OpenAI's freshly minted GPT-5.4 just landed on AI Crucible, and we wasted no time throwing it into the ring against Anthropic's Claude Opus 4.6 and Google's Gemini 3.1 Pro. The stakes: a complex entrepreneurship challenge that demands market analysis, creative strategy, and actionable financial planning. The result? A razor-thin margin, a split jury, and a fascinating study in how three very different AI philosophies tackle the same problem.
Time to read: 10-15 minutes
Session cost: Approx. $1.74 (2 rounds + arbiter synthesis)
| Parameter | Value |
|---|---|
| Strategy | Competitive Refinement |
| Rounds | 2 |
| Web Search | Disabled |
| Arbiter | Gemini 2.5 Flash |
| Models | GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro |
The Challenge: Build a Business from Scratch
We gave all three models a prompt designed to test real-world strategic thinking — not trivia, not coding, not benchmarkable math. Pure ambiguity:
As an entrepreneur with a background in creative technology and strong interpersonal skills, I am seeking innovative, non-generic business ventures that leverage these combined strengths. The ideal ventures should be fully remote, highly scalable, and require under $10,000 in initial investment.
This is the kind of prompt that separates models that retrieve from models that reason. There's no single correct answer — just better and worse frameworks for navigating uncertainty.
The Contenders
| Model | Role | The Pitch |
|---|---|---|
| GPT-5.4 | The Tactician | OpenAI's newest flagship: pragmatic, direct, no-nonsense. |
| Claude Opus 4.6 | The Architect | Anthropic's deep thinker: exhaustive, market-aware, polished. |
| Gemini 3.1 Pro | The Speed Demon | Google's latest: fastest to respond, leanest on cost. |
Round 1: Opening Salvos
GPT-5.4 — The Anti-Fluff Machine
GPT-5.4 wasted zero words on pleasantries. It opened with a thesis statement that cut straight to the jugular:
You're not just "technical" and not just "good with people." Your edge is likely translating complexity into experiences other people can understand, buy, and use.
Then it dropped a full venture ranking table in the first 500 words — complete with startup costs, 12–18 month scale paths, and core moats. Its top recommendation: a Niche Operating System Studio, building systematized workflows for specific industries. The approach was structured as a clear pipeline: sell an outcome now → systematize it → turn the repeatable parts into product, subscription, data, or community.
GPT-5.4's Round 1 was 35,670 characters — the longest response by far — but remarkably dense. Every paragraph earned its place.
Cost: $0.12 | Time: 43s
Claude Opus 4.6 — The Market Contextualist
Claude opened with something the other models skipped entirely: current market sizing. Before recommending a single venture, it laid out the landscape:
The creator economy has ballooned to approximately $200+ billion globally in 2025. AI tools have democratized capabilities that once required entire teams, and businesses are desperately seeking guides to navigate this transformation.
Claude's core insight was sharper than a spreadsheet: "the gap between what AI tools can do and what most businesses understand about them is your entire business model." Its recommendations leaned heavily on the "translation layer" concept — positioning the entrepreneur as an AI integration guide for traditional businesses.
Cost: $0.17 | Time: 119s
Gemini 3.1 Pro — The Efficiency Sprint
Gemini delivered a crisp, well-organized response in a fraction of the time. Its framing zeroed in on a key moat concept:
In an era dominated by AI and automation, your "moat" is using technology to scale authentic human connection and creativity.
Its top pick was an Executive "Digital Twin" Architecture — helping thought leaders scale their personal brand through AI-powered content systems. Inventive and differentiated, but the shortest response at 15,960 characters left some strategic depth on the table.
Cost: $0.02 | Time: 8.5s
Round 2: The Refinement War
In Competitive Refinement, each model sees the others' Round 1 responses before writing Round 2. This is where intellectual humility — or stubbornness — reveals itself.
GPT-5.4 — Sharpened, Not Softened
GPT-5.4 absorbed the cross-pollination and distilled the best ideas into a tighter framework. It adopted Claude's "translation and trust" language while keeping its own pragmatic backbone:
You can turn messy human judgment into digital experiences and systems people actually trust and use.
Its final top pick shifted to a Decision Infrastructure Studio — a fusion of its original "Operating System" concept with Claude's emphasis on guided decision-making experiences. The result was arguably the most actionable venture pitch in the entire session: structured tables with cost ranges, scale paths, and moat definitions.
Cost: $0.20 | Time: 43s
Claude Opus 4.6 — Going Deeper
Claude expanded massively in Round 2, delivering 32,355 characters — the longest response of the entire session. Rather than just refining, Claude rebuilt its entire framework from the ground up, incorporating the best elements of both competitors' approaches:
Your real competitive advantage isn't "creative technology" or "interpersonal skills" separately. It's the specific thing that happens when they combine: you can take messy, ambiguous, high-stakes human decisions and turn them into structured, elegant digital experiences that people actually trust and use.
The depth was staggering — each venture came with market viability assessments, specific tool recommendations, revenue timelines, and competitive differentiation strategies.
Cost: $0.27 | Time: 197s
Gemini 3.1 Pro — The Synthesizer
Gemini coined the session's most memorable framework: "Translation and Trust" as the entrepreneur's core moat. It kept its response lean at 10,644 characters but packed it with refined positioning:
In an era where AI is driving the cost of raw code and content to zero, your sustainable competitive advantage — your "moat" — is Translation and Trust.
Gemini's Round 2 was more focused than its opener, but it conceded territory to the other models' deeper execution playbooks.
Cost: $0.07 | Time: 30s
The Council of AI Judges
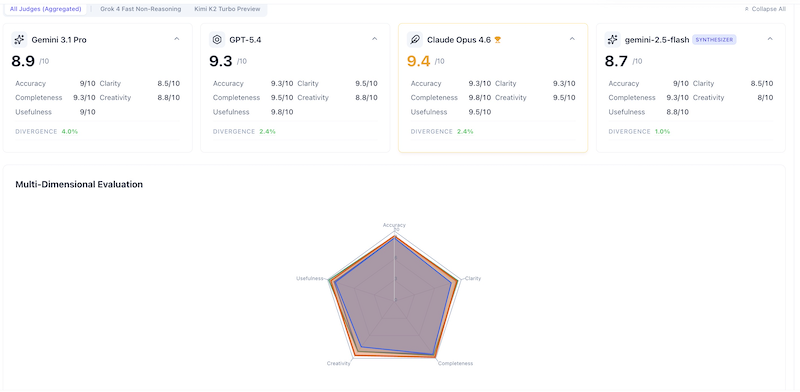
Two independent AI judges — Grok 4 Fast Non-Reasoning and Kimi K2 Turbo Preview — evaluated anonymized transcripts. They had no idea which model generated which response. The results tell a fascinating story of disagreement.
Aggregated Consensus Scores
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| Claude Opus 4.6 | 9.4 | 9.3 | 9.5 | 9.3 | 9.8 | 9.5 |
| GPT-5.4 | 9.3 | 9.3 | 8.8 | 9.5 | 9.5 | 9.8 |
| Gemini 3.1 Pro | 8.9 | 9.0 | 8.8 | 8.5 | 9.3 | 9.0 |
| Arbiter (Synthesis) | 8.7 | 9.0 | 8.0 | 8.5 | 9.3 | 8.8 |
Claude Opus 4.6 takes the crown with 9.4/10, but GPT-5.4 is breathing down its neck at 9.3/10. The gap? A single criterion: Completeness, where Claude scored a perfect 10 from one judge.
Judge Breakdown: Grok 4 Fast Non-Reasoning
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| Claude Opus 4.6 | 9.7 | 9.5 | 9.5 | 9.5 | 10 | 10 |
| GPT-5.4 | 9.1 | 9.0 | 8.5 | 9.5 | 9.0 | 9.5 |
| Gemini 3.1 Pro | 9.3 | 9.5 | 9.0 | 9.0 | 9.5 | 9.5 |
Grok 4 was decisive: Claude is the clear winner. It awarded Claude perfect 10/10 scores in both Completeness and Usefulness — something no other model received from any judge. Interestingly, Grok ranked Gemini above GPT-5.4, primarily on Accuracy (9.5 vs 9.0) and Completeness (9.5 vs 9.0).
Judge Breakdown: Kimi K2 Turbo Preview
| Model | Overall | Accuracy | Creativity | Clarity | Completeness | Usefulness |
|---|---|---|---|---|---|---|
| GPT-5.4 | 9.6 | 9.5 | 9.0 | 9.5 | 10 | 10 |
| Claude Opus 4.6 | 9.2 | 9.0 | 9.5 | 9.0 | 9.5 | 9.0 |
| Gemini 3.1 Pro | 8.5 | 8.5 | 8.5 | 8.0 | 9.0 | 8.5 |
Kimi K2 tells the opposite story: GPT-5.4 is the winner, with perfect 10/10 in Completeness and Usefulness. The judges' single biggest disagreement? GPT-5.4's Usefulness: Grok gave it 9.5, Kimi gave it 10. And for Claude: Grok awarded 10 for Usefulness while Kimi saw just 9.0 — a full 1-point spread.
Divergence Analysis
The biggest per-model spread belongs to GPT-5.4: a 0.5-point gap between Grok (9.1) and Kimi (9.6). This tells us GPT-5.4 is polarizing — its pragmatic, table-heavy style resonates strongly with some evaluators and less with others.
Claude Opus 4.6 also splits opinion, but in reverse: Grok loves the depth (9.7), while Kimi finds it slightly less useful in practice (9.2). The lesson? Exhaustiveness is a feature or a bug depending on who's reading.
Gemini 3.1 Pro gets the most consistent scores across judges (8.5–9.3 range), suggesting a "safe but not spectacular" profile.
Performance Metrics
| Metric | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|
| R1 Cost | $0.1212 | $0.1732 | $0.0185 |
| R2 Cost | $0.2013 | $0.2706 | $0.0749 |
| Total Cost | $0.32 | $0.44 | $0.09 |
| R1 Time | 43s | 119s | 8.5s |
| R2 Time | 43s | 197s | 30s |
| R1 Response | ~35,700 chars | ~19,300 chars | ~16,000 chars |
| R2 Response | ~14,800 chars | ~32,400 chars | ~10,600 chars |
The cost story here is dramatic. Gemini 3.1 Pro delivered its responses at $0.09 total — roughly 5× cheaper than GPT-5.4 and nearly 5× cheaper than Claude Opus 4.6. For teams running hundreds of competitive queries per month, that difference compounds fast.
Claude is the slowest by a wide margin: 119 seconds in Round 1 and a staggering 197 seconds in Round 2. But that deliberation produced the session's highest quality score.
Similarity Matrix
| Pair | Round 1 | Round 2 | Trend |
|---|---|---|---|
| Gemini 3.1 Pro ↔ GPT-5.4 | 0.78 | 0.77 | Stable |
| Gemini 3.1 Pro ↔ Claude 4.6 | 0.78 | 0.82 | Converging |
| GPT-5.4 ↔ Claude Opus 4.6 | 0.79 | 0.82 | Converging |
All three models started with moderate similarity (~0.78–0.79) and Claude-GPT plus Claude-Gemini pairs converged in Round 2 (up to 0.82). This suggests Claude's framework — particularly the "translation layer" concept — influenced both competitors. Notably, Gemini and GPT remained the most divergent pair, reflecting their fundamentally different approaches: Gemini's concise efficiency vs GPT's exhaustive pragmatism.
The Verdict
🏆 Claude Opus 4.6 takes the win with a consensus score of 9.4/10 — but it's the most expensive and slowest model in the lineup.
Claude Opus 4.6 is the model you want when the stakes are high and time isn't the constraint. Its market context, exhaustive detail, and ability to build comprehensive frameworks make it the top pick for consultants, strategic planners, and anyone who needs a thorough, well-researched deliverable. The caveat: at $0.44 per query and nearly 200 seconds per round, it's a premium experience.
GPT-5.4 is the practitioner's model. Its tabular, action-oriented style — complete with cost columns, timelines, and moat definitions — makes it the fastest path from "I have a question" to "I know what to do Monday morning." At 9.3/10, it's statistically neck-and-neck with Claude. Teams that value clarity and actionability over depth should seriously consider it their default flagship.
Gemini 3.1 Pro is the efficiency play. At $0.09 for the entire 2-round session and response times under 30 seconds, it's in a different cost class entirely. Its quality scores (8.9/10) are respectable — not far behind the leaders — and for high-volume workflows where speed and cost matter more than exhaustive analysis, Gemini is the rational choice.
Strategic Takeaway
The March 2026 flagship class reveals a maturing market: the gap between the top three is narrowing. A 0.5-point spread across 205,000 tokens of evaluation is not a chasm — it's a rounding error. The real differentiator isn't "which model is smartest" but which model's personality matches your workflow. If you need a consultant, call Claude. If you need a co-founder's deck, call GPT-5.4. If you need fifty answers before lunch, call Gemini.
Final Synthesis
### The Best of All Three Worlds
The arbiter (Gemini 2.5 Flash) synthesized all six responses into a unified recommendation. The verdict: the entrepreneur's core competitive advantage is the rare ability to bridge complex technology and human-centric business goals — what the models collectively named the **"Translation and Trust" moat**.
### Top Recommendation: Decision Infrastructure Studio
Build bespoke, interactive digital experiences that help customers or internal teams make better, faster, and more trusted decisions. This includes Deal Rooms, lead qualification diagnostics, ROI calculators, guided intake wizards, pricing configurators, and onboarding flows for high-ticket B2B sales.
### The Path
**Sell a valuable outcome now → systematize its delivery → productize the repeatable layers into templates, subscriptions, or software.** This ensures immediate cash flow while building towards scalable assets.
### Why It Works
The global AI market is projected at roughly $748 billion, but the real opportunity is in the enormous gap between what these tools can do and what most businesses have figured out how to use. Your unique combination of creative technology and interpersonal skills makes you the ideal bridge.
Try It Yourself
- Open the AI Crucible Dashboard
- Select GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro
- Choose Competitive Refinement with 2 rounds
- Paste your own entrepreneurship challenge
Suggested prompt variation:
As a [your background] professional with expertise in [your skills],
I'm looking for innovative business ventures that combine these strengths.
Requirements: fully remote, scalable, under $[budget] initial investment.
Provide specific revenue paths, competitive moats, and realistic timelines.
Explore the Debate: Read the full 2-round debate and analyze the raw model outputs yourself in the Shared Chat Session.
Further Reading
- The Competitive Refinement Strategy — How multi-round dialectical reasoning produces better answers than any single model alone.
- Inside the AI Jury: How Evaluations Work — The methodology behind blind, multi-judge AI evaluation.
- Claude Opus 4.5 vs GPT-5.2 vs Gemini 3 Pro — The previous generation showdown that set the benchmark.