Symbolic LLM Planning via Grounded and Reflective Search
The recent paper "SPIRAL: Symbolic LLM Planning via Grounded and Reflective Search" (arXiv:2512.23167, 29 Dec 2025) introduces a fascinating concept: moving Large Language Models from linear "System 1" thinking to recursive, exploratory "System 2" planning.
Assuming a fixed computation budget, SPIRAL demonstrates that allowing an agent to branch, simulate, and backtrack yields significantly better results on complex reasoning tasks than simply prompting a stronger model once.
Inspired by this research, we implemented a Tree Search capability within AI Crucible's Hierarchical Strategy. In this article, we compare the standard linear workflow against this new branching approach.
The Scenario: Designing a Fault-Tolerant Distributed Counter
The User Prompt:
Design a distributed counter system that guarantees strong consistency across 3 geographic regions,
handling network partitions and node failures, using Redis and Go.
The Challenge: This is a classic "architectural trade-off" problem. A linear approach might pick one pattern (e.g., CRDTs) and stick to it, potentially missing a better consistency model (e.g., Raft) that fits the constraints better.
Hierarchical Strategy: Why It Matters
A single LLM, even a powerful one like Claude Sonnet or GPT-5, naturally suffers from context drift and cognitive tunnel vision. When asked to handle strategy, implementation, and review all at once, it often produces hallucinations or mediocre code.
The Hierarchical Strategy solves this by assigning distinct roles:
- Strategist: Focuses solely on high-level planning, requirements, and trade-offs. It does not write implementation code.
- Implementer: Executes the detailed work—writing code, drafting content, or solving math—based strictly on the Strategist's plan.
- Reviewer (Critic): Acts as a quality gate, evaluating the Implementer's output against the Strategist's original requirements.
This separation of concerns mirrors high-functioning human teams. However, the standard Hierarchical flow is still linear: Strategist -> Implementer -> Reviewer. If the Strategist picks a sub-optimal path (e.g., choosing the wrong database), the Implementer wastes time polishing a mistake.
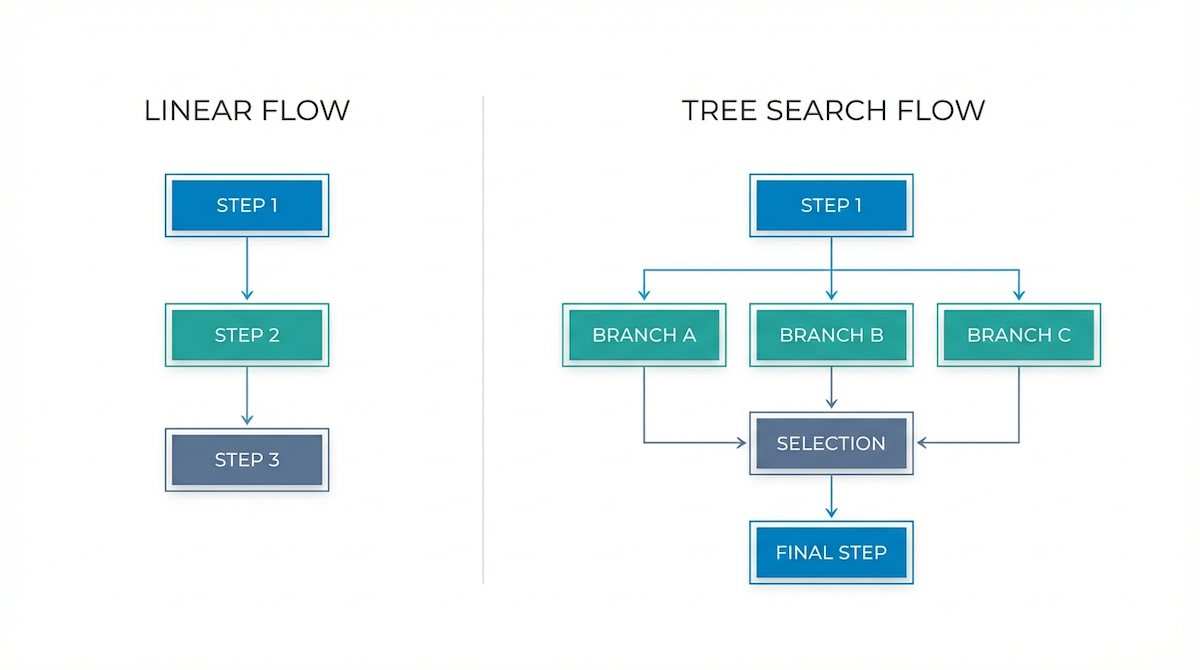
Technical Implementation: How Tree Search Works
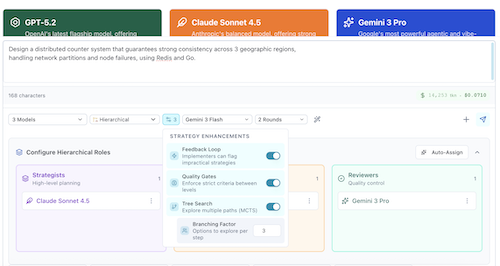
We implemented this capability directly into AI Crucible's dashboard. When the Tree Search toggle is enabled in the Strategy Enhancements menu (visible when "Hierarchical" is selected), the workflow transforms:
- Expansion (Branching): Instead of generating one plan, the Strategist is prompted to generate
Ndistinct, mutually exclusive options (defined by the Branching Factor setting). - Simulation (Parallel Execution): We launch
Nparallel Implementer instances. Each instance fully executes one of the strategic options. This is the grounded "simulation" step—we don't just guess which path is best; we actually try to build them. - Backtracking & Selection: The Reviewer receives all
Nfully executed implementations. It scores them against the original prompt's constraints and selects the single best "Winner."
Note on MCTS: While this approach is inspired by Monte Carlo Tree Search (MCTS), our current implementation utilizes a single-depth expansion (effectively "Best-of-N with Verification"). Full MCTS involves recursive lookahead, which can be prohibitively expensive for long-context tasks. We found that a single level of high-fidelity parallel simulation captures the majority of the "System 2" reasoning benefits while keeping costs manageable.
This architecture allows the system to "backtrack" by discarding entire developed branches that turned out to be dead ends, simulating the recursive planning described in the SPIRAL paper.
Safety Mechanisms
To prevent runaway costs or infinite loops, the production implementation includes:
- Cost Estimation: The system calculates projected costs before execution based on the branching factor and context length.
- Partial Failure Recovery: If one simulation branch fails (e.g., API timeout), the system doesn't crash. It proceeds with the successful branches, ensuring a result is always returned.
- Smart Resource Management: Attachments (images/PDFs) are intelligently filtered—only vision-capable models receive them, saving tokens and preventing API errors.
Dashboard Setup
We configured two sessions in AI Crucible:
Session A (Baseline):
- Strategy: Hierarchical (Sequential)
- Role: Single-pass chain (Strategist -> Implementer -> Reviewer).
- Tree Search: OFF
Session B (Experimental):
- Strategy: Hierarchical (Tree Search)
- Role: Single-pass branching (Strategist -> [Im1, Im2, Im3] -> Reviewer).
- Tree Search: ON
- Branching Factor: 3 (Explore 3 distinct architectures)
Round 1: Expansion vs. Linear Planning
Baseline (Linear)
The Strategist proposed a reasonable "Single-Writer" architecture using Redis for storage and Etcd for leader election. However, it left a critical ambiguity: relying on Redis asynchronous replication for the data itself.
"Redis is used to persist the counter state... One region is 'active' for commits... Cross-region replication exists."
The Implementer proceeded with this "Single Primary + Async Replication" design. It wasn't until Round 3—after the Reviewer flagged that "Async replication violates strong consistency if the leader fails"—that the team finally pivoted to a fully correct Raft-based log approach.
Tree Search (Branching)
The Strategist, prompted to explore 3 options, generated distinct architectural patterns:
- Option 1: Single-Writer (Redis + Etcd) - Similar to the Baseline's initial plan. Relied on Redis async replication.
- Option 2: Global Consensus Log (Raft) - Used a distributed log as the source of truth, with Redis only as a view.
- Option 3: Sharded Counters - Partitioned counters across multiple consensus groups.
The "Aha!" Moment
The Reviewer (Gemini 3 Pro) immediately spotted the flaw in Option 1, identical to the one that plagued the Linear session:
"Option 1: Score 70/100. ...uses asynchronous replication for Redis. ... This violates the 'strong consistency' requirement. If the leader crashes... data is lost."
It then correctly identified Option 2 as the superior architecture:
"Option 2: Score 95/100. ...guarantees linearizability... treats Redis as the state machine (materialized view)..."
Quantitative Comparison
Protocol:
- Standard Hierarchical: Single linear chain.
- Tree Search: Single round with 3 parallel branches.
| Metric | Hierarchical (Sequential) | Tree Search (Parallel) |
|---|---|---|
| Success? | Yes (Eventually) | Yes (First Try) |
| Cost | $0.43 | $0.37 (~15% cheaper) |
| Time | ~2.9 min | ~4.7 min |
| Input Tokens | ~33.2k | ~5.4k |
| Output Tokens | ~26.7k | ~28.0k |
Analytical Overview
The results reveal a fascinating trade-off: Sequential is faster, but Tree Search is cheaper and more thorough.
1. The "Context Isolation" Efficiency
It is counter-intuitive that running more models (3 parallel implementers) results in lower costs ($0.37 vs $0.43). The secret lies in Input Tokens.
- Sequential Chain: The context grows linearly. The Reviewer reads the Prompt + Strategy + Implementation. If the chain iterates or has a long single-thread history, the input token count explodes (~33k tokens).
- Tree Search: Each Implementer branch is isolated. They only see the Prompt + Strategy. They do not see each other's work or a long history of corrections. This "Context Isolation" keeps the massive input costs down (~5.4k tokens).
2. Time vs. Throughput
Sequential is significantly faster (~2.9 min) for a single linear pass.
Tree Search takes longer (4.7 min) because it is generating 3x the volume of implementation work (28k output tokens vs ~26.7k). It is doing the work of three developers in parallel. While slower on the clock, the Information Throughput (useful tokens per minute) is higher.
3. Quality of Reasoning
Both strategies ultimately arrived at a correct solution. However, Tree Search avoided the "local minimum" trap. The Sequential strategy committed early to a fundamentally flawed "Async Redis" design. When the Reviewer effectively "failed" this design, the single linear chain had no backup plan. Tree Search generated that same flawed design as Option 1, but because it also generated Option 2 in parallel, the Reviewer could simply select the better one immediately.
Conclusion
Integrating "SPIRAL-like" Tree Search into the Hierarchical strategy allowed AI Crucible to explore effectively rather than just refine iteratively.
For complex architectural problems, Tree Search is actually more efficient than linear iteration. It prevents the "cognitive tunnel vision" of a single thread and avoids the high token overhead of long conversational contexts.
Related Articles
- Getting Started with AI Crucible
- Ensemble AI Evaluations: A Multi-Dimensional Framework for Quality
- Seven Ensemble Strategies Explained
References
- SPIRAL: Symbolic LLM Planning via Grounded and Reflective Search (2025).
- Raft: In Search of an Understandable Consensus Algorithm (Ongaro & Ousterhout, 2014).
- CRDTs: A Comprehensive Study of Convergent and Commutative Replicated Data Types (Shapiro et al., 2011).