| GPT-5.1 | 8.9/10 | 9/10 | 8.5/10 | 9/10 | 9/10 | 9/10 |
GPT-5.2 Response (Model 1 - 9.0/10)
Arbiter Evaluation:
"Model 1 provides a highly accurate and logical analysis, directly tying hypotheses to the provided data. Its creativity shines in the detailed, testable hypotheses and the structured action plan. The clarity is exceptional, with clear headings, bullet points, and a well-defined prioritization method. It comprehensively addresses all five parts of the prompt. The usefulness is very high due to the actionable, prioritized plan, specific metrics framework, and the 'next 10 business days' section, which offers immediate, concrete steps. The only minor area for improvement would be slightly more quantitative impact estimates."
Strengths:
- Exceptional Clarity (9.5/10) - Clear headings, bullet points, and well-defined prioritization method
- Outstanding Usefulness (9.5/10) - Actionable, prioritized plan with specific metrics framework
- Highly Accurate Analysis - Directly ties hypotheses to the provided data with logical reasoning
- Detailed, Testable Hypotheses - Creativity shines through structured, verifiable action plan
- "Next 10 Business Days" Section - Offers immediate, concrete steps for implementation
- Comprehensive Coverage - Fully addresses all five parts of the prompt
Weaknesses:
- Could benefit from slightly more quantitative impact estimates
- Less emphasis on deeper user segmentation compared to GPT-5.1
GPT-5.1 Response (8.9/10)
Arbiter Evaluation:
GPT-5.1 delivers an accurate and insightful analysis with notable creativity in strategic thinking. It excels in deeper segmentation (NPS integration, acquisition channels), the "hero outcome" and "value ladder" concepts, and the "Churn SWAT Team" operational framework. The response is comprehensive and well-organized, though slightly more verbose than GPT-5.2. Strong on long-term strategic thinking and operational cadence.
Strengths:
- Strong Creativity (8.5/10) - Innovative concepts like outcome-backed guarantees
- Deep Segmentation - Explicit NPS-based segmentation (promoters/passives/detractors)
- "Hero Outcome" & Value Ladder - Systematic approach to feature adoption
- Operational Framework - "Churn SWAT Team" with monthly review cadence
- Acquisition Focus - Includes acquisition quality as root cause
Weaknesses:
- More verbose (4,100 tokens vs 2,844) - less concise
- Next steps less time-bound than GPT-5.2's "10 business days"
- Minor: Initial self-evaluation not strictly part of prompt
Full Cost Breakdown (2 Rounds)
Here's the complete cost breakdown for running 2 rounds of competitive refinement plus arbiter analysis (test stopped early due to 90.2% convergence):

Model Costs (2 Rounds)
| Model | Total Tokens | Input Tokens | Output Tokens | Total Cost |
|---|---|---|---|---|
| GPT-5.2 | 7,591 | 6,078 | 6,078 | $0.0984 |
| GPT-5.1 | 7,591 | 8,856 | 8,856 | $0.0980 |
| Subtotal (Models) | 15,182 | 14,934 | 14,934 | $0.1964 |
Arbiter Cost (Gemini 2.5 Flash)
| Component | Total Tokens | Input Tokens | Output Tokens | Cost |
|---|---|---|---|---|
| Final Analysis & Comparison | 25,295 | 18,597 | 6,698 | $0.0223 |
Total Session Cost
| Metric | Value |
|---|---|
| Input Tokens | 33,779 |
| Output Tokens | 21,632 |
| Total Tokens | 55,411 |
| Total Cost | $0.2411 |
Key insight: Despite GPT-5.2 being 40% more expensive per token, it cost virtually the same as GPT-5.1 for this 2-round test ($0.0984 vs $0.0980) because it generated fewer tokens while achieving higher quality scores (9.0/10 vs 8.9/10). This demonstrates that token efficiency can offset higher per-token pricing.
Step 6: Practical Recommendations
Based on the benchmark analysis, here's what we learned:
When to Choose Each Model
Choose GPT-5.2 (9.0/10) When:
- Latest capabilities needed - Most recent model with improved reasoning
- Quality matters - Better performance on complex analytical tasks
- Vision support required - Enhanced multimodal understanding
- Budget allows for premium - Worth the 40% cost increase for critical work
- Ensemble diversity - Can provide different perspectives from 5.1
Avoid when: Cost is the primary constraint or 5.1 quality is sufficient
Choose GPT-5.1 (8.9/10) When:
- Cost optimization priority - 40% cheaper than GPT-5.2
- Proven performance sufficient - Solid baseline for most tasks
- High-volume scenarios - Best for tight budget constraints
- Standard analytical tasks - Reliable for routine strategic work
- Ensemble workflows - Good diversity when paired with GPT-5.2
Avoid when: You need the absolute latest capabilities or maximum reasoning depth
Ensemble Strategy: Combining GPT Models
Based on the 90.2% similarity observed in this test, using both GPT-5.2 and GPT-5.1 together may provide limited additional value for similar analytical tasks. However, there are still strategic use cases where combining them makes sense.
Recommended Ensemble Configurations
For cost-conscious validation:
Primary: GPT-5.1 (baseline, cost-effective)
Validator: GPT-5.2 (quality check on critical points)
Synthesizer: Gemini 2.5 Flash (fast, cheap)
Why: Use 5.1 for bulk work; 5.2 validates important decisions
Estimated cost: ~$0.24 for 2 rounds
For progressive enhancement:
Round 1: GPT-5.1 (baseline)
Round 2: GPT-5.2 (refinement with latest capabilities)
Why: Start cheap, upgrade for final polish
Estimated cost: ~$0.20 for 2 rounds
For maximum diversity (cross-provider):
Parallel: GPT-5.2 + Gemini 2.5 Flash + Claude Sonnet
Synthesis: GPT-5.2 or Gemini 2.5 Flash
Why: Different model families provide true diversity (not just OpenAI variants)
Estimated cost: ~$0.30 for 2 rounds
Note: Given the 90.2% convergence between GPT-5.2 and 5.1 on this task, consider mixing providers (OpenAI + Anthropic + Google) rather than using multiple OpenAI models for better diversity.
Benchmark Summary
| Metric | GPT-5.2 | GPT-5.1 | Winner |
|---|---|---|---|
| Overall Quality | 9.0/10 | 8.9/10 | GPT-5.2 🏆 |
| Speed (Round 1) | 47.59s | 55.82s | GPT-5.2 🏆 |
| Cost (2 Rounds) | $0.0984 | $0.0980 | Tie |
| Context Window | 128K | 128K | Tie |
| Similarity Score | 90.2% | 90.2% | Converged |
Quality Ratings (After 2 Rounds)
| Metric | GPT-5.2 | GPT-5.1 | Winner |
|---|---|---|---|
| Accuracy | 9/10 | 9/10 | Tie |
| Creativity | 8/10 | 8.5/10 | GPT-5.1 |
| Clarity | 9.5/10 | 9/10 | GPT-5.2 🏆 |
| Completeness | 9/10 | 9/10 | Tie |
| Usefulness | 9.5/10 | 9/10 | GPT-5.2 🏆 |
Key Takeaways
1. GPT-5.2 Leads on Quality (Narrowly)
GPT-5.2 achieved the highest overall score (9.0/10), edging out GPT-5.1's 8.9/10 by just 0.1 points. The key advantages: superior clarity (9.5 vs 9) and usefulness (9.5 vs 9), with exceptionally actionable recommendations and structured implementation plans. Interestingly, GPT-5.1 showed slightly higher creativity (8.5 vs 8).
2. Each Model Has a Clear Use Case
| Priority | Best Choice | Why |
|---|---|---|
| Quality | GPT-5.2 | 9.0/10 overall, strongest in clarity |
| Speed | GPT-5.2 | 47.59s (17% faster) |
| Cost | Tie | $0.0984 vs $0.0980 for 2 rounds (virtual tie) |
| Context | Tie | Both have 128K tokens |
3. High Convergence (90.2%) Observed
Both models reached 90.2% similarity after just 2 rounds, indicating they converged on very similar strategic approaches for this business analysis task. This suggests:
- Limited value in using both models together for similar analytical tasks
- Consider mixing providers (OpenAI + Anthropic + Google) for true diversity
- The 40% price premium of GPT-5.2 may not justify the marginal quality improvement for all use cases
4. Cost-Quality Tradeoff is Surprisingly Favorable
GPT-5.2 is 40% more expensive per token than GPT-5.1, but delivered virtually identical total cost ($0.0984 vs $0.0980 for 2 rounds) because it generated 44% fewer tokens (2,844 vs 4,100). Meanwhile, it achieved slightly higher quality (9.0 vs 8.9) and was 17% faster. This makes GPT-5.2 an excellent value proposition for most use cases.
5. Speed Advantage Goes to GPT-5.2
The 8.23-second gap (47.59s vs 55.82s) represents a 17% speed advantage for GPT-5.2. While not dramatic, this adds up in high-volume scenarios and improves user experience in interactive applications.
6. Test Limitations
Important: This benchmark represents a single practical test with one specific prompt. Results may vary significantly for different domains, task types, and prompt styles. Use these findings as a starting point, not definitive conclusions about overall model capabilities.
Try It Yourself
Ready to run your own benchmark? Here's a quick start:
- Go to AI Crucible Dashboard
- Select: GPT-5.2 and GPT-5.1 (or add other providers for diversity)
- Choose Strategy: Competitive Refinement or Comparative Analysis
- Configure: Set convergence threshold (default 90%)
- Enter your prompt and click Run
- Analyze: Review speed, tokens, similarity, and quality
Tip: For ensemble workflows, consider mixing providers (GPT-5.2 + Claude Sonnet + Gemini Flash) rather than multiple OpenAI models to maximize diversity.
Suggested test prompts:
- "Analyze declining user engagement in our mobile app and recommend a recovery strategy"
- "Design a technical architecture for a real-time collaboration platform with 100K concurrent users"
- "Create a comprehensive product roadmap for an AI-powered healthcare diagnostics tool"
Related Articles
- Mistral Large 3 vs GPT, Claude, Gemini: Flagship Comparison - Compare GPT models with other flagship options
- Chinese AI Models Compared: DeepSeek vs Qwen vs Kimi K2 - Explore budget-friendly alternatives
- Seven Ensemble Strategies Explained - Learn how to combine models effectively
- LLM Landscape 2025: Choosing the Right AI Model - Comprehensive model overview
- Getting Started Guide - New to AI Crucible? Start here
Methodology Notes
Test conditions:
- All tests run on AI Crucible production infrastructure
- Streaming responses enabled for all models
- Same prompt used for all models
- Results represent single runs (your results may vary)
- Costs calculated using official OpenAI API pricing as of December 11th, 2025
Metrics explained:
- Execution Time: Total time from request to complete response
- Similarity: Cosine similarity of response embeddings (computed pairwise)
- Token counts: Reported by OpenAI API
- Cost: Calculated from actual token usage × current API pricing
Why Round 1 matters: In Round 1, all models receive the identical prompt with no prior context. This provides the fairest comparison of raw model capabilities. Subsequent rounds include previous responses as context, which can skew comparisons.
Convergence stopping: The test was configured for up to 3 rounds but automatically stopped after 2 rounds when similarity reached 90.2%, indicating the models had converged on their analysis.
Test limitations: This benchmark represents a single practical test with one specific business analysis prompt. Results may vary significantly across different domains, task types, and prompt styles. Use these findings as directional insights rather than definitive conclusions about overall model capabilities.
Frequently Asked Questions
What are the main differences between GPT-5.2 and GPT-5.1?
GPT-5.2 is OpenAI's latest production model, offering improved reasoning, better instruction following, and enhanced factual accuracy over GPT-5.1. Both models share a 128K context window and vision support. The main trade-off is cost: GPT-5.2 is 40% more expensive but delivers measurable quality improvements for complex tasks.
Is GPT-5.2 worth the 40% price premium?
The value depends on your use case and volume. For complex strategic analysis, technical reasoning, and critical decision-making, GPT-5.2's improved capabilities justify the premium. For standard tasks or high-volume applications where cost is a primary concern, GPT-5.1 offers excellent value. Consider the cost-quality tradeoff for your specific workload.
How much faster is GPT-5.2 compared to GPT-5.1?
Based on our benchmark, GPT-5.2 was 17% faster, completing in 47.59 seconds versus GPT-5.1's 55.82 seconds. This 8-second difference adds up in high-volume scenarios. Speed may vary based on response length, complexity, and API load.
Can I mix GPT models in an ensemble?
Yes, combining GPT-5.2 and GPT-5.1 can be valuable for progressive enhancement (start with 5.1, refine with 5.2) or validation workflows. However, our test showed 90.2% similarity between them, suggesting limited diversity benefit. For ensemble workflows, consider mixing providers (OpenAI + Anthropic + Google) to get truly diverse perspectives.
Why did the test stop after 2 rounds instead of 3?
AI Crucible automatically stops testing when models reach high similarity (convergence threshold set at 90%). In this test, GPT-5.2 and GPT-5.1 reached 90.2% similarity after round 2, indicating they had converged on very similar conclusions. This saves both time and cost by avoiding redundant refinement rounds.
How do OpenAI models compare to Claude and Gemini?
Each model family has distinct strengths. See our Mistral Large 3 comparison article for detailed cross-provider benchmarks. Generally, Claude excels at nuanced analysis, Gemini at speed, and GPT models at balanced versatility.
What's the best model for high-volume applications?
For high-volume use cases, GPT-5.1 or GPT-5.2 offer the best cost-performance balance. Consider ensemble strategies that use cheaper models for initial drafts and premium models for validation only.
Are the quality improvements incremental or transformative?
Based on our evaluation, the improvements from GPT-5.1 to GPT-5.2 are incremental but meaningful. GPT-5.2 scored 9.0/10 vs 8.9/10, with notable gains in clarity (9.5 vs 9) and usefulness (9.5 vs 9). The 90.2% similarity suggests both models apply similar reasoning approaches, with differences being more in execution precision and conciseness than strategic framework. Notably, GPT-5.2 achieved this with 44% fewer tokens.
How often should I re-evaluate model choices?
Benchmark models quarterly or when new versions release. Model capabilities evolve rapidly, and pricing changes can shift cost-quality tradeoffs. Use AI Crucible's comparison features to test new models against your existing workflows.
What if my results differ from this benchmark?
Model performance varies by task type, prompt structure, and use case. Run your own benchmarks with prompts representative of your actual workload. Our AI Prompt Assistant can help optimize configuration for your specific needs.