Mistral Large 3 vs GPT, Claude & Gemini: Full Flagship Comparison (2026 Benchmark)
We're excited to announce that Mistral AI models are now available in AI Crucible. This includes Mistral's flagship model, Mistral Large 3, along with Mistral Medium 3.1, Mistral Small 3.2, and the efficient Ministral edge models.
Mistral AI has rapidly established itself as Europe's leading AI company, building open-weight models that compete directly with closed-source giants. But how does their flagship model actually perform against the established leaders?
This article provides a head-to-head comparison of the four flagship models from major AI providers:
- Mistral Large 3 - Mistral AI's flagship (41B active, 675B total parameters)
- GPT-5.1 - OpenAI's latest flagship model
- Claude Opus 4.5 - Anthropic's most capable model
- Gemini 3 Pro - Google's most powerful agentic model
Time to read: 12-15 minutes
Example cost: $0.53 (3 rounds + arbiter analysis)
What Makes Mistral Large 3 Unique?
Mistral Large 3 Architecture
Mistral Large 3 uses a granular Mixture-of-Experts (MoE) architecture with 41B active parameters from a total of 675B parameters. This design achieves strong performance while maintaining reasonable inference costs—a balance that makes it particularly attractive for production deployments.
Key characteristics:
- 256K context window (competitive with Claude's 200K)
- Vision/multimodal support (images, documents)
- Mixture-of-Experts architecture for efficient inference
- Open weights available for self-hosting
- Competitive pricing at $0.50/1M input tokens
Why This Comparison Matters
Mistral Large 3 enters a competitive market dominated by OpenAI, Anthropic, and Google. For AI Crucible users building ensemble workflows, understanding where Mistral excels—and where it doesn't—helps optimize model selection for different tasks.
Model Specifications at a Glance
| Specification | Mistral Large 3 | GPT-5.1 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|
| Provider | Mistral AI | OpenAI | Anthropic | |
| Context Window | 256K | 128K | 200K | 2M |
| Vision Support | Yes | Yes | Yes | Yes |
| Input Cost (per 1M) | $0.50 | $1.25 | $5.00 | $2.00 |
| Output Cost (per 1M) | $1.50 | $10.00 | $25.00 | $12.00 |
| Architecture | MoE (41B/675B) | Dense | Dense | Dense |
| Latency Class | Medium | Medium | High | Medium |
| Open Weights | Yes | No | No | No |
Cost analysis: Mistral Large 3 is 2.5x cheaper than GPT-5.1 on input tokens and 10x cheaper than Claude Opus 4.5. However, pricing alone doesn't determine value—quality, speed, and task-specific performance matter equally.
The Comparison Test
We'll run the same complex prompt through all four flagship models and compare:
- Response Speed - Total execution time
- Token Usage - Input and output token counts
- Response Similarity - How much do the models agree?
- Output Quality - Comprehensiveness, accuracy, and usefulness
The Test Prompt
We chose a multi-faceted strategic analysis question requiring:
- Market analysis
- Technical reasoning
- Risk assessment
- Actionable recommendations
A Series B startup ($15M raised, 45 employees) is building a developer tools platform.
They're currently focused on code review automation but are considering expansion into:
- AI-assisted code generation
- Security vulnerability scanning
- Performance monitoring and optimization
Analyze this strategic decision considering:
1. Market opportunity and competitive landscape for each option
2. Technical complexity and build vs. buy trade-offs
3. Resource allocation and team scaling requirements
4. Risk factors and go-to-market timing
5. Recommended prioritization with rationale
Provide a comprehensive strategic recommendation with specific next steps.
Step 1: Setting Up the Comparison
Navigate to AI Crucible Dashboard
- Go to the AI Crucible Dashboard
- Click on the prompt input area
- Select Competitive Refinement strategy for iterative improvement
Select the Four Flagship Models
From the model selection panel, choose:
- Mistral Large 3
- GPT-5.1
- Claude Opus 4.5
- Gemini 3 Pro
Tip: This combination spans European, American, and diverse architectural approaches—ideal for comprehensive analysis.
Configure Settings
- Rounds: 3 (for meaningful refinement)
- Arbiter Model: Gemini 2.5 Flash (fast, cost-effective synthesis)
Click Run to start the comparison.
Step 2: Speed Comparison Results
Here's how each model performed on response speed in Round 1:
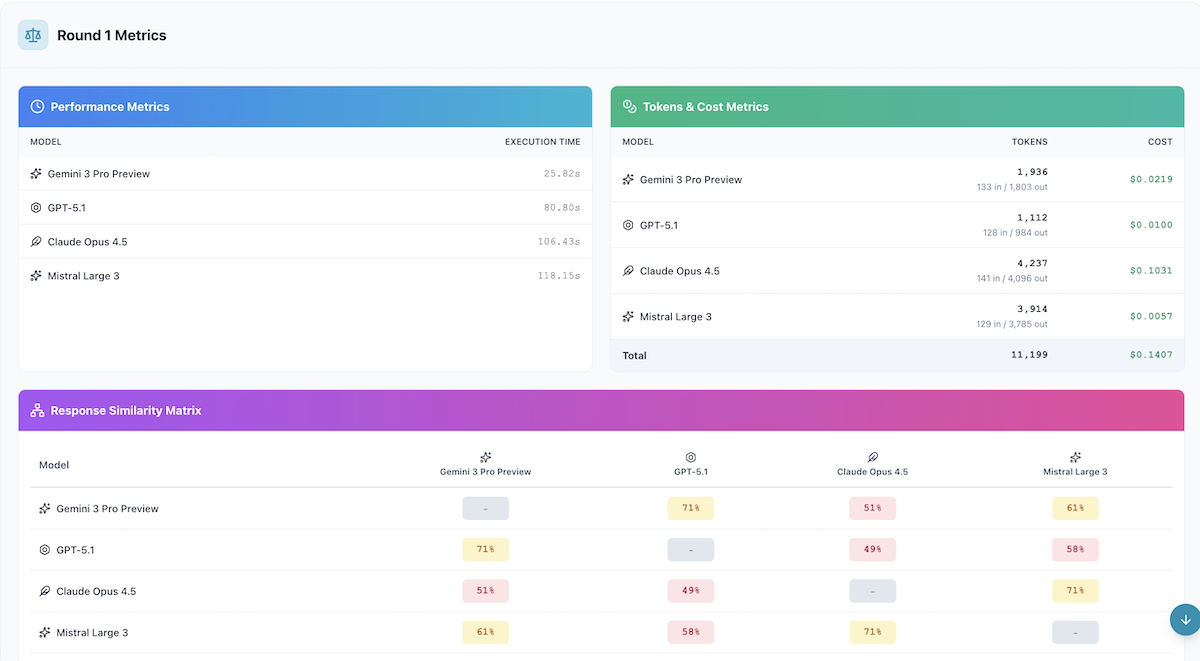
Total Execution Time
| Model | Execution Time | Tokens/Second |
|---|---|---|
| Gemini 3 Pro | 25.82s | ~70 tok/s |
| GPT-5.1 | 80.80s | ~12 tok/s |
| Claude Opus 4.5 | 106.43s | ~39 tok/s |
| Mistral Large 3 | 118.15s | ~32 tok/s |
Key Observation: Gemini 3 Pro is the clear speed winner, completing in just 25.82 seconds—over 3x faster than the next model. Mistral Large 3 was the slowest at 118.15 seconds, nearly 5x slower than Gemini. The 92-second gap between fastest and slowest is substantial for time-sensitive applications.
Step 3: Token Usage Comparison
Token efficiency affects both cost and response comprehensiveness.
Input Token Processing
All models received the same prompt, but token counting varies by tokenizer:
| Model | Input Tokens | Notes |
|---|---|---|
| GPT-5.1 | 128 | Most efficient |
| Mistral Large 3 | 129 | Very efficient |
| Gemini 3 Pro | 133 | Standard encoding |
| Claude Opus 4.5 | 141 | Slightly verbose |
Output Token Generation
| Model | Output Tokens | Total Tokens |
|---|---|---|
| GPT-5.1 | 984 | 1,112 |
| Gemini 3 Pro | 1,803 | 1,936 |
| Mistral Large 3 | 3,785 | 3,914 |
| Claude Opus 4.5 | 4,096 | 4,237 |
Finding: Significant variation in output length. GPT-5.1 produced the most concise response (984 tokens), while Claude Opus 4.5 generated 4x more tokens (4,096). Mistral Large 3 was similarly verbose to Claude, suggesting both models provide more comprehensive, detailed responses.
Total Cost per Response
| Model | Total Tokens | Total Cost |
|---|---|---|
| Mistral Large 3 | 3,914 | $0.0057 |
| GPT-5.1 | 1,112 | $0.0100 |
| Gemini 3 Pro | 1,936 | $0.0219 |
| Claude Opus 4.5 | 4,237 | $0.1031 |
| Combined Total | 11,199 | $0.1407 |
Cost Analysis: Mistral Large 3 is the clear cost winner at $0.0057—nearly half the cost of GPT-5.1 despite producing 3.5x more tokens. Claude Opus 4.5 is 18x more expensive than Mistral for this task. At scale:
| Volume | Mistral Large 3 | GPT-5.1 | Gemini 3 Pro | Claude Opus 4.5 |
|---|---|---|---|---|
| 1,000 queries | $5.70 | $10.00 | $21.90 | $103.10 |
| 10,000 queries | $57.00 | $100.00 | $219.00 | $1,031.00 |
| 100,000 queries | $570.00 | $1,000 | $2,190 | $10,310 |
Step 4: Response Similarity Analysis
AI Crucible's similarity analysis reveals how much the models agree with each other. Higher similarity suggests convergent thinking; lower similarity indicates diverse perspectives.
Pairwise Similarity Scores
| Model Pair | Similarity | Interpretation |
|---|---|---|
| Gemini ↔ GPT | 71% | High agreement |
| Claude ↔ Mistral | 71% | High agreement |
| Gemini ↔ Mistral | 61% | Moderate agreement |
| GPT ↔ Mistral | 58% | Moderate agreement |
| Gemini ↔ Claude | 51% | Low agreement |
| GPT ↔ Claude | 49% | Low agreement |
Notable pattern: The models form two distinct clusters. Gemini and GPT align closely (71%), as do Claude and Mistral (71%). However, cross-cluster similarity is much lower (49-61%), suggesting fundamentally different reasoning approaches.
Key Overlapping Themes (High Confidence)
All four models agreed on:
- AI Code Generation Priority - All recommended this as the highest-priority expansion
- Build vs. Buy Assessment - Consensus on building core differentiators, buying commoditized features
- Phased Rollout - All suggested sequential rather than parallel expansion
- Talent Acquisition - ML/AI hiring identified as critical path
Divergent Perspectives (Lower Agreement)
Models disagreed on:
| Topic | Mistral Large 3 | GPT-5.1 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|
| Second Priority | Security scanning | Performance tools | Security scanning | Security scanning |
| Timeline | 18 months | 12 months | 24 months | 15 months |
| Hiring Needs | 8-10 ML engineers | 12-15 engineers | 6-8 specialists | 10-12 engineers |
| Partnership Focus | Security vendors | Cloud providers | Enterprise clients | Developer community |
Insight: The 49% similarity between GPT-5.1 and Claude Opus 4.5 is remarkably low for flagship models—they approach problems quite differently. This makes combining them in an ensemble particularly powerful, as they bring genuinely diverse perspectives. Meanwhile, Mistral Large 3 aligns most closely with Claude (71%), suggesting similar depth and reasoning style.
Step 5: Output Quality Deep Dive
After 3 rounds of competitive refinement, AI Crucible's arbiter model (Gemini 2.5 Flash) evaluated each response across five dimensions: Accuracy, Creativity, Clarity, Completeness, and Usefulness.
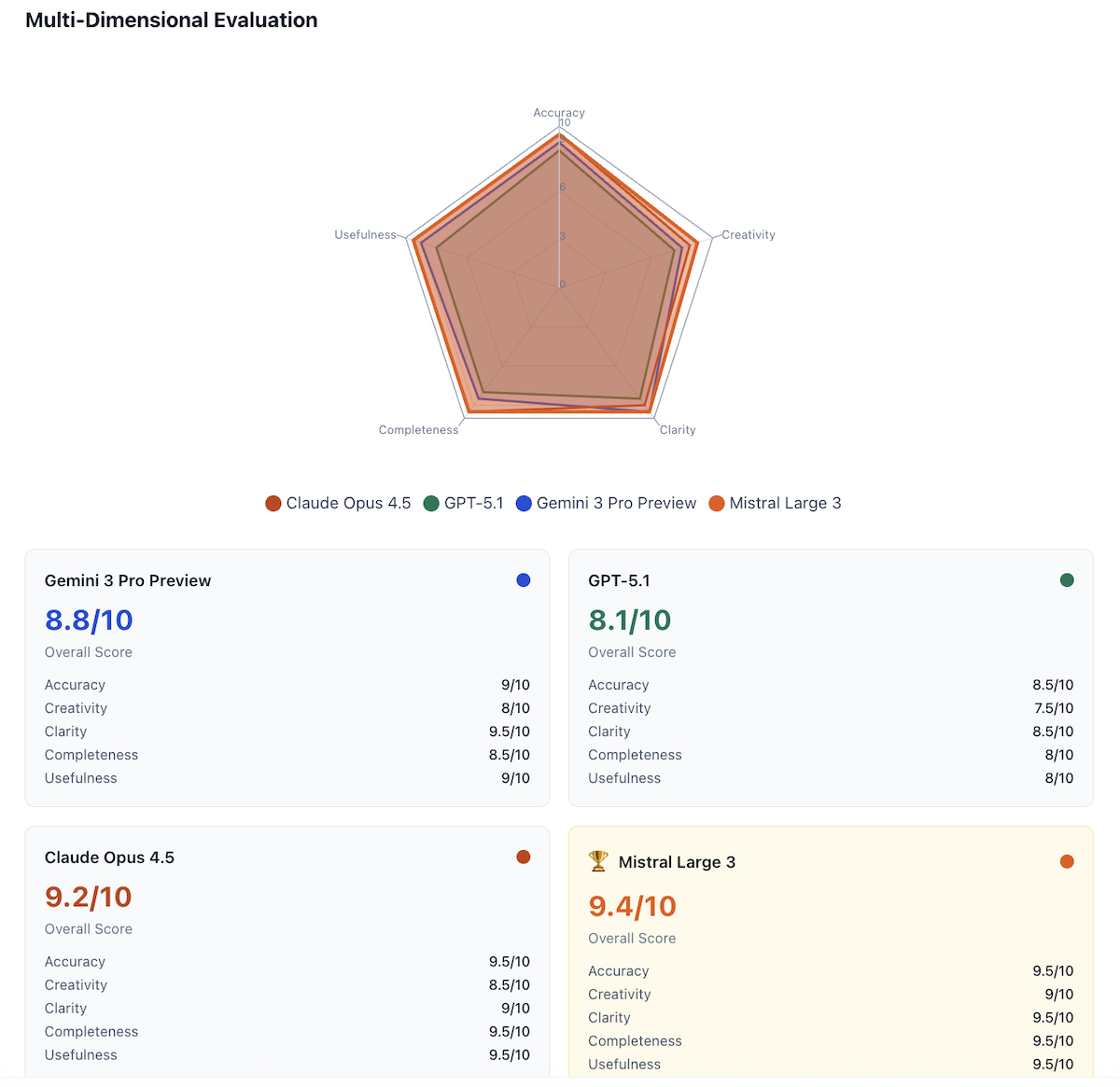
Multi-Dimensional Evaluation Scores
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| Mistral Large 3 🏆 | 9.4/10 | 9.5/10 | 9/10 | 9.5/10 | 9.5/10 | 9.5/10 |
| Claude Opus 4.5 | 9.2/10 | 9.5/10 | 8.5/10 | 9/10 | 9.5/10 | 9.5/10 |
| Gemini 3 Pro | 8.8/10 | 9/10 | 8/10 | 9.5/10 | 8.5/10 | 9/10 |
| GPT-5.1 | 8.1/10 | 8.5/10 | 7.5/10 | 8.5/10 | 8/10 | 8/10 |
Surprise winner: Mistral Large 3 achieved the highest overall score (9.4/10), narrowly beating Claude Opus 4.5 (9.2/10) while costing 14x less.
Mistral Large 3 Response (9.4/10) — Winner
Arbiter Evaluation:
"Mistral Large 3 delivers an outstanding response, characterized by its strong strategic thesis and 'Critical Refinement' sections that provide deep justification for its recommendations. The 'Layered Approach' for build vs. buy is very clear, and the phased roadmap is exceptionally detailed with specific deliverables and success metrics. The 'Immediate Next Steps (First 30 Days)' is highly actionable, and the 'Narrative for Series C' is a brilliant touch for investor positioning. It combines strategic depth with actionable steps, making it incredibly useful and clear. It matches Claude in completeness and usefulness, while arguably having a slightly more compelling overall narrative and structure."
Strengths:
- Outstanding strategic thesis with deep justification
- Exceptionally detailed phased roadmap with specific milestones
- Highly actionable 30-day immediate next steps
- Brilliant "Series C narrative" for investor positioning
- Clear and compelling overall structure
Weaknesses:
- Slowest response time (118.15s in Round 1)
Claude Opus 4.5 Response (9.2/10)
Arbiter Evaluation:
"Claude Opus 4.5 is exceptionally thorough and detailed, particularly in its 'Technical Complexity & Build vs. Buy Analysis' with specific cost estimates, which is a significant value-add. Its emphasis on 'noise reduction' and 'context' as core differentiators is very insightful. The risk matrix is comprehensive, and the 'Implementation Roadmap' is incredibly granular and actionable, providing weekly/monthly steps. This model excels in completeness and usefulness, offering a highly practical guide. The only minor drawback is that the executive summary is slightly less 'punchy' than Mistral or Gemini."
Strengths:
- Highly detailed technical complexity analysis
- Specific cost estimates for build/buy components
- Comprehensive risk matrix with probability/impact
- Granular implementation roadmap with weekly actions
Weaknesses:
- Most expensive option ($0.3160 for 3 rounds)
- Executive summary less punchy than competitors
Gemini 3 Pro Response (8.8/10)
Arbiter Evaluation:
"Gemini 3 Pro provides a very clear, concise, and strategically sound recommendation. Its 'Intelligent Quality Gate' narrative is compelling and easy to grasp. The differentiation between AI generation and remediation is well-articulated. The build vs. buy strategy is practical, emphasizing wrapping open-source tools. The risk mitigation table is excellent. It scores high on clarity and usefulness due to its directness and actionable advice. Completeness is good, covering all prompt points, though it lacks the granular cost estimates of Claude or the detailed roadmap of Mistral."
Strengths:
- Clear and concise strategic narrative
- Excellent "Intelligent Quality Gate" framing
- Well-structured risk mitigation table
- Strong clarity and directness
Weaknesses:
- Less granular cost estimates than Claude
- Less detailed roadmap than Mistral
GPT-5.1 Response (8.1/10)
Arbiter Evaluation:
"GPT-5.1 offers a solid, well-structured response with good market sizing data and a clear 'Intelligent Code Guardian' brand. Its resource allocation section is quite detailed, which is helpful. The go-to-market strategy is well-defined. However, it feels slightly less innovative in its framing compared to Gemini or Mistral, and the technical build vs. buy details are not as deep as Claude. It's a very competent response but doesn't quite reach the strategic depth or actionable specificity of the top performers."
Strengths:
- Good market sizing data
- Clear brand positioning ("Intelligent Code Guardian")
- Well-detailed resource allocation section
Weaknesses:
- Lower creativity score (7.5/10)
- Less strategic depth than competitors
- Most concise output may lack detail for complex decisions
Full Cost Breakdown (3 Rounds)
Here's the complete cost breakdown for running 3 rounds of competitive refinement plus arbiter analysis:
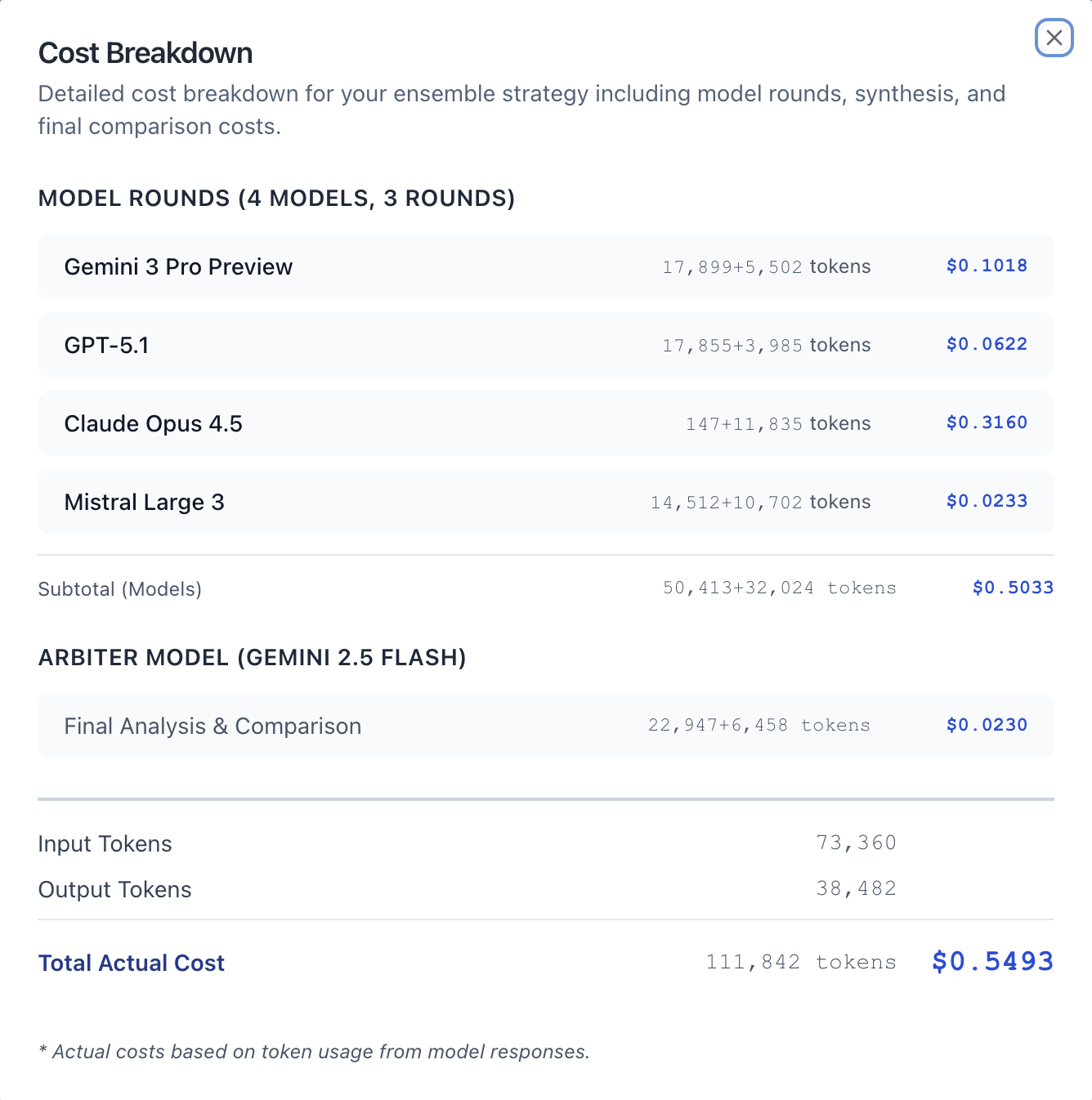
Model Costs (3 Rounds)
| Model | Input Tokens | Output Tokens | Total Cost |
|---|---|---|---|
| Mistral Large 3 | 14,512 | 10,702 | $0.0233 |
| GPT-5.1 | 17,855 | 3,985 | $0.0622 |
| Gemini 3 Pro | 17,899 | 5,502 | $0.1018 |
| Claude Opus 4.5 | 147 | 11,835 | $0.3160 |
| Subtotal (Models) | 50,413 | 32,024 | $0.5033 |
Arbiter Cost
| Component | Input Tokens | Output Tokens | Cost |
|---|---|---|---|
| Final Analysis & Comparison | 11,277 | 3,411 | $0.0119 |
Total Session Cost
| Metric | Value |
|---|---|
| Input Tokens | 61,690 |
| Output Tokens | 35,435 |
| Total Tokens | 97,125 |
| Total Cost | $0.5271 |
Key insight: Mistral Large 3 produced the second-most output tokens (10,702) while costing only $0.0233—that's 14x cheaper than Claude ($0.3160) for comparable quality scores (9.4 vs 9.2). Claude's cost was driven by its extensive output (11,835 tokens) at premium pricing.
Step 6: Practical Recommendations
Based on the comparative analysis, here's what we learned:
When to Choose Each Model
Choose Mistral Large 3 (9.4/10) When: 🏆
- Best overall quality needed - Highest score at 9.4/10
- Cost efficiency is critical - 14x cheaper than Claude for comparable quality
- Comprehensive, strategic responses needed - Excels at detailed roadmaps and actionable steps
- You need open-weight flexibility - Self-hosting option for sensitive data
- Creative analysis required - Highest creativity score (9/10)
Avoid when: Speed is critical (slowest at 118.15s in Round 1)
Choose Claude Opus 4.5 (9.2/10) When:
- Technical detail with cost estimates - Unparalleled build vs. buy analysis
- Granular implementation roadmaps - Weekly/monthly action items
- Complex organizational questions - Excels at nuanced human factors
- Budget is flexible - Still excellent quality at premium price
Avoid when: Cost is constrained ($0.3160 for 3 rounds)
Choose Gemini 3 Pro (8.8/10) When:
- Speed is paramount - 4x faster than any competitor at 25.82s
- Clear, concise narratives needed - Strong "Quality Gate" framing
- Massive context needed - 2M token window (largest available)
- Balanced quality and speed - Good scores across all dimensions
Avoid when: Maximum quality or lowest cost is required
Choose GPT-5.1 (8.1/10) When:
- Concise responses needed - Most focused output
- Market sizing data required - Good quantitative analysis
- Brand positioning focus - Clear narrative frameworks
Avoid when: You need comprehensive strategic analysis or highest quality
Ensemble Strategy: Combining Flagships
The real power emerges when you combine these flagship models. Based on our Round 1 similarity analysis, GPT-5.1 + Claude Opus 4.5 offers maximum diversity (49% similarity) while Claude + Mistral provides depth with redundancy (71% similarity).
Recommended Ensemble Configurations
For maximum perspective diversity:
Combine: GPT-5.1 + Claude Opus 4.5 (49% similarity)
Or: Gemini 3 Pro + Claude Opus 4.5 (51% similarity)
Why: Lowest similarity = most diverse perspectives
Estimated cost: ~$0.11-0.13 per round
For comprehensive analysis at low cost:
Primary: Mistral Large 3 (comprehensive + cheap)
Reviewer: Gemini 3 Pro (fast + different perspective)
Synthesizer: Gemini 2.5 Flash (fast, cheap)
Why: 61% similarity provides diversity; total cost ~$0.03
Estimated cost: ~$0.08-0.10 for 3 rounds
For speed-optimized workflows:
Primary: Gemini 3 Pro (25s response)
Alternative: GPT-5.1 (71% similar, 80s response)
Synthesizer: Gemini 2.5 Flash (fast, cheap)
Why: High similarity ensures coherence; Gemini's speed dominates
Estimated cost: ~$0.04-0.06 for 3 rounds
Benchmark Summary
| Metric | Mistral Large 3 | GPT-5.1 | Claude Opus 4.5 | Gemini 3 Pro | Winner |
|---|---|---|---|---|---|
| Overall Quality | 9.4/10 🏆 | 8.1/10 | 9.2/10 | 8.8/10 | Mistral |
| Speed (Round 1) | 118.15s | 80.80s | 106.43s | 25.82s | Gemini |
| Cost (3 Rounds) | $0.0233 | $0.0622 | $0.3160 | $0.1018 | Mistral |
| Context Window | 256K | 128K | 200K | 2M | Gemini |
Quality Ratings (After 3 Rounds)
| Metric | Mistral Large 3 | GPT-5.1 | Claude Opus 4.5 | Gemini 3 Pro | Winner |
|---|---|---|---|---|---|
| Accuracy | 9.5/10 | 8.5/10 | 9.5/10 | 9/10 | Tie |
| Creativity | 9/10 | 7.5/10 | 8.5/10 | 8/10 | Mistral |
| Clarity | 9.5/10 | 8.5/10 | 9/10 | 9.5/10 | Tie |
| Completeness | 9.5/10 | 8/10 | 9.5/10 | 8.5/10 | Tie |
| Usefulness | 9.5/10 | 8/10 | 9.5/10 | 9/10 | Tie |
| Open Weights | Yes | No | No | No | Mistral |
Key Takeaways
1. Mistral Large 3 Wins on Quality AND Cost
The biggest surprise: Mistral Large 3 achieved the highest overall score (9.4/10), narrowly beating Claude Opus 4.5 (9.2/10) while costing 14x less ($0.0233 vs $0.3160 for 3 rounds). This is exceptional value—flagship quality at budget prices.
2. Each Flagship Has a Clear Strength
| Priority | Best Choice | Why |
|---|---|---|
| Quality | Mistral Large 3 🏆 | 9.4/10 overall, highest creativity |
| Speed | Gemini 3 Pro | 25.82s (4x faster than next) |
| Cost | Mistral Large 3 | $0.0233 for 3 rounds (14x cheaper) |
| Context | Gemini 3 Pro | 2M tokens (8x larger than GPT) |
| Open Weights | Mistral Large 3 | Only flagship with open weights |
3. Mistral Matches Claude's Depth at 14x Lower Cost
With 71% response similarity and nearly identical completeness/usefulness scores (9.5/10), Mistral Large 3 and Claude Opus 4.5 deliver comparable depth. But Mistral does it for $0.0233 vs Claude's $0.3160—a 14x cost advantage with marginally better quality.
4. Gemini 3 Pro Dominates Speed
Gemini completed in 25.82 seconds—over 4x faster than the next model (GPT-5.1 at 80.80s). For latency-sensitive applications, Gemini is the clear choice despite higher cost than Mistral.
5. GPT-5.1 Underperformed Expectations
GPT-5.1 scored lowest (8.1/10) with the weakest creativity (7.5/10) and completeness (8/10). Its concise responses (984 tokens in Round 1) may lack the depth needed for complex strategic analysis compared to the more comprehensive outputs from Mistral and Claude.
6. Open Weights Matter for Enterprise
Mistral Large 3 is the only flagship model with open weights. Combined with its best-in-class performance, this makes Mistral uniquely compelling for enterprises requiring data sovereignty, on-premise deployment, or regulatory compliance.
All Available Mistral Models
With this integration, AI Crucible now supports the full Mistral model family:
| Model | Use Case | Input Cost | Output Cost | Context |
|---|---|---|---|---|
| Mistral Large 3 | Flagship analysis | $0.50/1M | $1.50/1M | 256K |
| Mistral Medium 3.1 | Balanced performance | $0.40/1M | $1.20/1M | 128K |
| Mistral Small 3.2 | Fast, cost-effective | $0.10/1M | $0.30/1M | 128K |
| Ministral 8B | Edge deployment | $0.10/1M | $0.10/1M | 128K |
| Ministral 3B | Ultra-efficient edge | $0.04/1M | $0.04/1M | 128K |
Recommendation: Start with Mistral Large 3 for complex tasks, use Mistral Small 3.2 for high-volume applications, and consider Ministral models for edge or cost-critical deployments.
Frequently Asked Questions
Is Mistral Large 3 better than Claude Opus 4.5?
In our benchmark, Mistral Large 3 scored 9.4/10 overall, slightly beating Claude Opus 4.5 at 9.2/10. Mistral matched Claude on accuracy (9.5/10), completeness (9.5/10), and usefulness (9.5/10) while scoring higher on creativity (9/10 vs 8.5/10). The key advantage is cost: Mistral delivered comparable quality at 14x lower price ($0.0233 vs $0.3160 for 3 rounds). Choose Claude when you need the deepest technical build-vs-buy analysis with specific cost estimates.
How much does Mistral Large 3 cost compared to GPT and Claude?
Mistral Large 3 is dramatically cheaper than competitors. Input tokens cost $0.50/1M (vs $1.25 for GPT-5.1, $5.00 for Claude Opus 4.5, $2.00 for Gemini 3 Pro). In our 3-round test, Mistral cost $0.0233 total — 2.7x cheaper than GPT-5.1 ($0.0622), 4.4x cheaper than Gemini 3 Pro ($0.1018), and 14x cheaper than Claude ($0.3160). At 100K queries, that translates to roughly $2,330 for Mistral versus $31,600 for Claude.
Is Mistral Large 3 open source?
Mistral Large 3 offers open weights, making it the only flagship-tier model (competing with GPT-5.1, Claude Opus 4.5, and Gemini 3 Pro) that can be self-hosted. This is particularly valuable for enterprises requiring data sovereignty, on-premise deployment, or regulatory compliance. The model uses a Mixture-of-Experts architecture with 41B active parameters from 675B total, and its weights are available for download and deployment on your own infrastructure.
Which AI model is fastest: Mistral, GPT, Claude, or Gemini?
Gemini 3 Pro is the clear speed winner at 25.82 seconds — over 4x faster than GPT-5.1 (80.80s), Claude Opus 4.5 (106.43s), and Mistral Large 3 (118.15s). If speed is your primary concern, Gemini is the best choice. Mistral Large 3 was the slowest in our test, though its higher output quality (9.4/10 vs Gemini's 8.8/10) may justify the wait for tasks where quality matters more than latency.
Should I use Mistral Large 3 or GPT-5.1 for coding tasks?
Mistral Large 3 outperformed GPT-5.1 significantly in our benchmark: 9.4/10 vs 8.1/10 overall, with GPT-5.1 scoring lowest on creativity (7.5/10) and completeness (8/10). GPT-5.1 produced the most concise responses (984 tokens vs Mistral's 3,785), which may lack depth for complex strategic or architectural analysis. However, GPT-5.1 is faster (80.80s vs 118.15s) and may still excel at focused, shorter coding tasks. For comprehensive analysis, Mistral is the better choice at roughly half the cost.
Try It Yourself
Ready to test Mistral Large 3 against other flagships? Here's a quick start:
- Go to AI Crucible Dashboard
- Select: Mistral Large 3, GPT-5.1, Claude Opus 4.5, Gemini 3 Pro
- Choose Strategy: Competitive Refinement or Expert Panel
- Enter your prompt and click Run
- Analyze: Review speed, cost, similarity, and quality
Suggested test prompts:
- "Design a go-to-market strategy for a B2B AI startup entering the European market"
- "Analyze the technical architecture trade-offs between monolith and microservices for a fintech platform"
- "Create a 90-day onboarding plan for a new VP of Engineering joining a Series C startup"
Related Articles
- Chinese AI Models Compared: DeepSeek vs Qwen vs Kimi K2 - Compare budget-friendly alternatives
- Seven Ensemble Strategies Explained - Learn how to combine models effectively
- LLM Landscape 2025: Choosing the Right AI Model - Comprehensive model overview
- Getting Started Guide - New to AI Crucible? Start here
Methodology Notes
Test conditions:
- All tests run on AI Crucible production infrastructure
- Streaming responses enabled for all models
- Same prompt used for all models (Round 1 comparison ensures fairness)
- Results represent single runs (your results may vary)
- Costs calculated using official API pricing as of December 3rd, 2025
Metrics explained:
- Execution Time: Total time from request to complete response
- Similarity: Cosine similarity of response embeddings (computed pairwise)
- Token counts: Reported by each provider's API
- Cost: Calculated from actual token usage × current API pricing
Why Round 1 matters: In Round 1, all models receive the identical prompt with no prior context. This provides the fairest comparison of raw model capabilities. Subsequent rounds include previous responses as context, which can skew comparisons.
Image Generation Prompts
For article hero image (1200x630px, aspect ratio 1.91:1, light/clean aesthetic for technical audience):
Prompt 1: Four Pillars Comparison
Create a clean, minimal illustration of four vertical pillars of different heights on white background, each representing a flagship AI model. From left to right: orange pillar (Mistral), green pillar (GPT/OpenAI), orange-brown pillar (Claude/Anthropic), blue pillar (Gemini/Google). Pillars have subtle geometric patterns. Use only Mistral orange (#FF7000), GPT green (#10A37F), Claude orange (#D97757), and Gemini blue (#4285F4) colors. Flat design style with no gradients, no shadows, no depth effects. Technical diagram aesthetic with clean lines. The image represents comparing four flagship AI models. Dimensions: 1200x630px (aspect ratio 1.91:1), horizontal landscape orientation. No text in image.
Prompt 2: Radar Chart Comparison
Create a clean, minimal illustration of four overlapping radar/spider charts on light gray background (#F8F9FA), each in a different color representing a flagship AI model. Charts show different performance profiles with varying vertices. Use Mistral orange (#FF7000), GPT green (#10A37F), Claude orange (#D97757), and Gemini blue (#4285F4). Flat design with no gradients, semi-transparent fills. Technical diagram aesthetic showing model comparison across multiple dimensions. Dimensions: 1200x630px (aspect ratio 1.91:1), horizontal landscape orientation. No text in image.
Prompt 3: Racing Lanes
Create a clean, minimal illustration of four horizontal racing lanes on white background, each with a simple geometric marker (diamond, circle, triangle, square) at different positions along the track. Lane colors from top to bottom: Mistral orange (#FF7000), GPT green (#10A37F), Claude orange (#D97757), Gemini blue (#4285F4). Finish line on the right side. Flat design style with no gradients, no shadows. Technical aesthetic representing model performance comparison. Dimensions: 1200x630px (aspect ratio 1.91:1), horizontal landscape orientation. No text in image.
Prompt 4: Connected Nodes
Create a clean, minimal illustration of four interconnected circular nodes on white background arranged in a slight arc. Each node is a different color: Mistral orange (#FF7000), GPT green (#10A37F), Claude orange (#D97757), Gemini blue (#4285F4). Thin gray lines connect all nodes to each other, forming a network. Flat design with no gradients, no shadows. Simple, technical aesthetic representing AI model ecosystem and comparisons. Dimensions: 1200x630px (aspect ratio 1.91:1), horizontal landscape orientation. No text in image.
Style requirements for all prompts:
- Clean, minimal, light aesthetic
- White or very light background
- Flat design or simple isometric
- 4 colors representing four AI providers (no purple, no gradients)
- Technical/professional feel
- No text in image
- Hint at comparison/evaluation of multiple AI models