Anthropic's brand-new Claude Sonnet 5 just landed, priced at $3/$15 per million tokens — a fraction of its flagship sibling Claude Opus 4.8. So we put it straight into a Competitive Refinement battle against Opus 4.8, GPT-5.5, and Gemini 3.1 Pro on a genuinely hard business problem. The surprise: OpenAI's GPT-5.5 took the top judge score, but the cheaper Sonnet 5 quietly outscored the pricier Opus 4.8 it was meant to replace.
Time to read: 10-15 minutes
Session cost: Approx. $0.92 (2 rounds + arbiter synthesis)
| Parameter | Value |
|---|---|
| Strategy | Competitive Refinement |
| Rounds | 2 |
| Web Search | Disabled |
| Arbiter | Claude Haiku 4.5 |
| Models | Claude Sonnet 5, Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro |
The Scenario: A Pricing Decision Worth Millions
Pricing strategy is a brutal test for a language model. There is no retrievable "right answer" — it demands judgment, trade-off reasoning, and the discipline to take a clear position instead of hedging. We handed all four models the same brief:
You are advising the CEO of a Series B B2B SaaS company (developer tools, $12M ARR, growing 40% YoY, net revenue retention 108%, gross margin 78%). They currently sell per-seat annual subscriptions and are debating whether to introduce a usage-based pricing tier alongside seats. Give a concrete, decisive recommendation covering: (1) the specific pricing structure you would launch, (2) how to migrate existing per-seat customers without churning them, (3) the two biggest risks and how to mitigate them, and (4) the top 3 metrics to watch in the first two quarters. Take a clear position rather than listing options.
Before generating, the models asked two sharpening questions of their own. They were told the primary goal is land-and-expand — grow expansion revenue and NRR without cannibalizing seat ARR — and that usage is metered by API calls / processed requests. That shared context is what makes this a fair fight.
The Contenders
| Model | Role | The Pitch |
|---|---|---|
| Claude Sonnet 5 | The Value Play | New, cheap, and decisive — the model this whole test was built around. |
| Claude Opus 4.8 | The Incumbent | Anthropic's flagship, twice the price. Can it justify the premium? |
| GPT-5.5 | The Maximalist | The most thorough answer by a wide margin — at the highest cost. |
| Gemini 3.1 Pro | The Efficiency King | Cheapest and fastest, with the sharpest diagnosis of the core problem. |
Round 1: Four Roads to the Same Destination
The most striking result of Round 1 was consensus. All four models independently rejected a pure usage-based tier and converged on a seat-anchored hybrid — seats as the floor, metered usage as the expansion layer. But their framing revealed their personalities.
Claude Sonnet 5 — The Decisive Diagnostician
Sonnet 5 opened by naming the trap directly:
Given your goals (expand NRR from existing accounts, don't cannibalize seat ARR, lower friction for new teams), the right move is not a parallel usage-only SKU.
Its structure — seat license floor, generous included allotment, tiered overage, soft caps with one-click auto-upgrade — was complete and unhedged. It also flagged the single biggest danger in one crisp phrase: cannibalization is a "usage tier that becomes a backdoor discount on seats." At $0.08 and 38 seconds for the round, it delivered flagship-grade judgment at a workhorse price.
Claude Opus 4.8 — The Sharpened Incumbent
Opus 4.8 reached the same hybrid conclusion, framing seats as the enduring platform fee:
The winning model here is a hybrid: seats stay as the "who has access" layer... add usage on top of seats, not replace them.
Its answer was tight and confident but, at this stage, covered similar ground to Sonnet 5 for 3x the cost ($0.07 vs $0.08 was close in R1 — the gap opened in Round 2).
GPT-5.5 — The Maximalist
GPT-5.5 wrote the longest response by far — nearly 12,800 characters in Round 1 alone, taking 82 seconds. It earned the length with vivid framing, capturing both the customer's mental model and their gaming incentive in two quotes:
"Seats let my team use the product. Usage lets my workloads scale."
"Great, now I can replace 40 seats with 3 seats and pay by API calls."
It defined named tiers ("Business Scale", "Production Scale") and insisted the billable unit be "successfully processed production API requests" — a detail the others under-specified. Thorough, but at $0.18, the priciest round-one answer.
Gemini 3.1 Pro — The Efficiency King
Gemini 3.1 Pro was fastest (20 seconds) and cheapest ($0.03), yet led with the sharpest diagnosis of all:
At $12M ARR with 40% growth, your 108% NRR is the glaring bottleneck. Best-in-class developer tools sit at 120-130% NRR. Your current per-seat model is artificially capping [expansion].
Its "Platform + Drawdown" framework was elegant, if less exhaustive than GPT-5.5's. For the money, it was the round's best value.
Round 2: The Synthesis War
Competitive Refinement's second round lets every model read the others' answers and revise. This is where intellectual humility shows. Opus 4.8 was the most explicit about borrowing:
Picking up from Round 1, my position is unchanged and now sharpened by the strongest ideas across all responses.
The convergence was measurable. Pairwise cosine similarity rose across almost every pair, and the ensemble's agreement climbed from 77.4% to 83.6%. Sonnet 5 and Gemini 3.1 Pro both added a candid "Alternative Approach" section — a ring-fenced usage-native plan for net-new logos only — showing they could hold a primary recommendation while steel-manning the alternative.
Everyone landed on the same refined architecture. Seats act as the control plane, sitting above a pooled included allotment and committed annual "Capacity Packs" as the expansion engine. Capped overage prevents bill shock, and quarterly rollover absorbs spiky developer workloads.
The Council of AI Judges
Two cheap, neutral judges — Gemini 3.5 Flash and Gemini 3.1 Flash-Lite — scored the Round 2 answers on anonymized transcripts (no model names, so no brand bias). Notably, neither judge is a contestant, and the Google judges did not favor Gemini 3.1 Pro — they ranked it last.
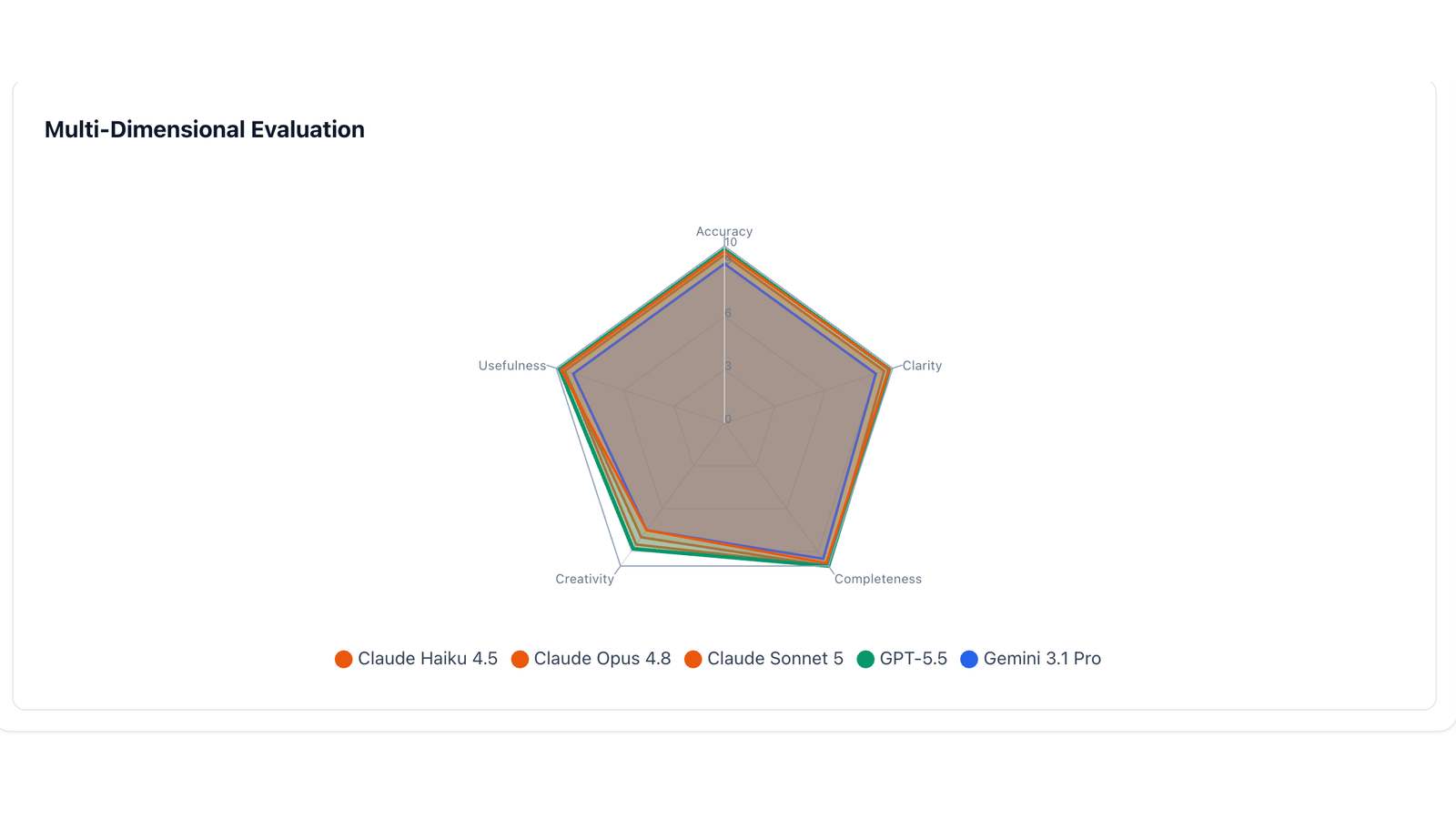
Aggregated Consensus Scores
| Model | Overall | Accuracy | Clarity | Completeness | Creativity | Usefulness |
|---|---|---|---|---|---|---|
| GPT-5.5 🏆 | 9.6 | 9.75 | 9.75 | 10 | 8.75 | 9.75 |
| Claude Sonnet 5 | 9.4 | 9.5 | 9.5 | 10 | 8.5 | 9.5 |
| Claude Opus 4.8 | 9.3 | 9.5 | 9.5 | 10 | 8.0 | 9.5 |
| Gemini 3.1 Pro | 8.8 | 9.0 | 9.0 | 9.5 | 7.5 | 9.0 |
| Claude Haiku 4.5 (synth) | 9.3 | 9.65 | 9.75 | 9.75 | 7.5 | 9.65 |
The headline: GPT-5.5 won on the strength of its thoroughness, but Sonnet 5 (9.4) edged out Opus 4.8 (9.3) — the newer, cheaper Anthropic model outscored the flagship it succeeds. The single point separating the field was creativity; on accuracy, clarity, and completeness the top three were near-identical.
Per-Judge Breakdown
Judge: Gemini 3.5 Flash
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| GPT-5.5 | 9.9 | 10 | 9.5 | 10 | 10 | 10 |
| Claude Sonnet 5 | 9.4 | 9.5 | 8.5 | 9.5 | 10 | 9.5 |
| Claude Opus 4.8 | 9.3 | 9.5 | 8.0 | 9.5 | 10 | 9.5 |
| Gemini 3.1 Pro | 9.0 | 9.0 | 8.0 | 9.0 | 10 | 9.0 |
Judge: Gemini 3.1 Flash-Lite
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| Claude Sonnet 5 | 9.4 | 9.5 | 8.5 | 9.5 | 10 | 9.5 |
| Claude Opus 4.8 | 9.3 | 9.5 | 8.0 | 9.5 | 10 | 9.5 |
| GPT-5.5 | 9.3 | 9.5 | 8.0 | 9.5 | 10 | 9.5 |
| Gemini 3.1 Pro | 8.6 | 9.0 | 7.0 | 9.0 | 9.0 | 9.0 |
Divergence analysis. The judges agreed almost perfectly on the two Claude models — Sonnet 5 (9.4/9.4) and Opus 4.8 (9.3/9.3) drew identical scores from both. GPT-5.5 was the polarizing one: Gemini 3.5 Flash called it a near-perfect 9.9, while Flash-Lite scored it 9.3 — a 0.6-point spread, the widest in the field. GPT-5.5's maximalist length is a double-edged sword: one judge read it as gold-standard thoroughness, the other as merely excellent. The stable, consistent scorers were the Claudes.
Performance Metrics: The Cost of Thoroughness
| Metric | Sonnet 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| R1 Cost | $0.0815 | $0.0651 | $0.1785 | $0.0334 |
| R2 Cost | $0.1002 | $0.2002 | $0.1730 | $0.0560 |
| Total Cost | $0.18 | $0.27 | $0.35 | $0.09 |
| R1 Time | 38s | 33s | 82s | 20s |
| R2 Time | 35s | 47s | 42s | 23s |
| Response Length | ~13,400 chars | ~14,900 chars | ~26,900 chars | ~11,300 chars |
The economics tell the real story. GPT-5.5 cost nearly 4x Gemini 3.1 Pro and 2x Sonnet 5, and it wrote more than twice as many characters as Gemini. Its win came at a genuine premium in both money and latency. Sonnet 5 delivered a top-three answer for half of Opus 4.8's Round 2 cost — Opus's second round alone ($0.20) cost more than Sonnet 5's entire two-round run ($0.18).
Similarity Matrix (Convergence)
| Pair | Round 1 | Round 2 | Trend |
|---|---|---|---|
| Opus 4.8 ↔ Gemini 3.1 Pro | 0.77 | 0.87 | Converging |
| Opus 4.8 ↔ GPT-5.5 | 0.74 | 0.83 | Converging |
| Sonnet 5 ↔ GPT-5.5 | 0.76 | 0.82 | Converging |
| Sonnet 5 ↔ Opus 4.8 | 0.81 | 0.87 | Converging |
| GPT-5.5 ↔ Gemini 3.1 Pro | 0.72 | 0.81 | Converging |
| Sonnet 5 ↔ Gemini 3.1 Pro | 0.82 | 0.82 | Flat |
Every pair except one moved closer in Round 2. This is Competitive Refinement working as designed: exposed to each other's best ideas, the models absorbed the strongest arguments and sanded down the weak ones.
The Verdict
🏆 GPT-5.5 is the judges' winner — the most complete, best-specified answer, the only one that nailed the exact billable unit and modeled the customer's gaming incentive. If you want the single most thorough strategy document and cost is no object, it's the pick.
But the real story is Claude Sonnet 5. It outscored the flagship Opus 4.8 at roughly two-thirds the cost and half the Round 2 spend, with the crispest articulation of the cannibalization risk. For teams running multi-round ensembles where every model's tokens compound, Sonnet 5 changes the math: near-frontier judgment without frontier pricing.
Claude Opus 4.8 remains excellent and drew the most consistent scores, but this run gives you a reason to reach for it deliberately rather than by default. Gemini 3.1 Pro is the value champion for single-shot work — fastest, cheapest, and home to the single best problem diagnosis ("108% NRR is the glaring bottleneck"), even if its shorter answers cost it on the completeness axis.
Strategic takeaway: the frontier is compressing. A brand-new mid-tier model beat last generation's flagship on a hard reasoning task, and a cheap model wrote the sharpest one-line diagnosis. In an ensemble, the winning move is no longer "use the most expensive model everywhere" — it's matching model tier to the job and letting refinement close the gap.
Final Response
The arbiter, Claude Haiku 4.5, synthesized the four answers into a single playbook:
### Synthesized Recommendation: Hybrid Seat-Anchored Pricing with Usage Expansion
**Core principle:** Seats monetize people and collaboration. Usage monetizes production workload scale. Usage is additive expansion, never a replacement for seats.
**Three-part structure:**
- Mandatory seat subscription (unchanged in principle): developer access, RBAC, SSO, audit logs, admin controls. This is your ARR floor and protects predictability.
- Included pooled monthly request allotment per seat (account-wide pool). A 60-seat Business customer gets a large pooled budget; steady-state customers should never see a usage bill.
- Committed annual Capacity Packs (the expansion engine): pre-purchased annual request blocks at declining marginal rates (e.g., $0.32/1k → $0.20/1k as volume climbs). Cash-good upfront contracts that directly improve NRR.
- Capped overage with a 125-150% ceiling: premium on-demand pricing 30-40% above committed packs, with a hard cap that triggers a commercial-review workflow instead of silent bill shock. Alerts at 70%, 90%, 100%, 120%.
- Quarterly rollover on committed usage: absorbs launch/incident/batch spikes and prevents month-to-month variance anger — a cheap trust concession with outsized retention value.
- New lightweight entry tier that auto-graduates to Business, reducing friction for net-new adoption without becoming a discount substitute for core tiers.
That final answer scored 9.3/10 from the judges — the cheap Haiku arbiter distilled four flagship responses into a synthesis that beat one of the flagships outright.
Try It Yourself
- Open the AI Crucible dashboard.
- Select Claude Sonnet 5, Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro.
- Choose Competitive Refinement with 2 rounds and a cheap arbiter (Claude Haiku 4.5).
- Paste a decision-forcing business prompt and compare.
Suggested prompt variation:
You are advising the CEO of a [stage] [industry] company ([key metrics]).
They are debating [specific strategic decision].
Give a concrete, decisive recommendation covering the structure, the rollout,
the two biggest risks, and the top 3 metrics to watch in the first two quarters.
Take a clear position rather than listing options.
Explore the Debate: Read the full 2-round debate and analyze the raw model outputs yourself in the Shared Chat Session.
Further Reading
- The Competitive Refinement Strategy — How the dialectical, multi-round methodology works under the hood.
- Claude Fable 5 vs Opus 4.8 vs GPT-5.5: Rate Limiter — The same flagships on a hard engineering task.
- Cheaper Frontier: Hierarchical Orchestration — Matching model tier to job to cut cost without losing quality.