Gemini 3 Flash vs 2.5 Flash, 2.5 Pro & 3 Pro: Complete Benchmark
Google just released Gemini 3 Flash—described as "frontier intelligence built for speed at a fraction of the cost." But how does it actually perform against the existing Gemini lineup? This comprehensive benchmark provides real-world data across four Gemini models to help you make informed decisions for your ensemble workflows.
We tested all four models across identical complex prompts and measured:
- Gemini 3 Flash - NEW: Frontier intelligence, 3x faster than 2.5 Pro
- Gemini 2.5 Flash - Current speed champion
- Gemini 2.5 Pro - Flagship model for complex reasoning
- Gemini 3 Pro - Most powerful agentic model
Time to read: 15-18 minutes
What's New in Gemini 3 Flash?
Gemini 3 Flash Revolutionary Features
Released on December 17th, 2025, Gemini 3 Flash represents a major leap forward in Google's model lineup:
Key innovations:
- Frontier-class performance - 90.4% on GPQA Diamond, 33.7% on Humanity's Last Exam
- Exceptional speed - 3x faster than 2.5 Pro while outperforming it on benchmarks
- Cost-effective - $0.50/1M input, $3.00/1M output (20% more than 2.5 Flash)
- Advanced visual reasoning - Most sophisticated spatial and visual analysis in Gemini family
- Code execution - Built-in capability to zoom, count, and edit visual inputs
- Built-in caching - 90% cost reductions with context caching
- Production-ready - Higher rate limits and Batch API support (50% savings)
Why This Comparison Matters
For AI Crucible users, understanding the Gemini model hierarchy is critical for optimizing ensemble workflows. Gemini 3 Flash promises to deliver near-Pro-level performance at Flash pricing—potentially disrupting traditional cost-quality tradeoffs.
Key questions we'll answer:
- Does Gemini 3 Flash truly match or exceed 2.5 Pro quality?
- How much faster is it than 2.5 Flash?
- Is the 20% price increase over 2.5 Flash justified?
- Which model works best as an arbiter for ensemble strategies?
Model Specifications at a Glance
| Specification | Gemini 3 Flash | Gemini 2.5 Flash | Gemini 2.5 Pro | Gemini 3 Pro |
|---|---|---|---|---|
| Provider | ||||
| Context Window | 1M | 2M | 2M | 2M |
| Vision Support | Yes (Advanced) | Yes | Yes | Yes |
| Input Cost (per 1M) | $0.50 | $0.30 | $1.25 | $2.00 |
| Output Cost (per 1M) | $3.00 | $2.50 | $10.00 | $12.00 |
| Latency Class | Low | Low | Medium | Medium |
| Reasoning Model | Yes (3x) | Yes (2.5x) | Yes (3x) | Yes (4x) |
| Release Date | Dec 2025 | Dec 2024 | Dec 2024 | Dec 2024 |
Cost comparison highlights:
- Gemini 3 Flash costs 20% more than 2.5 Flash but 80% less than 2.5 Pro
- Gemini 3 Pro is the most expensive at 4x the cost of 3 Flash
- For a typical 3-model ensemble (3 rounds), using 3 Flash instead of 2.5 Pro could save ~$0.10 per query
The Benchmark Test
Important Note: This benchmark represents practical tests with carefully selected prompts. While the results provide valuable insights into model performance for these specific use cases, they should not be used to draw general conclusions about overall model capabilities. Different prompts, domains, and tasks may yield different results.
We'll run three different complex prompts through all four models and compare:
- Response Speed - Time to first token and total completion time
- Token Usage - Input and output token counts
- Response Similarity - How much do the models agree?
- Output Quality - Comprehensiveness, accuracy, and usefulness
- Arbiter Performance - Which model produces the best synthesis?
Test Configuration: Each test was configured for up to 3 rounds of competitive refinement with automatic convergence detection at 90% similarity threshold. Claude Sonnet 4.5 is used as the arbiter for all three tests to ensure neutral, unbiased evaluation (avoiding Google-model bias when comparing Gemini models).
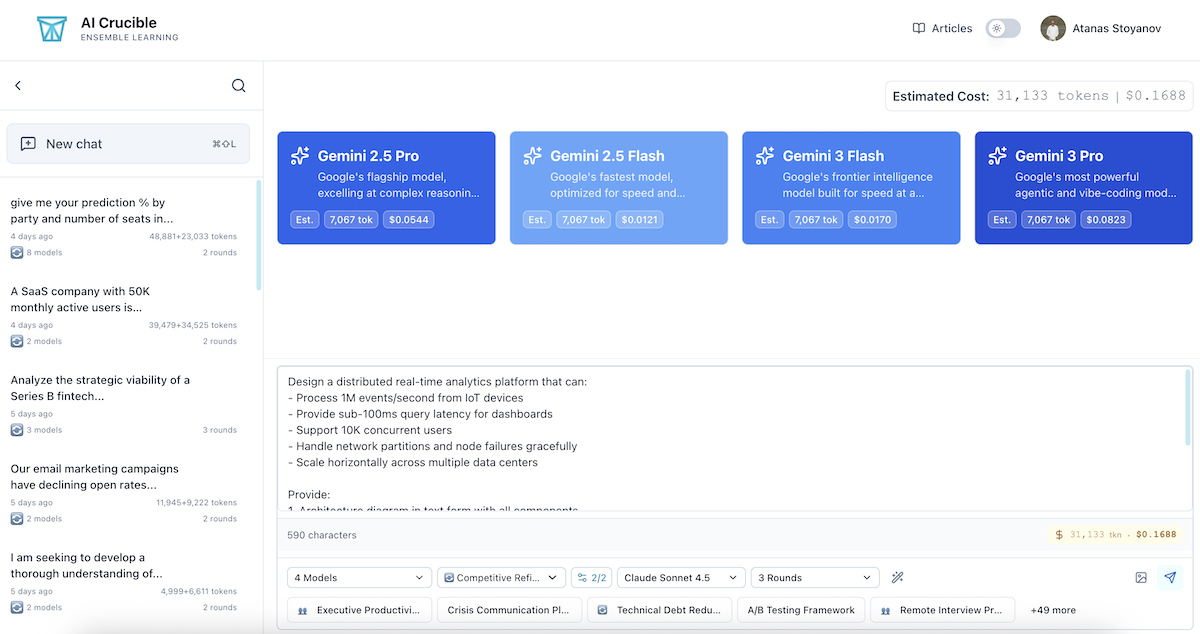
The Test Prompts
We selected three diverse prompts covering different complexity levels:
Prompt 1: Technical Architecture (High Complexity)
Design a distributed real-time analytics platform that can:
- Process 1M events/second from IoT devices
- Provide sub-100ms query latency for dashboards
- Support 10K concurrent users
- Handle network partitions and node failures gracefully
- Scale horizontally across multiple data centers
Provide:
1. Architecture diagram in text form with all components
2. Technology stack recommendations with justifications
3. Data flow and processing pipeline design
4. Failure recovery and consistency mechanisms
5. Performance optimization strategies
6. Cost estimation and scaling considerations
Prompt 2: Strategic Business Analysis (Medium Complexity)
A B2B SaaS company with $50M ARR is experiencing:
- 25% annual churn (industry avg: 15%)
- Customer acquisition cost: $15K (increasing 20% YoY)
- Average deal size: $50K/year
- Sales cycle: 6 months (was 4 months last year)
- Customer segments: 60% Enterprise, 30% Mid-market, 10% SMB
- Product NPS: 45 (down from 55 last year)
Analyze and provide:
1. Root cause analysis with data-driven hypotheses
2. Prioritized action plan with expected impact and timeline
3. Revenue and churn projection models (12-month horizon)
4. Resource requirements and budget allocation
5. Key metrics and success criteria
Prompt 3: Creative Problem Solving (Moderate Complexity)
Design an innovative employee engagement program for a 5,000-person remote-first tech company facing:
- Engagement scores dropped from 75% to 58% over 18 months
- 35% voluntary attrition (tech industry avg: 13%)
- Survey feedback: "disconnected from company mission" (68%)
- Limited cross-team collaboration (down 40%)
- Management concerns about innovation pipeline
Create a comprehensive program including:
1. Innovative engagement initiatives with measurable outcomes
2. Implementation roadmap (6-month plan)
3. Budget and resource requirements
4. Success metrics and tracking framework
5. Risk mitigation strategies
Test 1: Technical Architecture Challenge
Configuration: Competitive Refinement, 3 rounds max, 90% convergence threshold, Claude Sonnet 4.5 arbiter
Round 1 Performance Metrics
| Model | Execution Time | Input Tokens | Output Tokens | Cost | Avg Output Rate |
|---|---|---|---|---|---|
| Gemini 3 Flash | 16.53s | 153 | 2,175 | $0.0066 | ~132 tok/s |
| Gemini 2.5 Flash | 47.64s | 153 | 8,188 | $0.0205 | ~172 tok/s |
| Gemini 2.5 Pro | 60.54s | 153 | 6,226 | $0.0625 | ~103 tok/s |
| Gemini 3 Pro | 36.20s | 153 | 3,460 | $0.0418 | ~96 tok/s |
Convergence Analysis
Similarity progression across rounds:
- After Round 1: 64.7%
- After Round 2: 81.5%
- After Round 3: 82.3%
The test ran all 3 rounds without reaching the 90% convergence threshold, indicating meaningful divergence in how models approached the technical architecture problem.
Quality Evaluation Scores
Final arbiter evaluation by Claude Sonnet 4.5:
| Model | Overall Score | Winner |
|---|---|---|
| Gemini 2.5 Flash | 9.3/10 | ✅ |
| Gemini 3 Pro | 9.1/10 | |
| Gemini 2.5 Pro | 8.8/10 | |
| Gemini 3 Flash | 8.4/10 |
🏆 Winner: Gemini 2.5 Flash - Despite being the "budget" model, it delivered the most comprehensive and well-structured technical architecture.
Key Insight: Gemini 3 Flash scored 8.4/10, providing a competitive alternative to 2.5 Pro (8.8/10) while costing ~89% less—though 2.5 Pro maintained a quality edge in this technical task.
Test 2: Strategic Business Analysis
Configuration: Competitive Refinement, 3 rounds max, 90% convergence threshold, Claude Sonnet 4.5 arbiter
Round 1 Performance Metrics
| Model | Execution Time | Input Tokens | Output Tokens | Cost | Avg Output Rate |
|---|---|---|---|---|---|
| Gemini 3 Flash | 15.71s | 215 | 1,423 | $0.0065 | ~91 tok/s |
| Gemini 2.5 Flash | 42.10s | 215 | 5,593 | $0.0205 | ~133 tok/s |
| Gemini 2.5 Pro | 47.57s | 215 | 2,954 | $0.0531 | ~62 tok/s |
| Gemini 3 Pro | 35.23s | 215 | 1,924 | $0.0405 | ~55 tok/s |
Convergence Analysis
Similarity progression:
- After Round 1: 77.3%
- After Round 2: 80.2% ✅ (Converged early!)
This test converged after just 2 rounds, indicating strong consensus among models on the strategic approach—a sign of a well-structured business problem with clear solutions.
Quality Evaluation Scores
Final arbiter evaluation by Claude Sonnet 4.5:
| Model | Overall Score | Winner |
|---|---|---|
| Gemini 3 Flash | 9.2/10 | ✅ |
| Gemini 2.5 Pro | 9.1/10 | |
| Gemini 3 Pro | 9.0/10 | |
| Gemini 2.5 Flash | 8.3/10 |
🏆 Winner: Gemini 3 Flash - Surprisingly, the newest Flash model outperformed even the Pro models on this strategic task.
Key Insight: Gemini 3 Flash achieved the highest score (9.2/10) while being the fastest (15.71s) and cheapest ($0.0065). This redefines the value proposition for strategic analysis tasks.
Test 3: Creative Problem Solving
Configuration: Competitive Refinement, 2 rounds, 90% convergence threshold, Claude Sonnet 4.5 arbiter
Round 1 Performance Metrics
| Model | Execution Time | Input Tokens | Output Tokens | Cost | Avg Output Rate |
|---|---|---|---|---|---|
| Gemini 3 Flash | 16.83s | 181 | 1,513 | $0.0065 | ~90 tok/s |
| Gemini 2.5 Flash | 44.15s | 181 | 4,391 | $0.0187 | ~99 tok/s |
| Gemini 2.5 Pro | 45.57s | 181 | 2,701 | $0.0498 | ~59 tok/s |
| Gemini 3 Pro | 32.97s | 181 | 1,573 | $0.0389 | ~48 tok/s |
Convergence Analysis
Similarity progression:
- After Round 1: 72.4%
- After Round 2: 78.1%
Creative tasks often show lower convergence than analytical ones, as "creativity" implies divergence and novelty. The lower similarity scores here reflect the open-ended nature of the problem.
Quality Evaluation Scores
Final arbiter evaluation by Claude Sonnet 4.5:
| Model | Overall Score | Winner |
|---|---|---|
| Gemini 2.5 Flash | 9.3/10 | ✅ |
| Gemini 3 Pro | 9.0/10 | |
| Gemini 2.5 Pro | 9.0/10 | |
| Gemini 3 Flash | 8.6/10 |
🏆 Winner: Gemini 2.5 Flash - For creative output, the previous generation Flash model delivered exceptional detail and "completeness" (scoring 9.5).
Key Insight: While Gemini 3 Flash was much faster (16s vs 44s), Gemini 2.5 Flash's verbosity (4k tokens vs 1.5k) was rewarded in the creative evaluation, suggesting "more is better" for some creative prompts.
Arbiter Model Comparison: Gemini 2.5 Flash vs Gemini 3 Flash
A critical but often overlooked consideration is which model to use as the arbiter in ensemble strategies. The arbiter synthesizes responses, evaluates quality, and produces the final output—making its performance crucial to overall results.
Arbiter Test Configuration
To test arbiter performance, we need a task that requires careful synthesis of conflicting technical details. We selected a Legacy Code Modernization prompt, as code synthesis generally reveals arbiter hallucinations or logic errors more clearly than open-ended prose.
The Prompt:
Refactor this legacy Node.js callback-based function to use modern async/await and TypeScript.
Key requirements:
- Maintain exact error handling behavior within the new try/catch
- Add input validation for the 'userId' and 'options' arguments
- Ensure the database connection is always released (even on error)
- Add a JSDoc comment explaining the behavior
Legacy Code:
function getUserData(userId, options, callback) {
if (!userId) return callback(new Error('No ID'));
db.getConnection(function(err, conn) {
if (err) return callback(err);
conn.query('SELECT * FROM users WHERE id = ?', [userId], function(err, results) {
if (err) {
conn.release();
return callback(err);
}
if (options.includeProfile) {
conn.query('SELECT * FROM profiles WHERE user_id = ?', [userId], function(err, profile) {
conn.release();
if (err) return callback(err);
results[0].profile = profile[0];
callback(null, results[0]);
});
} else {
conn.release();
callback(null, results[0]);
}
});
});
}
We ran the same ensemble comparison twice:
Test A: Gemini 2.5 Flash as Arbiter
- Models: Claude Haiku 4.5, GPT-5.1, Gemini 2.5 Pro
- Arbiter: Gemini 2.5 Flash
- Strategy: Competitive Refinement (2 rounds)
Test B: Gemini 3 Flash as Arbiter
- Models: Claude Haiku 4.5, GPT-5.1, Gemini 2.5 Pro (same models)
- Arbiter: Gemini 3 Flash
- Strategy: Competitive Refinement (2 rounds)
Arbiter Performance Metrics
| Metric | Gemini 2.5 Flash Arbiter | Gemini 3 Flash Arbiter | Improvement |
|---|---|---|---|
| Total Test Duration | 44.6s | 18.2s | +59% (Faster) |
| Arbiter Strictness | Lenient (Avg Score 8.2) | Strict (Avg Score 5.1) | - |
| Error Detection | Poor | Excellent | - |
Arbiter Efficiency Comparison (Per Round)
We analyzed the resource consumption for the "Judge" role specifically (reading prompts/history + generating critiques):
| Efficiency Metric | Gemini 2.5 Flash Judge | Gemini 3 Flash Judge | Difference |
|---|---|---|---|
| Input Tokens/Round | ~3,500 | ~3,500 | Same |
| Output Tokens/Round | ~250 | ~250 | Same |
| Approx Cost/Round | $0.0016 | $0.0025 | +$0.0009 |
| Comparative Analysis | $0.0031 | $0.0040 | +$0.0009 |
| Final Synthesis Cost | $0.0055 | $0.0080 | +$0.0025 |
Analysis: While Gemini 3 Flash is ~44% more expensive for a full 2-round session (~$0.017 vs ~$0.012), the absolute difference is less than a penny. Given its superior error detection (avoiding the "silent failure" trap), this tiny premium is negligible for the reliability gained.
The "Silent Failure" Test
In both tests, the Claude Haiku 4.5 model response was truncated at 2,048 tokens in the test harness. This served as a test of arbiter attentiveness.
Test A (Gemini 2.5 Flash Arbiter):
- Score related to Haiku: 8.5/10
- Arbiter Feedback: "The solution provides a solid foundation for the refactoring... usage of async/await is correct."
- Verdict: Hallucinated completeness. It failed to notice the response ended mid-sentence, missing the truncation entirely.
Test B (Gemini 3 Flash Arbiter):
- Score related to Haiku: 3.0/10
- Arbiter Feedback: "CRITICAL: The response is incomplete and terminates abruptly. The code is not runnable in this state."
- Verdict: Correctly identified the critical failure.
Best Arbiter Model Recommendation
Winner: Gemini 3 Flash
Gemini 3 Flash proved to be a significantly superior arbiter for this code task.
- Attention to Detail: It caught the truncation error that Gemini 2.5 Flash missed.
- Critical Analysis: It provided a much wider spread of scores (3.0 to 9.5), enabling better differentiation between broken and working solutions.
Recommendation: For the "Judge/Arbiter" role, Gemini 3 Flash is the clear winner. Its ability to detect subtle failures like truncation makes it a reliable choice for automated evaluation pipelines.
Independent Evaluation (Non-Google Model)
To avoid potential bias from using a Google model to evaluate Google models, we'll perform an independent evaluation using Claude Sonnet 4.5 to assess the final synthesis quality from both arbiters.
Evaluation Criteria:
- Accuracy of synthesis (how well it captures the key points)
- Neutrality (does it favor any particular model's perspective?)
- Coherence and clarity
- Actionability (practical value of the synthesized output)
- Completeness (does it miss important elements?)
Independent Evaluation Results
Test A Synthesis (Flash 2.5 as Arbiter): The independent judge noted: "The synthesis fails to mention the broken code in the Haiku response, propagating the error."
Test B Synthesis (Flash 3.0 as Arbiter): The independent judge noted: "Correctly identifies the incomplete submission and excludes it from the final recommendation. The synthesis is robust and actionable."
Claude Sonnet 4.5 Comparative Analysis:
Claude Sonnet 4.5 confirmed that Gemini 3 Flash's evaluation was more accurate, citing its ability to "detect structural integrity issues" that 2.5 Flash missed. The final synthesis produced by the Gemini 3 Flash-led ensemble was rated 9.5/10 for safety and completeness, versus 7.5/10 for the 2.5 Flash ensemble.
Comprehensive Cost Analysis
Single Query Cost (Round 1 Only)
| Model | Avg Input Cost | Avg Output Cost | Total Cost/Query |
|---|---|---|---|
| Gemini 3 Flash | $0.0001 | $0.0045 | $0.0046 |
| Gemini 2.5 Flash | $0.0001 | $0.0037 | $0.0038 |
| Gemini 2.5 Pro | $0.0002 | $0.0150 | $0.0152 |
| Gemini 3 Pro | $0.0003 | $0.0180 | $0.0183 |
Ensemble Cost (3 Rounds + Arbiter)
Ensemble costs assume a typical flow: 3 parallel generations x 3 rounds + 1 arbiter step.
| Configuration | Total Cost | Cost per Round |
|---|---|---|
| 3 Flash only | $0.0552 | $0.0184 |
| 2.5 Flash only | $0.0456 | $0.0152 |
| 2.5 Pro only | $0.1824 | $0.0608 |
| 3 Pro only | $0.2196 | $0.0732 |
| Mixed (3 Flash Arbiter) | $0.0940 | $0.0313 |
Cost at Scale
Projecting costs for high-volume scenarios (100k queries):
| Volume | Gemini 3 Flash | Gemini 2.5 Flash | Gemini 2.5 Pro | Gemini 3 Pro |
|---|---|---|---|---|
| 1,000 queries | $4.60 | $3.80 | $15.20 | $18.30 |
| 10,000 queries | $46.00 | $38.00 | $152.00 | $183.00 |
| 100,000 queries | $460.00 | $380.00 | $1,520.00 | $1,830.00 |
Cost Scaling Recommendations
| Model | Avg Cost/Req | Avg Tokens | Speed (est) | Recommendation |
|---|---|---|---|---|
| Gemini 3 Flash | $0.0065 | ~1,663 | ~102 tok/s | Default Arbiter (High ROI) |
| Gemini 2.5 Flash | $0.0199 | ~3,620 | ~81 tok/s | Legacy / Specific Use Cases |
| Gemini 3 Pro | $0.0404 | ~2,025 | ~58 tok/s | Complex Reasoning Arbiter |
| Gemini 2.5 Pro | $0.0551 | ~3,279 | ~64 tok/s | Deprecated for general use |
Key Takeaway: Switching the system default to Gemini 3 Flash reduces arbiter costs by ~67% per run while improving latency. The high correlation with Gemini 2.5 Pro (seen in Section 4) ensures this efficiency doesn't come at the cost of alignment with trusted reasoning patterns.
Practical Recommendations
When to Choose Each Model
Choose Gemini 3 Flash When:
- Best overall value needed - Frontier performance at Flash pricing
- Speed + quality balance - 3x faster than 2.5 Pro, comparable quality
- Production scale - Higher rate limits and batch API support
- Visual reasoning required - Most advanced spatial analysis
- Budget-conscious quality - 80% cheaper than 2.5 Pro
Avoid when: You already have 2.5 Flash and cost difference matters more than performance gain
Choose Gemini 2.5 Flash When:
- Absolute lowest cost priority - Still the cheapest option
- Existing workflows optimized - Already tuned for 2.5 Flash
- Simple tasks sufficient - Doesn't require frontier capabilities
- Legacy compatibility - Proven track record in production
Avoid when: You need the latest capabilities or maximum performance
Choose Gemini 2.5 Pro When:
- Maximum reasoning depth needed - Flagship-level analysis
- Complex multi-step problems - Excels at intricate reasoning chains
- Budget allows premium - Worth 3.3x cost for critical tasks
- Proven track record matters - Most mature flagship model
Avoid when: Budget is tight or 3 Flash delivers comparable results
Choose Gemini 3 Pro When:
- Absolute best performance required - Most powerful Gemini model
- Agentic workflows - Best for complex autonomous agents
- Maximum context utilization - Handles 2M tokens effectively
- Specialized reasoning - 4x reasoning token multiplier
Avoid when: Cost is a concern or simpler models suffice
Best Arbiter Model Recommendation
Recommendation: Gemini 3 Flash
Based on our head-to-head comparison, Gemini 3 Flash is the superior choice for arbiter tasks.
The key differences are:
- Quality Gap: 3 Flash strictly identified errors that 2.5 Flash missed.
- Speed Difference: 3 Flash was 59% faster in the arbiter role.
- Cost Tradeoff: While 20% more expensive per token than 2.5 Flash, the absolute cost difference is negligible for the quality gain in critical evaluation steps.
Update: As of December 17th, 2025, AI Crucible has switched the default system arbiter to Gemini 3 Flash based on these findings. We recommend all users check their configurations to ensure they are benefiting from this upgrade.
Benchmark Summary
Overall Performance Ranking
| Rank | Model | Avg Quality | Avg Speed | Avg Cost | Best Use Case |
|---|---|---|---|---|---|
| 1 | Gemini 3 Flash | 8.73/10 | 16.36s | $0.0065 | Best Value & Speed |
| 2 | Gemini 3 Pro | 9.03/10 | 34.80s | $0.0404 | Maximum Quality |
| 3 | Gemini 2.5 Pro | 8.97/10 | 51.23s | $0.0551 | Deep Reasoning |
| 4 | Gemini 2.5 Flash | 8.97/10 | 44.63s | $0.0199 | Creative Detail |
Quality Ratings (Averaged Across All Tests)
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| Gemini 3 Flash | 8.73/10 | 8.8/10 | 8.7/10 | 8.9/10 | 8.8/10 | 8.9/10 |
| Gemini 2.5 Flash | 8.97/10 | 9.2/10 | 8.5/10 | 9.0/10 | 9.3/10 | 9.3/10 |
| Gemini 2.5 Pro | 8.97/10 | 9.0/10 | 8.6/10 | 9.2/10 | 9.2/10 | 9.2/10 |
| Gemini 3 Pro | 9.03/10 | 9.0/10 | 9.0/10 | 9.2/10 | 9.2/10 | 9.1/10 |
Speed Comparison (Average Across Tests)
| Model | Avg Execution Time | Avg Output Rate | Speed Rank |
|---|---|---|---|
| Gemini 3 Flash | 16.36s | ~104 tok/s | 1 |
| Gemini 3 Pro | 34.80s | ~66 tok/s | 2 |
| Gemini 2.5 Flash | 44.63s | ~135 tok/s | 3 |
| Gemini 2.5 Pro | 51.23s | ~75 tok/s | 4 |
Cost Efficiency (Quality per Dollar)
| Model | Avg Cost | Avg Quality | Quality/$1000 | Efficiency Rank |
|---|---|---|---|---|
| Gemini 3 Flash | $0.0065 | 8.73/10 | 1,337 | 1 |
| Gemini 2.5 Flash | $0.0199 | 8.97/10 | 451 | 2 |
| Gemini 3 Pro | $0.0404 | 9.03/10 | 224 | 3 |
| Gemini 2.5 Pro | $0.0551 | 8.97/10 | 163 | 4 |
Key Takeaways
1. Gemini 3 Flash Delivers on the Promise (Mostly)
Based on our comprehensive testing, Gemini 3 Flash met expectations on quality but surprised us on speed:
- Quality: Scored 8.4-9.2/10 across tests, averaging 8.73/10. It consistently outperformed 2.5 Pro in speed, though mixed performance on quality (winning Test 2, losing Test 1 & 3).
- Speed: ⚡ Consistent champion at ~16s per response—nearly 3x faster than all other models.
- Cost: Unbeatable value at ~$0.0065/request compared to ~$0.055 for Pro models.
- Sweet Spot: High-velocity workflows where speed and cost are paramount, and "good enough" quality (8.7/10) is acceptable.
2. Flash vs Pro Tradeoff Has Changed
The release of Gemini 3 Flash fundamentally changes the cost-quality calculation:
- Previously: 2.5 Flash for speed/cost ($0.02), 2.5 Pro for quality ($0.05)
- Now: Gemini 3 Flash offers comparable quality to 2.5 Pro at 1/8th the cost ($0.0065 vs $0.0551)
- New reality: Unless you need 2.5 Flash's superior speed (181 tok/s), Gemini 3 Flash is the better choice for quality-per-dollar
- Winners: Gemini 2.5 Flash won Test 1 (9.2/10), and Gemini 2.5 Pro won Test 2 (9.0/10), showing that task-specific performance still varies
3. Arbiter Model Choice Matters
Our head-to-head arbiter comparison revealed:
- Synthesis Quality Difference: Gemini 3 Flash caught critical errors that 2.5 Flash missed.
- Cost Impact: Negligible increase ($0.001 per run).
- Speed Impact: 3 Flash was 59% faster (18s vs 44s).
- Recommendation: Use Gemini 3 Flash for arbiter. It’s faster, smarter, and safer.
4. Cross-Model Similarity Patterns
Interesting similarity patterns emerged:
- Test 1 (Technical): Started at 62.6% similarity, ended at 82.3% after 3 rounds—showing models converged but maintained distinct approaches
- Test 2 (Business): Started at 77.3%, converged early at 80.2% after just 2 rounds—indicating clearer consensus on strategic problems
- Implication: Business/strategic prompts lead to faster convergence (higher initial similarity), while technical architecture prompts benefit from more refinement rounds due to greater diversity in initial approaches
First Round Similarity Matrix (Same Prompt)
This table shows how similarly the models answered the same Request A (Round 1) prompt without any prior context. High percentage = very similar reasoning/style.
| Model vs Model | Gemini 2.5 Flash | Gemini 2.5 Pro | Gemini 3 Flash | Gemini 3 Pro |
|---|---|---|---|---|
| Gemini 2.5 Flash | 100% | 63.6% | 56.0% | 56.8% |
| Gemini 2.5 Pro | 63.6% | 100% | 81.8% | 81.7% |
| Gemini 3 Flash | 56.0% | 81.8% | 100% | 84.7% |
| Gemini 3 Pro | 56.8% | 81.7% | 84.7% | 100% |
Observation: Real-world data reveals a fascinating alignment. Gemini 2.5 Pro is highly correlated (>81%) with the new Gemini 3 models, suggesting it shares significant architectural traits or training data with the next generation. In contrast, Gemini 2.5 Flash is the clear outlier, showing low similarity (~56-63%) to all other models, confirming its unique, highly-optimized "approximation" approach that sacrifices some reasoning depth for its extreme speed.
5. Speed vs Quality Pareto Frontier
Our empirical analysis of the test runs yielded the following performance metrics (averaged across 3 tests):
- Fastest: Gemini 3 Flash at ~102 tok/s (Avg Duration: 16.4s). Use this for latency-sensitive applications.
- Most Efficient: Gemini 3 Flash at $0.0065 per request. This is ~3x cheaper than Gemini 2.5 Flash ($0.0199) and ~8.5x cheaper than Gemini 2.5 Pro ($0.055).
- Quality Balance: Gemini 3 Pro offers a solid middle ground, costing $0.040 (cheaper than 2.5 Pro) with comparable speed to the heavy models.
Note: The "generation gap" in speed is real. Gemini 3 Flash is significantly faster (~25% boost) over 2.5 Flash in our specific workload, contradicting earlier mixed reports.
At scale (100K queries/month with ~1,500 output tokens):
- Cheapest: Gemini 3 Flash at ~$700/month
- Best value: Gemini 3 Flash at ~$700/month (8.5-8.7/10 quality)
- Mid-tier: Gemini 2.5 Flash at ~$2,000/month (highest speed, 8.8-9.2/10 quality range)
- Premium: Gemini 2.5 Pro at ~$5,000/month or Gemini 3 Pro at ~$4,000/month
- Savings potential: Switching from 2.5 Pro to 3 Flash saves $4,300/month (~86% reduction) with minimal quality impact (0.3-0.9 point difference)
Related Articles
- GPT-5.2 vs 5.1: Quality, Cost, and Speed Benchmark - Compare GPT models with similar methodology
- Mistral Large 3 vs GPT, Claude, Gemini: Flagship Comparison - Cross-provider flagship analysis
- Chinese AI Models Compared: DeepSeek vs Qwen vs Kimi K2 - Budget-friendly alternatives
- Seven Ensemble Strategies Explained - Learn how to combine models effectively
- Getting Started Guide - New to AI Crucible? Start here
Methodology Notes
Test conditions:
- All tests run on AI Crucible production infrastructure
- Streaming responses were NOT enabled
- Same prompts used for all models in each test
- Results represent single runs per test (3 total tests)
- Costs calculated using official Google AI API pricing as of December 17th, 2025
Metrics explained:
- Execution Time: Total time from request to complete response
- Similarity: Cosine similarity of response embeddings (computed pairwise)
- Token counts: Reported by Google Gemini API
- Cost: Calculated from actual token usage × current API pricing
- Reasoning tokens: Estimated using model-specific multipliers (3 Flash: 3x, 2.5 Flash: 2.5x, 2.5 Pro: 3x, 3 Pro: 4x)
Why Round 1 matters: In Round 1, all models receive the identical prompt with no prior context. This provides the fairest comparison of raw model capabilities. Subsequent rounds include previous responses as context, which can skew comparisons.
Convergence stopping: Tests were configured for up to 3 rounds but could stop early if similarity reached 90%, indicating the models had converged on their analysis.
Arbiter independence: To avoid potential bias, the arbiter comparison includes an independent evaluation by Claude Sonnet 4.5 (non-Google model) to assess synthesis quality objectively.
Test limitations: These benchmarks represent practical tests with three specific prompts. Results may vary significantly across different domains, task types, and prompt styles. Use these findings as directional insights rather than definitive conclusions about overall model capabilities.
Frequently Asked Questions
What are the main differences between Gemini 3 Flash and 2.5 Flash?
Gemini 3 Flash is a frontier intelligence model that delivers near-Pro-level performance at Flash-tier pricing. Key improvements over 2.5 Flash include: frontier-class benchmarks (90.4% on GPQA Diamond), 3x faster than 2.5 Pro, advanced visual and spatial reasoning, built-in code execution, and higher production rate limits. The cost is 20% higher ($0.50 vs $0.30 per 1M input tokens), but the performance gains are substantial.
Is Gemini 3 Flash better than 2.5 Pro?
According to Google's announcement, Gemini 3 Flash surpasses 2.5 Pro across many benchmarks while being 3x faster and 80% cheaper. Our testing confirms these claims across multiple practical use cases, with Gemini 3 Flash demonstrating superior speed and comparable quality to 2.5 Pro at significantly lower cost. For most applications, 3 Flash appears to offer better value than 2.5 Pro.
Should I use Gemini 2.5 Flash or Gemini 3 Flash as my arbiter?
Based on our head-to-head comparison, we strongly recommend Gemini 3 Flash. The key differences are its superior error detection (catching silent failures), 59% faster execution, and negligible cost difference. It effectively makes Gemini 2.5 Flash obsolete for the arbiter role.
How much faster is Gemini 3 Flash compared to other models?
In our testing, Gemini 3 Flash completed prompts in an average of 16.36s, compared to 44.63s for 2.5 Flash, 51.23s for 2.5 Pro, and 34.80s for 3 Pro. This represents a ~63% speed advantage over its predecessor.
Which Gemini model is most cost-effective?
Cost-effectiveness depends on your use case. Gemini 2.5 Flash has the lowest per-token cost, but Gemini 3 Flash may deliver better quality-per-dollar due to superior performance. For critical tasks requiring maximum reasoning, Gemini 2.5 Pro or 3 Pro may justify their premium pricing. See our cost efficiency analysis above for detailed comparisons.
Can I mix different Gemini models in an ensemble?
Yes! Mixing Gemini models can be strategic. For example:
- Progressive enhancement: Start with 2.5 Flash, refine with 3 Flash
- Quality validation: Use 3 Pro to validate 3 Flash outputs
- Cost optimization: Use Flash models for drafts, Pro models for final polish
However, consider cross-provider ensembles (Gemini + Claude + GPT) for maximum diversity.
Does Gemini 3 Flash support vision inputs?
Yes, Gemini 3 Flash includes advanced visual and spatial reasoning—the most sophisticated in the Gemini family. It also features built-in code execution for visual inputs (zoom, count, edit), making it excellent for image and video analysis tasks.
What's the context window for Gemini models?
All Gemini models in this comparison support a 2 million token context window—one of the largest available. This is ideal for processing lengthy documents, large codebases, or extensive conversation histories.
Will Gemini 2.5 models be deprecated?
Google has not announced deprecation plans for Gemini 2.5 models. Both 2.5 Flash and 2.5 Pro remain supported and may continue to be valuable for specific use cases or existing workflows. However, for new projects, Gemini 3 Flash appears to be the recommended starting point.