Two brand-new models just entered the arena: Anthropic's Claude Sonnet 4.6 and Alibaba's Qwen 3.5 Plus. We threw them straight into a Competitive Refinement battle alongside Kimi K2.5 to see how they handle one of the toughest real-world prompts we could design: building a comprehensive project management framework for a struggling multi-team portfolio.
Then we handed the anonymous transcripts to three independent AI judges. The results surprised us.
The Challenge
We crafted a prompt that would push models beyond surface-level advice and into the territory of genuine strategic thinking:
The Scenario:
- Managing a portfolio of interdependent projects across engineering, product, marketing, and operations
- Cascading failures: scope creep, timeline delays, resource conflicts, and misaligned stakeholders
- Projects are increasingly missing deadlines and budgets
- The Ask: A comprehensive PM framework covering initiation, planning, execution, communication, risk management, monitoring, methodology selection, and technology stack
This isn't a question you can answer with a few bullet points. It requires deep knowledge of PERT, Monte Carlo estimation, earned value management, and change control—while still being creative enough to go beyond the textbook.
The Contenders
| Model | Role | The Pitch |
|---|---|---|
| Claude Sonnet 4.6 | The Architect | Anthropic's latest Sonnet, upgraded across coding, reasoning, and agent planning. |
| Qwen 3.5 Plus | The Systems Thinker | Alibaba's new hybrid MoE flagship (397B total / 17B active), just launched. |
| Kimi K2.5 | The Complexity Scientist | Moonshot AI's multimodal agent with a 1M-token context and novel perspectives. |
Round 1: Three Philosophies of Control
Each model invented its own branded framework. The philosophical differences were striking.
Claude Sonnet 4.6: The Adaptive Portfolio Operating System (APOS)
Sonnet 4.6 opened with a manifesto-length response (33,000+ characters) that reads like a senior VP of Engineering wrote it over a long weekend. Its framework, APOS, is built on three principles:
"Uncertainty Is Data, Not Failure. A project manager who says 'I'm 60% confident in this timeline' is more valuable than one who says 'we're on track' and delivers late."
Sonnet introduced the PRISM business case format (Problem, Result, Investment, Strategic alignment, Minimum viable version) and a sophisticated dependency mapping system using influence/alignment matrices. The response was exhaustively detailed, with copy-pasteable templates for everything from escalation ladders to change impact calculators.
The tradeoff: At $0.12 for this single response and 184 seconds of generation time, it's the Rolls-Royce of answers—beautiful but expensive.
Qwen 3.5 Plus: The Neuro-Synaptic Portfolio Framework (NSPF)
In its debut battle, Qwen 3.5 Plus immediately distinguished itself with the most creative metaphor of the set: treating the portfolio as a neural network where projects are nodes and dependencies are synaptic connections.
"Stop assigning specific people to specific projects months in advance. Create Capability Pods. Projects bid for time slices from these pods based on priority weighting."
Qwen introduced SMART-D goals (Dynamic SMART goals with built-in pivot triggers), Monte Carlo simulations for probabilistic timelines, and Liquid Resource Pools—an internal talent marketplace that creates price signals for resource scarcity. The framework was elegant, accessible, and immediately actionable.
The standout: The Pre-Mortem Protocol and Stakeholder Empathy Mapping (replacing traditional RACI matrices with pain-point analysis) showed a model that thinks in systems, not checklists.
Kimi K2.5: The Adaptive Portfolio Orchestration (APO) Framework
Kimi K2.5 came in swinging with complexity science vocabulary, framing the portfolio challenge through the Cynefin framework's Complex Domain where cause and effect are only coherent in retrospect.
"Your portfolio isn't a collection of separate projects—it's an ecosystem of entangled complexity."
Kimi proposed Vector Goals (direction + momentum metrics instead of static targets), graph-based dependency management using DAGs with health scores, and an innovative Circuit Breaker pattern borrowed from distributed systems engineering. It also introduced Anti-Goal Definition—explicitly documenting what success doesn't look like.
The edge: The Red Team War Gaming concept (a separate group tries to "kill" the project within 48 hours using realistic constraints) was the most original risk management idea across all three responses.
Round 2: The Synthesis War
In Competitive Refinement, Round 2 is where models see each other's responses and must improve. This is the real test of intellectual humility and synthesis ability.
Claude Sonnet 4.6 produced the Integrated Portfolio Operating System (IPOS), absorbing Qwen's "Change Budget" concept and Kimi's leading indicators into its existing architecture. It explicitly acknowledged what each competitor brought to the table while maintaining its exhaustive, template-heavy style.
Qwen 3.5 Plus evolved into the Resilient Portfolio Operating System (R-POS), merging its neural metaphor with Sonnet's structural rigor and Kimi's graph-based risk modeling. The result was arguably the most balanced framework—systems thinking with practical guardrails.
Kimi K2.5 refined its approach into a unified RPOS framework, adopting the PRISM+ business case format from Sonnet and Qwen's Monte Carlo estimation approach while keeping its signature complexity science lens.
The Council of AI Judges
We didn't just trust our own assessment. We submitted the anonymous transcripts to a panel of three independent AI judges: Gemini 3 Pro, GPT-5.2, and Mistral Large 3—none of which were contestants.
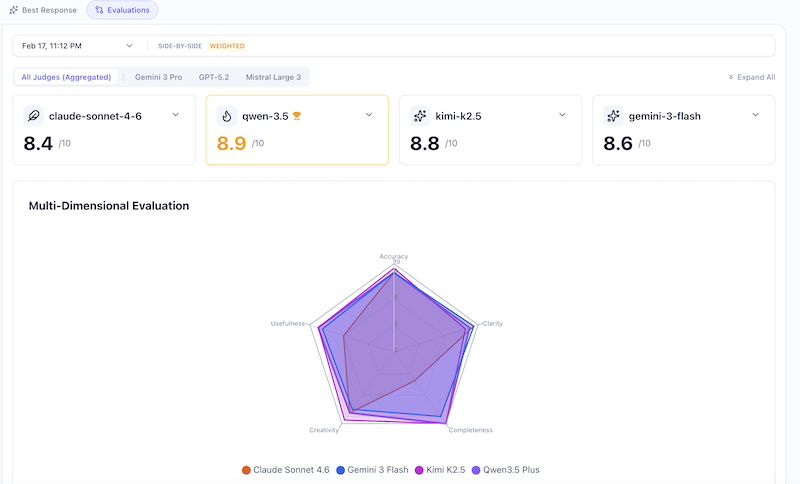
Aggregated Scores
| Model | Overall | Accuracy | Clarity | Completeness | Creativity | Usefulness |
|---|---|---|---|---|---|---|
| Qwen 3.5 Plus 🏆 | 8.9 | 8.7 | 8.9 | 9.4 | 8.9 | 8.7 |
| Kimi K2.5 | 8.8 | 8.8 | 8.2 | 9.4 | 9.4 | 8.4 |
| Claude Sonnet 4.6 | 8.2 | 9.1 | 9.1 | 6.9 | 8.4 | 7.8 |
The headline: Qwen 3.5 Plus wins its debut evaluation, edging out Kimi K2.5 by a hair and beating Claude Sonnet 4.6 by a significant margin. The divergence score of 8.7% for Sonnet indicates the judges disagreed most about its quality—a pattern worth exploring.
Judge-by-Judge Breakdown
Gemini 3 Pro (Judge 1)
Gemini 3 Pro was the harshest critic of Claude Sonnet 4.6, awarding it only 7.4/10 with a devastating 4/10 for Completeness:
"The response is critically flawed because it is incomplete. It cuts off mid-sentence in the 'Project Monitoring' section, completely failing to address the final two requirements of the prompt."
In contrast, Gemini gave Qwen 3.5 Plus a 9.1/10 and Kimi K2.5 a 9.3/10, praising Kimi's "exceptionally comprehensive and sophisticated framework" while noting Qwen's "balanced and highly readable response" with "clear headings and practical examples."
GPT-5.2 (Judge 2)
GPT-5.2 was more evenly distributed, scoring all models between 8.1 and 8.4. It praised Sonnet's "coherent narrative and strong organization" but dinged it for "slightly vague metrics" and "accuracy weakened by a few overclaimed/undefined metrics." It rated Qwen's response as "well-structured and logically organized" while noting Kimi's exceptional creativity (9.5/10) but slightly lower clarity.
Mistral Large 3 (Judge 3)
Mistral Large 3 was the most generous judge, giving Claude Sonnet 4.6 a 9.5/10 with a perfect 10/10 for Completeness:
"Exceptionally accurate and detailed. The 'Three Laws of Portfolio Health' and 'Capacity Reality Model' are particularly well-justified."
It rated Qwen 3.5 Plus at 9.4/10, praising its "factually robust" response and "innovative adaptations (Monte Carlo framing, graph-based dependency management)." Kimi K2.5 received 8.9/10, with Mistral noting the "highly practical" actionable templates but less depth in execution compared to Sonnet.
What the Divergence Tells Us
The 8.7% divergence on Sonnet 4.6 is the most revealing metric. Gemini gave it 7.4; Mistral gave it 9.5. Why? Sonnet's 33,000-character response was so long that it appears to have been truncated in some judges' views—Gemini flagged the incompleteness explicitly, while Mistral (which may have received the full response) called it the best.
This highlights a real-world lesson: more isn't always better. A response can be brilliant in the first 10,000 characters but lose points if it runs so long that critical sections get cut off.
The Performance Metrics
| Metric | Claude Sonnet 4.6 | Qwen 3.5 Plus | Kimi K2.5 |
|---|---|---|---|
| Total Cost | $0.26 | $0.02 | $0.03 |
| Total Time | 376s (6.3 min) | 62s (1 min) | 84s (1.4 min) |
| Response Length | ~33,000 chars/round | ~11,000 chars | ~10,000 chars |
The cost disparity is staggering. Qwen 3.5 Plus delivered the highest-rated response at 1/13th the cost of Claude Sonnet 4.6 and in 1/6th the time. For teams running frequent evaluations or batch comparisons, this represents a meaningful cost advantage.
The Verdict
Qwen 3.5 Plus: The Value Champion 🏆
In its first-ever AI Crucible evaluation, Qwen 3.5 Plus proved it can compete with—and beat—models that cost 10x more. Its strength lies in systems thinking made accessible: the "neural network" metaphor, Liquid Resource Pools, and Pre-Mortem Protocol are not just creative—they're immediately implementable. At $0.40/M input tokens, it's positioned as a serious contender for complex reasoning tasks.
Claude Sonnet 4.6: Brilliant but Verbose
Sonnet 4.6 demonstrated the deepest operational knowledge of any model in this test. Its templates, escalation ladders, and change impact calculators are production-ready artifacts. But its verbosity was a double-edged sword: two of three judges couldn't fully evaluate the response because of length truncation. When judges could see the full response, it scored highest.
Use Sonnet 4.6 when: You need exhaustive, template-level detail and have the budget for premium reasoning.
Kimi K2.5: The Creative Powerhouse
Kimi K2.5 scored the highest individual creativity rating (9.5/10 from Mistral) and brought genuinely novel concepts like Vector Goals, DAG-based dependency graphs, and Circuit Breaker patterns. At $0.03 total cost, it's the most creative dollar-for-dollar option available.
Use Kimi K2.5 when: You need lateral thinking, unconventional frameworks, and unique perspectives at minimal cost.
Strategic Takeaway
This battle demonstrates a broader trend: the cost of frontier-quality reasoning is collapsing. A year ago, outputs of this quality required $10+ per session with the top proprietary models. Today, Qwen 3.5 Plus delivers competitive results for two cents.
The real winner? Teams that leverage Competitive Refinement with a diverse model mix—using each model's strengths to pressure-test the others.
Further Reading
- The Competitive Refinement Strategy — Learn more about the methodology used in this evaluation.
- Opus 4.6 vs Gemini 3 Pro vs Kimi K2.5: Email Marketing — See how the bigger Opus 4.6 handles a marketing challenge.
- Chinese Models Comparison — A deeper look at Qwen, Kimi, and DeepSeek.
- Evaluations in AI Crucible — How our multi-judge evaluation system works.