Claude Fable 5's First Benchmark: A New Tier Meets Its Rivals
Anthropic's Claude Fable 5 is the company's first model positioned above Opus — a new flagship tier priced at $10/$50 per million tokens with a 1M context window. We added it to AI Crucible the day it landed and threw it straight into a four-way ensemble against Claude Opus 4.8, Claude Sonnet 4.6, and OpenAI's GPT-5.5. The newcomer answered 4.2× faster than GPT-5.5 and tied for the best accuracy score. It still did not win the round.
Time to read: 9–12 minutes
Session cost: Approx. $1.03 (1 round + arbiter synthesis + 2-judge evaluation)
| Parameter | Value |
|---|---|
| Strategy | Competitive Refinement |
| Rounds | 1 |
| Web Search | Disabled |
| Arbiter | Grok 4.3 |
| Models | Claude Fable 5, Claude Opus 4.8, Claude Sonnet 4.6, GPT-5.5 |
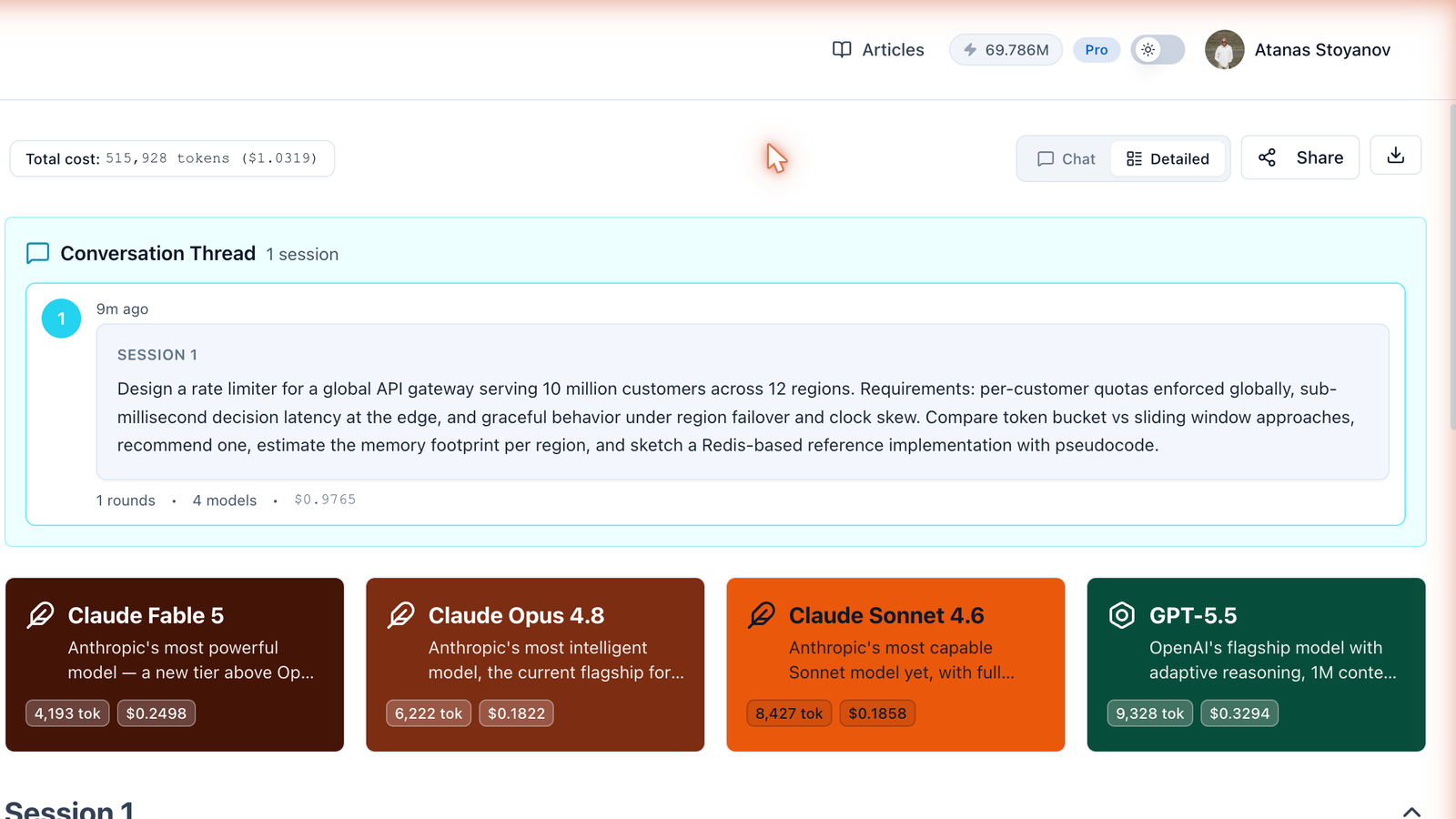
Why Is a Rate Limiter the Perfect Flagship Test?
We wanted a prompt that punishes retrieval and rewards genuine systems reasoning. Distributed rate limiting is a classic trap: the naive answer (a global Redis counter) is physically impossible at the stated latency budget. A model has to notice the contradiction, reframe the problem, and still deliver concrete numbers and code.
Design a rate limiter for a global API gateway serving 10 million customers across 12 regions. Requirements: per-customer quotas enforced globally, sub-millisecond decision latency at the edge, and graceful behavior under region failover and clock skew. Compare token bucket vs sliding window approaches, recommend one, estimate the memory footprint per region, and sketch a Redis-based reference implementation with pseudocode.
Who Were the Contenders?
| Model | Role | The Pitch |
|---|---|---|
| Claude Fable 5 | The New Tier | Anthropic's most powerful model, debuting above Opus for the first time. |
| Claude Opus 4.8 | The Incumbent Flagship | The reigning Anthropic workhorse for agents and complex reasoning. |
| Claude Sonnet 4.6 | The Value Pick | A third of the price of Opus, with a reputation for punching up. |
| GPT-5.5 | The Heavyweight | OpenAI's flagship with adaptive reasoning and a taste for exhaustiveness. |
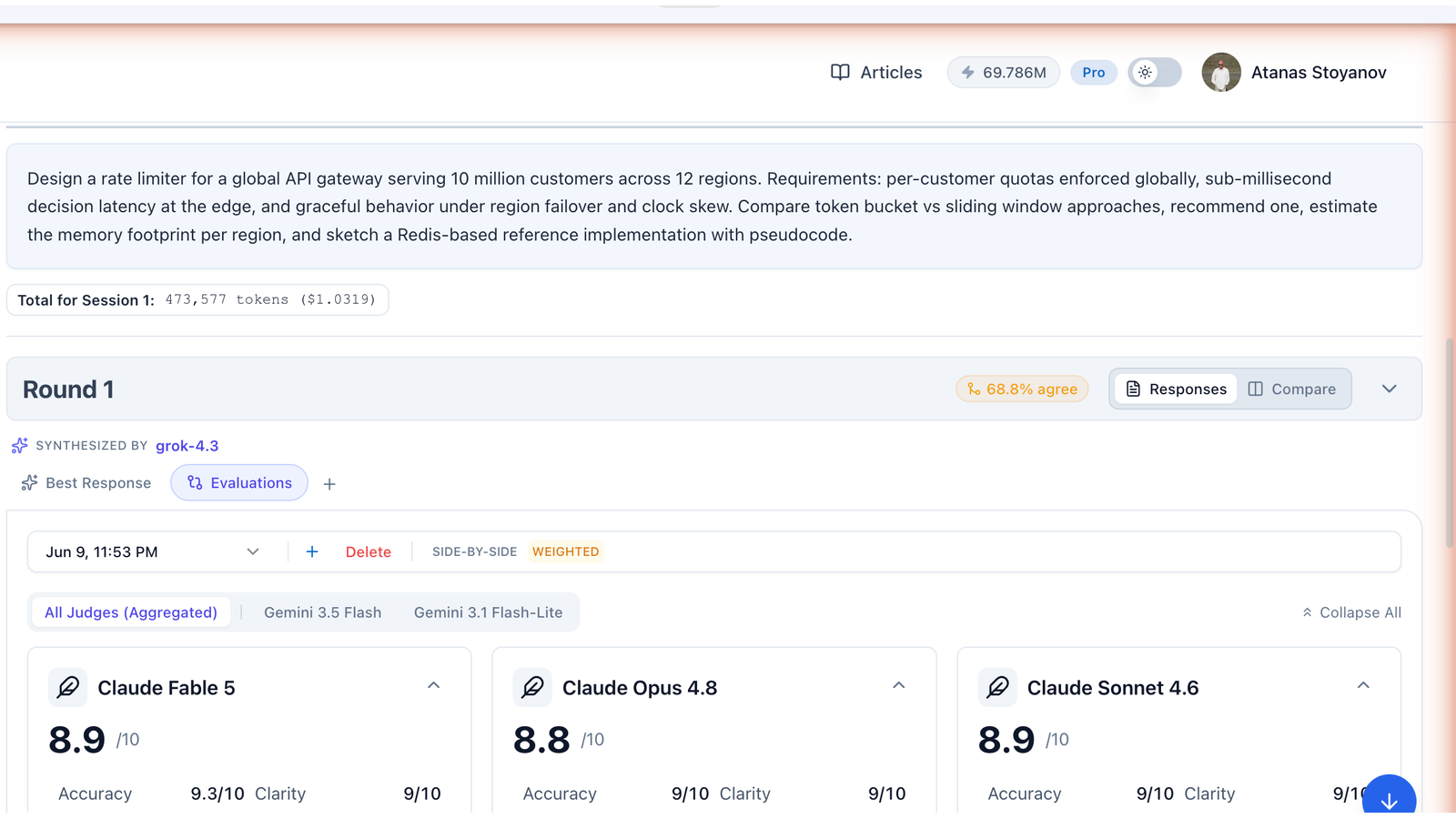
Round 1: Four Models, One Identical Insight
Here is the headline finding before any judge weighed in. All four models independently rejected the literal framing of the question. None of them debated token bucket vs sliding window as the core problem. Every single one reframed it as a quota distribution problem and designed the same three-tier architecture: a global allocator leasing quota to regions, with edge nodes spending micro-leases locally.
The agreement badge for the round: 68.8%.
Claude Fable 5: "Lease, Don't Lock"
Fable 5 led with the most opinionated framing of the four, under the title "Lease, Don't Lock":
Most designs fail because they try to make a globally consistent decision on the hot path. With sub-millisecond latency required at the edge and 12 regions, that's physically impossible — speed of light gives you ~30–150ms cross-region RTT.
Its signature line — "treat quota like cash, not like a lock" — compressed the entire architecture into seven words. The memory estimate was equally crisp:
10M customers × ~110 B ≈ 1.1 GB, call it 1.5–2 GB with fragmentation and replication buffers.
The trade-off: Fable 5 wrote the shortest answer of the four (9,190 characters, 3,852 completion tokens) and finished in 51 seconds. It chose density over coverage — a choice that would matter when the judges scored completeness.
Claude Opus 4.8: Naming the Contradiction
Opus 4.8 opened by naming the tension explicitly, then introduced the lease-and-reconcile vocabulary the arbiter would later adopt:
So the real design question is not "token bucket vs sliding window" — it's "how much quota precision are you willing to trade for latency, and where do you put the imprecision?"
It was the only model to push its memory estimate past raw struct math, noting Redis hash overhead realistically lands at "~150–200 bytes" per customer. At $0.1822 it was also the cheapest response in the round — the incumbent flagship delivered the best cost-to-depth ratio.
Claude Sonnet 4.6: The Academic Reframe
Sonnet 4.6 produced the most conceptually distinctive framing, calling the task a "quota arbitrage problem under partial observability":
You can't have global consistency and sub-millisecond latency simultaneously—the speed of light makes it physically impossible across 12 regions. The real design goal is: bounded over-admission with deterministic latency guarantees and graceful degradation curves, not strict global counting.
It went deepest on clock skew, specifying a ±500ms tolerance window with monotonic sequence numbers for lease validation. It also wrote until it hit its 8,192-token output cap — thoroughness with a hard ceiling.
GPT-5.5: Quota as Currency
GPT-5.5 delivered the longest answer (21,078 characters) and the most production-shaped one, complete with a GCRA-style variant and explicit failover budgets:
Quota as currency. Globally mint tokens, lease them to regions, spend them locally.
It was the only model to formalize the invariant being traded for: enforcement "with a deterministic, small, configurable overshoot bound." The cost of that exhaustiveness: 214.5 seconds — more than four times slower than Fable 5 — and the highest price in the round at $0.3294.
How Similar Were the Four Answers?
Cosine similarity between responses confirms what reading them suggests. The two Anthropic flagships think alike; Sonnet 4.6 is the stylistic outlier.
| Pair | Round 1 | Reading |
|---|---|---|
| Fable 5 ↔ Opus 4.8 | 0.83 | Closest pair — shared lease vocabulary |
| Fable 5 ↔ GPT-5.5 | 0.71 | Same architecture, different register |
| Opus 4.8 ↔ GPT-5.5 | 0.71 | Same architecture, different register |
| Sonnet 4.6 ↔ GPT-5.5 | 0.65 | Diverging structure |
| Opus 4.8 ↔ Sonnet 4.6 | 0.63 | Diverging structure |
| Fable 5 ↔ Sonnet 4.6 | 0.62 | Most distant pair |
The 0.83 between Fable 5 and Opus 4.8 is worth dwelling on. The new tier does not think differently from Opus — it thinks the same way, faster and in fewer words.
What Did the Council of AI Judges Decide?
We scored the round with two independent judges — Gemini 3.5 Flash and Gemini 3.1 Flash-Lite — using AI Crucible's evaluation pipeline. Judges receive anonymized transcripts: no model names, no provider hints.
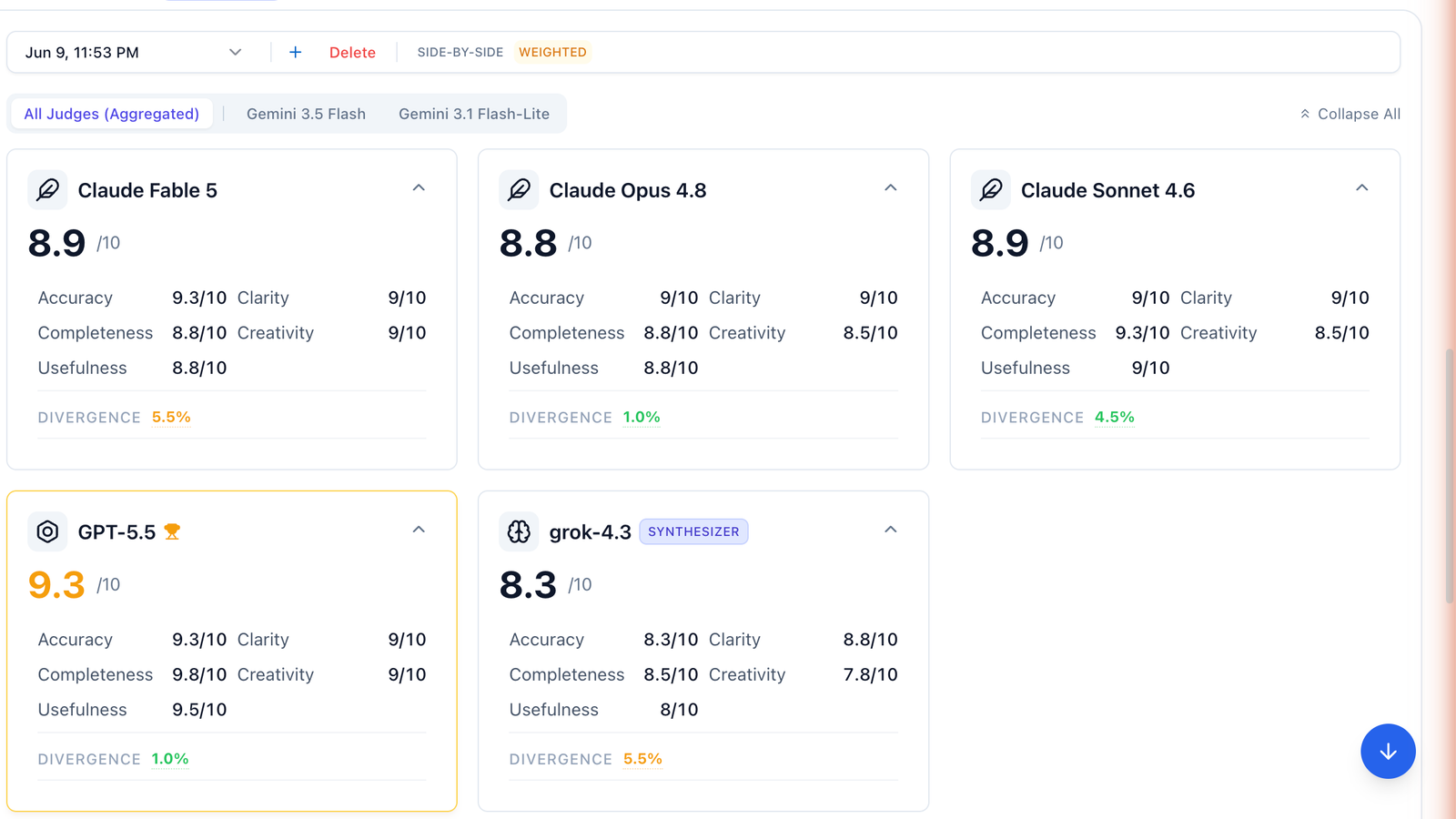
Aggregated Consensus Scores
| Model | Overall | Accuracy | Clarity | Completeness | Creativity | Usefulness | Divergence |
|---|---|---|---|---|---|---|---|
| GPT-5.5 🏆 | 9.3 | 9.3 | 9.0 | 9.8 | 9.0 | 9.5 | 1.0% |
| Claude Fable 5 | 8.9 | 9.3 | 9.0 | 8.8 | 9.0 | 8.8 | 5.5% |
| Claude Sonnet 4.6 | 8.9 | 9.0 | 9.0 | 9.3 | 8.5 | 9.0 | 4.5% |
| Claude Opus 4.8 | 8.8 | 9.0 | 9.0 | 8.8 | 8.5 | 8.8 | 1.0% |
| Grok 4.3 (synthesis) | 8.3 | 8.3 | 8.8 | 8.5 | 7.8 | 8.0 | 5.5% |
GPT-5.5 won on the dimensions that reward length: completeness (9.8) and usefulness (9.5). Fable 5 tied it on accuracy (9.3) — the highest of any model — while writing 56% fewer characters.
Judge-by-Judge Breakdown
Judge: Gemini 3.5 Flash
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| GPT-5.5 | 9.4 | 9.5 | 9.0 | 9.0 | 10.0 | 9.5 |
| Claude Sonnet 4.6 | 9.4 | 9.5 | 9.0 | 9.5 | 9.5 | 9.5 |
| Claude Opus 4.8 | 8.7 | 9.0 | 8.5 | 9.0 | 8.5 | 8.5 |
| Claude Fable 5 | 8.4 | 9.0 | 8.5 | 8.5 | 8.0 | 8.0 |
Judge: Gemini 3.1 Flash-Lite
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| Claude Fable 5 | 9.5 | 9.5 | 9.5 | 9.5 | 9.5 | 9.5 |
| GPT-5.5 | 9.2 | 9.0 | 9.0 | 9.0 | 9.5 | 9.5 |
| Claude Opus 4.8 | 8.9 | 9.0 | 8.5 | 9.0 | 9.0 | 9.0 |
| Claude Sonnet 4.6 | 8.5 | 8.5 | 8.0 | 8.5 | 9.0 | 8.5 |
Which Model Split the Judges?
Fable 5 polarized the panel more than any other contender. Gemini 3.5 Flash ranked it last at 8.4; Gemini 3.1 Flash-Lite ranked it first at 9.5 — a 1.1-point spread, the largest in the round. Sonnet 4.6 showed a 0.9-point spread in the opposite direction. GPT-5.5 was the consensus pick, scoring 9.4 and 9.2 with both judges.
That split maps cleanly onto the density-versus-coverage divide. A judge that rewards exhaustive coverage docks Fable 5 for brevity. A judge that rewards signal-per-token puts it on top. Its 5.5% divergence score — highest among the contenders — quantifies the same disagreement.
What Did the Performance Numbers Say?
| Metric | Claude Fable 5 | Claude Opus 4.8 | Claude Sonnet 4.6 | GPT-5.5 |
|---|---|---|---|---|
| Time | 51.1s | 83.1s | 144.7s | 214.5s |
| Cost | $0.2498 | $0.1822 | $0.1858 | $0.3294 |
| Output Tokens | 3,852 | 5,881 | 8,192 (cap) | 9,113 |
| Response Length | ~9,200 chars | ~15,300 chars | ~21,100 chars | ~21,100 chars |
Two things stand out. First, Fable 5 is the priciest model per token in the lineup, yet its terseness landed it mid-pack on actual cost. Second, the speed gap is dramatic: Fable 5 finished before any rival had reached its halfway point.
What Did the Arbiter Synthesize?
Grok 4.3, acting as a neutral arbiter, merged the four answers into a single recommendation. The synthesis adopted Opus 4.8's lease-and-reconcile vocabulary and the unanimous token-bucket verdict.
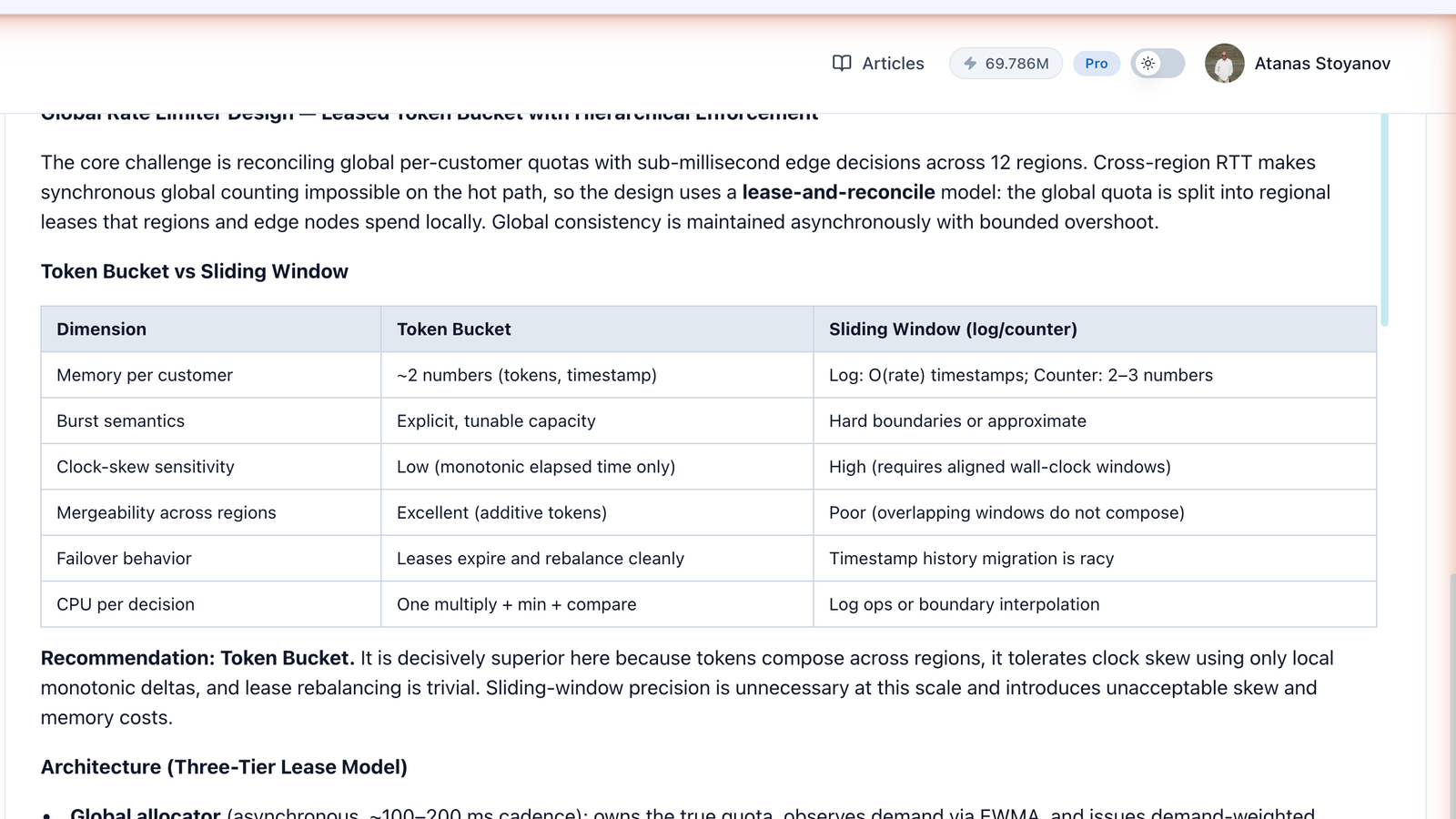
### Global Rate Limiter Design — Leased Token Bucket with Hierarchical Enforcement
The core challenge is reconciling global per-customer quotas with sub-millisecond edge decisions across 12 regions. Cross-region RTT makes synchronous global counting impossible on the hot path, so the design uses a lease-and-reconcile model: the global quota is split into regional leases that regions and edge nodes spend locally. Global consistency is maintained asynchronously with bounded overshoot.
### Recommendation: Token Bucket
It is decisively superior here because tokens compose across regions, it tolerates clock skew using only local monotonic deltas, and lease rebalancing is trivial. Sliding-window precision is unnecessary at this scale and introduces unacceptable skew and memory costs.
### Architecture (Three-Tier Lease Model)
Global allocator (asynchronous, ~100–200 ms cadence): owns the true quota, observes demand via EWMA, and issues demand-weighted regional leases with hysteresis and a small emergency budget.
The Verdict
🏆 GPT-5.5 takes the round at 9.3/10. When the brief says "sketch a reference implementation," exhaustiveness wins judged evaluations. It shipped failover budgets, a GCRA variant, and capacity math the judges rewarded with a 9.8 completeness score. Budget four minutes and a third of a dollar for it.
Claude Fable 5 (8.9) is the story of the session, though. On debut it posted the fastest time, the joint-best accuracy, and the most quotable engineering judgment of the four. Its answer reads like a staff engineer's whiteboard talk: every sentence is load-bearing. If you bill by the token or wait on the response, that profile is compelling — just know that judges scoring completeness will want more prose.
Claude Sonnet 4.6 (8.9) remains the value anomaly. It matched the new flagship's consensus score at a third of Fable 5's per-token price, and one judge ranked it first outright. Its output cap is the real constraint on tasks like this.
Claude Opus 4.8 (8.8) turned in the cheapest response and the lowest judge disagreement. It no longer leads Anthropic's lineup, but as the dependable middle of this panel it remains an excellent default.
Strategic takeaway: Fable 5 establishes a real tier above Opus, but its advantage is efficiency, not raw scores — same architecture as Opus 4.8 (0.83 similarity), 40% faster, 35% fewer tokens. Teams should match models to constraints: GPT-5.5 for exhaustive design documents, Fable 5 for fast expert judgment, Sonnet 4.6 for budget-bound depth.
Frequently Asked Questions
Is Claude Fable 5 better than Claude Opus 4.8?
On this benchmark, Fable 5 scored marginally higher (8.9 vs 8.8), answered 40% faster, and tied for the best accuracy of all four models. Their answers were highly similar (0.83 cosine similarity), so the practical difference is speed and density, not architecture or insight.
Why did GPT-5.5 win if Fable 5 had the best accuracy?
The judges weighted completeness and usefulness heavily. GPT-5.5's 21,000-character answer earned a 9.8/10 completeness score, while Fable 5's deliberately terse 9,200-character answer scored 8.8 there. Accuracy was a tie at 9.3.
How much does Claude Fable 5 cost compared to the other models?
On AI Crucible, Fable 5 runs $12/$60 per million tokens (input/output), versus $6/$30 for Opus 4.8 and $3.60/$18 for Sonnet 4.6. Because it wrote the shortest answer, its actual round cost ($0.25) landed between Opus 4.8 ($0.18) and GPT-5.5 ($0.33).
Try It Yourself
- Open the AI Crucible dashboard and select Claude Fable 5, Claude Opus 4.8, Claude Sonnet 4.6, and GPT-5.5.
- Pick the Competitive Refinement strategy with one round and a neutral arbiter such as Grok 4.3.
- Paste a systems-design prompt with a built-in contradiction and compare how each model resolves it.
Suggested prompt variation:
Design a distributed job scheduler for 50,000 worker nodes across 8 regions.
Requirements: exactly-once execution, sub-second scheduling latency, and
graceful behavior during network partitions. Compare optimistic locking vs
leader election, recommend one, estimate coordination overhead, and sketch
a reference implementation with pseudocode.
Explore the Debate: Read the full round and analyze the raw model outputs yourself in the Shared Chat Session.
Further Reading
- The Competitive Refinement Strategy — How the dialectical methodology behind this benchmark works.
- GPT-5.4 vs Claude Opus 4.6 vs Gemini 3.1 Pro: Flagship Showdown — The previous generation of this matchup.
- Claude Sonnet 4.6 vs Qwen 3.5 Plus vs Kimi K2.5 — How the value pick fares against Chinese flagships.