LLM-as-Judge: 4 AI Graders, One Answer, No Consensus
Using one AI to grade another is now standard practice. But what happens when you let four frontier models grade the same anonymized answers and compare their scorecards? They disagree — sharply. The same response scored 7.9/10 from one judge and 9.7/10 from another. No answer won unanimously. And the toughest grader's favorite answer turned out, unknowingly, to be its own.
Time to read: 11-14 minutes
Session cost: Approx. $1.10 (1 round of four models + a four-judge evaluation)
| Parameter | Value |
|---|---|
| Strategy | Competitive Refinement |
| Rounds | 1 |
| Web Search | Disabled |
| Arbiter | GPT-5.5 |
| Models | Gemini 3.5 Flash, Claude Opus 4.8, GPT-5.5, Qwen3.7-Max |
The Challenge We Set
We needed a prompt where answer quality varies in ways a grader has to actually think about — not a fact lookup, but a question with a precise technical core and a deep edge-case tail. Distributed consensus fits perfectly:
Explain how the Raft consensus algorithm handles leader election and log replication, and identify the specific scenarios where Raft can still lose committed data.
The trap is subtle. Under its formal model, correct Raft never loses committed data — loss only happens when an assumption (durable storage, quorum intersection, correct implementation) is violated. A grader has to reward answers that make that distinction and penalize hand-waving. That makes it an ideal stress test for both the contestants and the judges.
The Contenders
Four models answered the same prompt under Competitive Refinement. Each one took a distinct stylistic route.
| Model | Role | The Pitch |
|---|---|---|
| Gemini 3.5 Flash | The Speed Demon | Fast, cheap, textbook-clear with ASCII diagrams. |
| Claude Opus 4.8 | The Architect | Groups every failure by the assumption it breaks. |
| GPT-5.5 | The Completist | Fifteen distinct loss scenarios, exhaustively documented. |
| Qwen3.7-Max | The Storyteller | Reframes the whole problem as a "durability contract" with reality. |
The Answers: One Prompt, Four Styles
Gemini 3.5 Flash — Clarity at Speed
Gemini opened like a clean textbook, decomposing the problem into the canonical three subproblems:
The Raft consensus algorithm decomposes the state machine replication problem into three relatively independent subproblems: leader election, log replication, and safety.
It leaned on ASCII diagrams for log replication and walked through five loss scenarios, including a memorable "Fsync Illusion." The trade-off: it was the least comprehensive of the four, covering five scenarios where others covered many more — but it delivered in 18.5 seconds for Approx. $0.04, by far the cheapest and fastest run.
Claude Opus 4.8 — The Organizing Mind
Opus did something none of the others did. It grouped every data-loss scenario by the specific assumption it violates: durable storage, quorum loss, operator error, snapshot hazards, and the Byzantine boundary. It then closed with a summary table mapping each scenario to its broken assumption and outcome.
Raft divides time into terms, monotonically increasing integers that act as a logical clock. Each term begins with an election and has at most one leader.
It was tighter than GPT-5.5 (9,300 characters vs 22,647) yet lost almost nothing in coverage. The trade-off: depth-per-word was excellent, at a mid-tier Approx. $0.10 and 47.6 seconds.
GPT-5.5 — The Completist (With a Tell)
GPT-5.5 was relentless: fifteen distinct loss scenarios, neatly separated into protocol failures, implementation bugs, and application-level misuse. It introduced a clean "three pillars" frame:
Raft protects committed data by combining quorum intersection, leader log freshness, and durable storage.
But it also opened with a quiet hallucination — "Continuing from the prior Raft discussion" — implying a conversation that never happened. Two judges flagged it. The trade-off was steep: the longest answer at 22,647 characters, the slowest-but-one at 90.1 seconds, and the priciest by a wide margin at Approx. $0.23 — over 5x the cost of Gemini.
Qwen3.7-Max — The Storyteller
Qwen refused to treat Raft as a pristine math object:
When we say "Raft can lose committed data," what we're really saying is: the contract was violated. The protocol is sound; the substrate lied.
Its "Durability Contract" framing — backed by real-world references to etcd WAL corruption and ext4 writeback behavior — was the most creative of the four. The trade-off: it was the slowest at 91.9 seconds, though cheap at Approx. $0.06.
The Council of AI Judges
Here is where the experiment turns on itself. We ran a four-judge evaluation using the same four models as graders: Gemini 3.5 Flash, GPT-5.5, Claude Opus 4.8, and Qwen3.7-Max. Critically, the judges scored anonymized transcripts — labeled only "Model A," "Model B," and so on. No judge knew which answer it was reading, including its own.
The aggregated consensus scores:
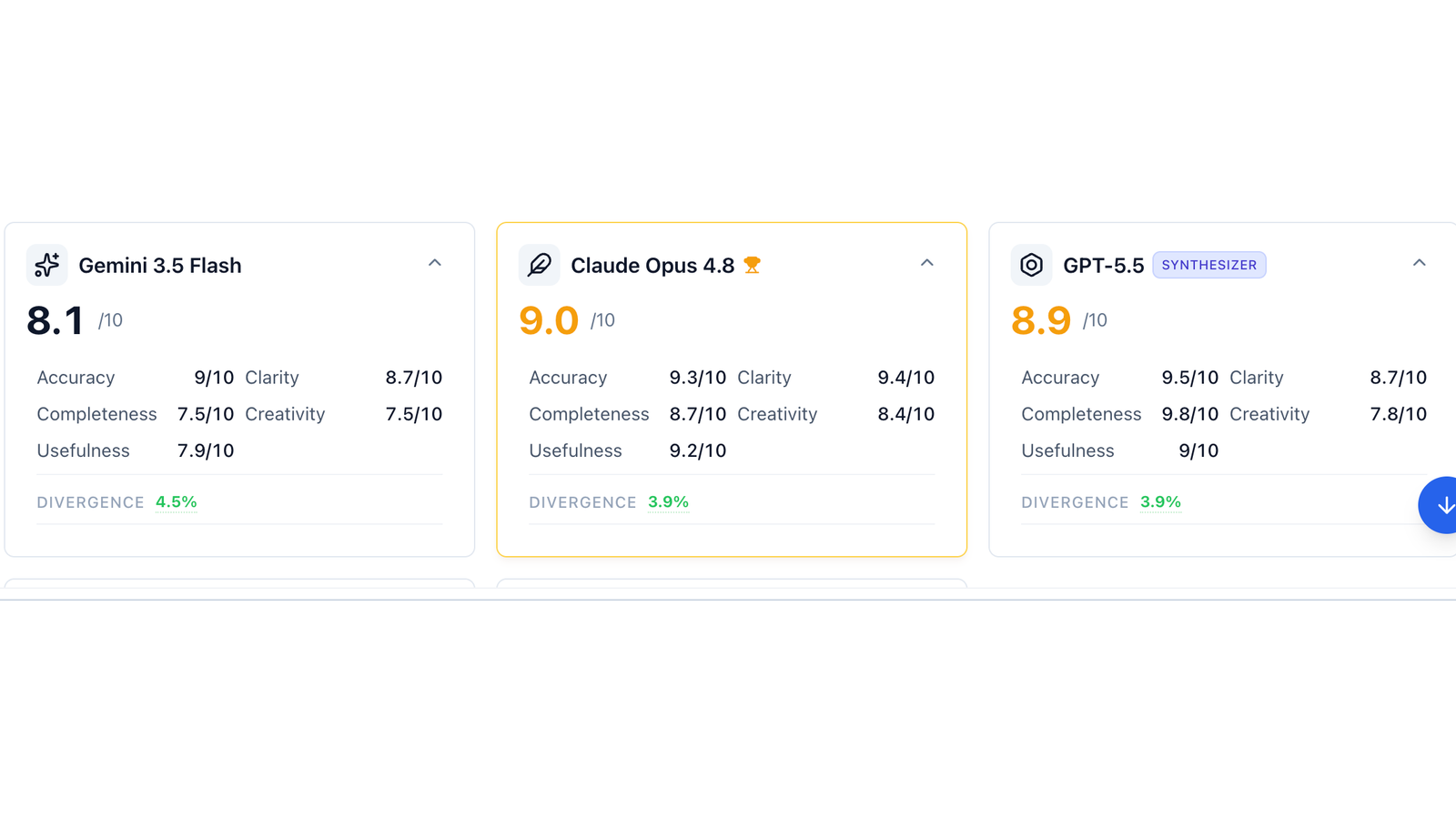
| Answer | Overall | Accuracy | Clarity | Completeness | Creativity | Usefulness | Divergence |
|---|---|---|---|---|---|---|---|
| Claude Opus 4.8 | 9.0 | 9.3 | 9.4 | 8.7 | 8.4 | 9.2 | 3.9% |
| Qwen3.7-Max | 9.0 | 8.9 | 9.2 | 8.3 | 9.3 | 9.2 | 7.0% |
| GPT-5.5 | 8.9 | 9.5 | 8.7 | 9.8 | 7.8 | 9.0 | 3.9% |
| Gemini 3.5 Flash | 8.1 | 9.0 | 8.7 | 7.5 | 7.5 | 7.9 | 4.5% |
On the consensus numbers, Claude Opus 4.8 and Qwen3.7-Max tied at 9.0/10 — the Architect and the Storyteller. GPT-5.5's exhaustiveness earned it the top Accuracy (9.5) and Completeness (9.8) marks, but its lower Creativity (7.8) — and that phantom opening line — pulled its overall down to 8.9.
Where the Judges Disagreed
Consensus hides the real story. Break the scores out per judge and the agreement evaporates:
| Judge ↓ / Answer → | Gemini | Opus | GPT-5.5 | Qwen | Judge avg |
|---|---|---|---|---|---|
| Gemini 3.5 Flash | 8.6 | 9.1 | 9.1 | 9.7 | 9.1 (lenient) |
| GPT-5.5 | 7.4 | 8.5 | 9.2 | 7.9 | 8.3 (harshest) |
| Claude Opus 4.8 | 8.0 | 8.8 | 8.3 | 8.8 | 8.5 |
| Qwen3.7-Max | 8.4 | 9.5 | 9.2 | 9.5 | 9.2 (lenient) |
| Consensus | 8.1 | 9.0 | 8.9 | 9.0 | — |
Three patterns jump out.
The same answer got wildly different scores. Qwen3.7-Max's response earned a 9.7 from the Gemini judge and a 7.9 from the GPT-5.5 judge — a 1.8-point spread on identical, anonymized text. The "objective" score you get depends heavily on who is grading.
Judges have a baseline temperament. GPT-5.5 was the harshest grader (8.3 average), roughly a full point stingier than Gemini (9.1) and Qwen (9.2). If you swap your evaluation judge from GPT-5.5 to Qwen, every model in your pipeline appears to "improve" by ~0.9 points — with no change to the actual outputs.
Three of four judges crowned their own answer — blindly. The GPT-5.5 judge's single highest score (9.2) went to the anonymized GPT-5.5 answer. Qwen's joint-highest (9.5) went to the Qwen answer. Opus's joint-highest (8.8) went to the Opus answer. Only the Gemini judge bucked the trend, ranking its own answer last (8.6) and crowning Qwen instead. Because scoring was blind, this is not provable identity bias — more likely a pull toward a model's own stylistic preferences — but the pattern is a caution worth taking seriously when a model grades a pool that includes its own family.
The most polarizing answer was Qwen's (7.0% divergence) — its vivid, narrative style split the judges, where GPT-5.5's and Opus's more conventional structures drew tighter agreement (3.9%).
The Cost and Speed Reality Check
The four models diverged as much on economics as on substance.
| Metric | Gemini 3.5 Flash | Claude Opus 4.8 | GPT-5.5 | Qwen3.7-Max |
|---|---|---|---|---|
| Answer Cost | $0.04 | $0.10 | $0.23 | $0.06 |
| Response Time | 18.5s | 47.6s | 90.1s | 91.9s |
| Response Length | ~11,400 chars | ~9,300 chars | ~22,600 chars | ~14,900 chars |
GPT-5.5 cost 5x what Gemini did and ran nearly 5x slower, in exchange for the most exhaustive answer — which still did not win the consensus. Opus delivered a tying 9.0 in the shortest answer of all, the strongest depth-per-dollar of the group.
Because every model answered the same prompt independently, their outputs converged closely — pairwise cosine similarity ran high across the board:
| Pair | Similarity | Read |
|---|---|---|
| Gemini 3.5 Flash ↔ Qwen3.7-Max | 0.92 | Most alike |
| Claude Opus 4.8 ↔ Qwen3.7-Max | 0.89 | Close |
| Claude Opus 4.8 ↔ GPT-5.5 | 0.88 | Close |
| GPT-5.5 ↔ Qwen3.7-Max | 0.88 | Close |
| Gemini 3.5 Flash ↔ Claude Opus 4.8 | 0.87 | Close |
| Gemini 3.5 Flash ↔ GPT-5.5 | 0.86 | Most distinct |
High similarity on the facts, wide divergence on the scores: the models broadly agreed on what Raft does, while their graders disagreed on how good each explanation was.
The Verdict
On consensus, Claude Opus 4.8 and Qwen3.7-Max share the crown at 9.0/10 🏆 — but they win for opposite reasons, and the real lesson is about the judges, not the contestants.
- Claude Opus 4.8 is the pick when you want maximum signal per word. Its "group failures by broken assumption" structure was praised by every judge, and it tied for first while writing the shortest answer at a mid-tier cost.
- Qwen3.7-Max is the pick when explanation and memorability matter. Its "durability contract" framing was the most creative response, though it was the slowest and most polarizing.
- GPT-5.5 is the completist's choice — unbeatable coverage and accuracy — but it is the slowest and most expensive, and its hallucinated opener is a reminder that thoroughness is not the same as reliability.
- Gemini 3.5 Flash is the value play: 80% of the quality at a fraction of the cost and latency, ideal when speed and budget outrank exhaustiveness.
Strategic takeaway: If you use an LLM as a judge — for evals, RAG grading, or ensemble synthesis — your choice of judge is a hidden, load-bearing decision. A single judge bakes in its own temperament and a possible tilt toward its own style. The fix is the same one this experiment used: a diverse panel of judges scoring anonymized outputs, and a hard look at where they diverge. Disagreement is not noise; it is the signal that your metric is subjective.
Final Response
### Raft in One Breath
Raft splits consensus into leader election, log replication, and safety rules. Time is divided into monotonically increasing terms, each with at most one leader. A follower whose randomized election timeout expires becomes a candidate, increments its term, votes for itself, and collects a majority quorum of votes — granted only to candidates whose log is at least as up to date as the voter's.
### When Committed Data Survives — and When It Doesn't
Under the formal model (correct implementation, durable stable storage, non-Byzantine servers, quorum operation), Raft does not lose committed entries. Real deployments lose data only when those assumptions break: a node acknowledges a write before fsync actually reaches disk, a snapshot or state-machine store is corrupted, unsafe membership changes create dual quorums, or operators force-recover from a stale replica.
### The Throughline
Every loss scenario is the substrate violating a promise the protocol assumed it would keep. The practical implication: instrument the durability layer as aggressively as the consensus layer.
Try It Yourself
Want to pressure-test your own judge setup? It takes three steps:
- Open the AI Crucible dashboard and select a panel of models from different providers.
- Run any prompt where answer quality genuinely varies, then open the Evaluations tab and pick several judge models.
- Compare the per-judge scorecards — not just the consensus — and look for the spread.
Suggested prompt variation:
Explain how [a consensus / caching / scheduling algorithm] works, and
identify the specific failure scenarios where its core guarantee can
still be violated in production.
Explore the Evaluation: Read the full chat and inspect every judge's raw scorecard yourself in the Shared Chat Session.
Frequently Asked Questions
What is an LLM-as-a-judge?
An LLM-as-a-judge is a language model used to score or rank the outputs of other models, instead of relying on human raters. It is widely used for automated evaluations, RAG answer grading, and selecting the best response in an ensemble. This test shows the approach works but is sensitive to which model does the judging.
Do different AI judges agree with each other?
Not reliably on absolute scores. In our four-judge panel, the same anonymized answer scored anywhere from 7.9 to 9.7 out of 10 depending on the judge — a 1.8-point spread. Judges agreed more on the rough ranking than on the exact numbers, which is why a diverse panel beats any single grader.
Why score answers anonymously?
Anonymized scoring hides model identity from the judge, which removes obvious self-promotion and reduces brand bias. It does not fully eliminate self-preference: three of four judges still gave their highest score to their own (unlabeled) answer, likely because each model favors its own stylistic patterns.
Which model was the harshest judge?
GPT-5.5 was the strictest grader, averaging 8.3/10 across all answers — about a full point below the most lenient judges, Gemini 3.5 Flash and Qwen3.7-Max, which both averaged around 9.1-9.2. Swapping judges can shift every score in a pipeline without any change to the underlying outputs.
Further Reading
- The Competitive Refinement Strategy — How models iterate on each other's answers before a verdict.
- Multi-Model Verification Cuts Hallucinations — Why cross-checking between models beats any single frontier model on reliability.
- Evaluations in AI Crucible — A guide to the judge panel, scoring criteria, and divergence metrics used here.