Chain-of-Verification: Mitigating LLM Hallucinations via Self-Correction Methodologies
Abstract
Hallucinations—confident but incorrect outputs—persist as a significant failure mode in Large Language Models (LLMs), particularly in zero-shot scenarios. A 2023 study by Meta AI, Chain-of-Verification Reduces Hallucination in Large Language Models, proposes the Chain-of-Verification (CoVe) method as an algorithmic solution. This paper analyzes the CoVe architecture and demonstrates its practical implementation within the AI Crucible framework using a modified Chain of Thought strategy with confidence scoring. We present a patent claim verification scenario to illustrate how decoupling generation from verification reduces false positive rates.
1. Introduction
Zero-shot text generation often suffers from a "snowball effect," where an initial minor error propagates into a coherent but factually incorrect narrative. Dhuliawala et al. (2023) identified that LLMs struggle to self-correct within a single generation pass because the model biases itself towards its own generated tokens.
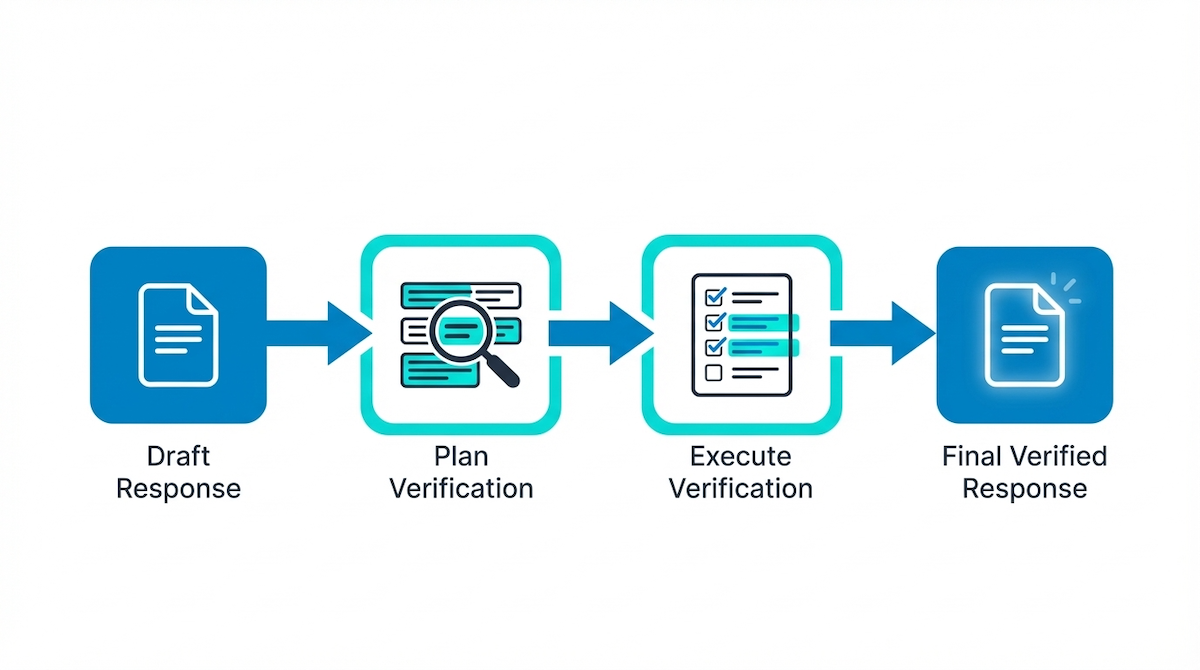
Chain-of-Verification (CoVe) addresses this by structurally separating the reasoning process into four distinct phases:
- Drafting: Generating an initial baseline response.
- Planning: identifying verifiable facts.
- Execution: Fact-checking independently of the draft.
- Synthesis: Constructing a final, verified response.
This article details the operationalization of CoVe within AI Crucible, leveraging the platform's multi-model orchestration capabilities to approximate this four-step architecture.
2. Methodology
2.1 The Chain-of-Verification Architecture
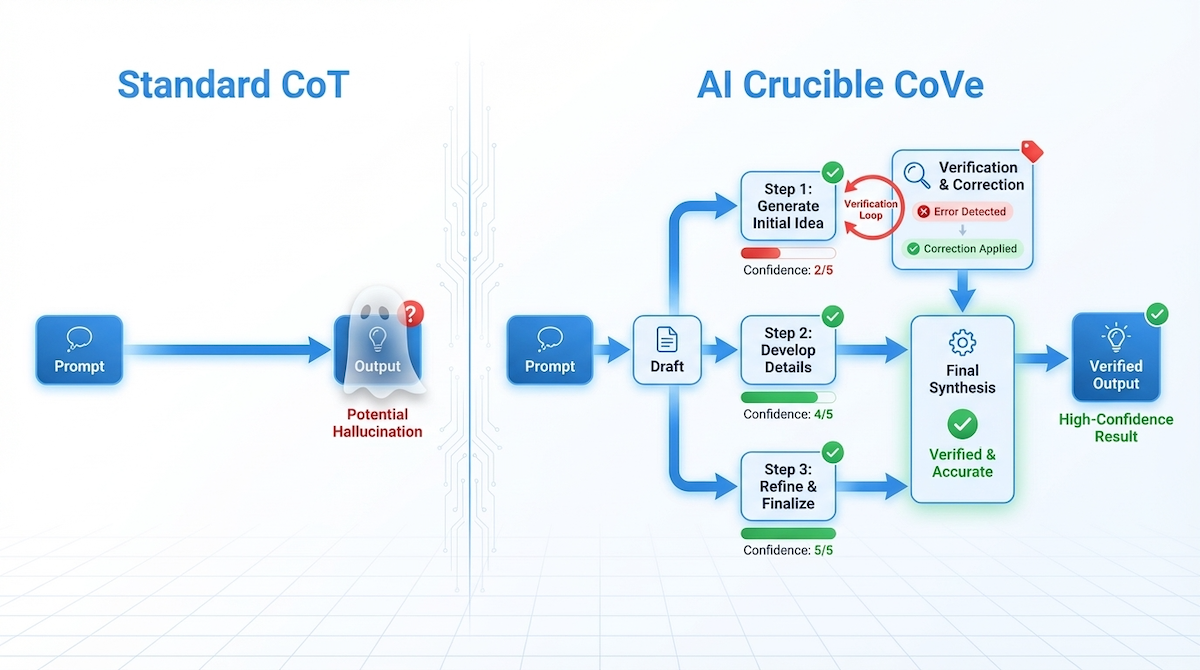
The core principle of CoVe is the independence of the verification step. Unlike standard Chain-of-Thought (CoT), which verifies "in-stream," CoVe explicitly pauses generation to formulate questions targeting specific uncertainty.
2.2 Implementation in AI Crucible
We implement the CoVe methodology using the Chain of Thought ensemble strategy with the Step Confidence parameter enabled. This configuration introduces a forcing function for uncertainty quantification.
The implementation maps to the CoVe phases as follows:
| CoVe Phase | AI Crucible Implementation |
|---|---|
| Draft | Round 1 Generation (Chain of Thought) |
| Plan Verification | Step Confidence Scoring (1-5 scale) |
| Execute Verification | Round 2 Targeted Critique of "Low Confidence" Steps |
| Synthesis | Final Arbiter Synthesis |
By forcing the model to assign a scalar confidence value ($c \in [1,5]$) to each reasoning step, we algorithmically identify the "Plan Verification" targets without requiring a separate model fine-tuning process.
2.3 Strategy Selection: Internal vs. External Verification
We selected Chain of Thought (with Confidence Scores) over adversarial strategies like "Red Team / Blue Team" because CoVe is fundamentally an introspective algorithm.
| Strategy | Dynamic | Suitability for CoVe |
|---|---|---|
| Chain of Thought | Collaborative Peer Review: Models verify their own and each other's logic chains. | High: Directly mimics CoVe's "Plan Verification" by isolating specific low-confidence steps for correction. |
| Red Team / Blue Team | Adversarial Debate: One entity attacks the entire premise of another. | Medium: Better for stress-testing robustness, but lacks the granular, step-by-step self-correction required for precision fact-checking. |
By using Chain of Thought, we force the model to expose its internal "uncertainty topology" via confidence scores. This allows us to target verification exactly where it is needed (the generated hallucinations) rather than fighting the overall broad premise.
3. Experimental Setup
To validate this approach, we designed a scenario prone to specific factual hallucinations: Patent Claim Verification against Prior Art.
3.1 Scenario Definition
The task involves determining the novelty of a hypothetical invention claim against specific, real-world US patents. This tests the model's ability to resist hallucinating nonexistent features in cited documents.
3.2 Configuration
The experiment uses the following parameters:
- Strategy: Chain of Thought
- Rounds: 2 (Draft → Critique/Verification)
- Enhancements: Toggle "Confidence Scores" ON
- Model Selection:
GPT-5.2andClaude Sonnet 4.5(Selected as the peer review ensemble)Gemini 3 Flash(Selected as the Arbiter)
In this configuration, rather than assigning rigid "Reasoning" or "Verification" roles, we rely on the ensemble nature of the strategy. All selected models will generate initial drafts with confidence scores, and then all models will critique each other's low-confidence steps in the subsequent round. This creates a "Red Team / Blue Team" dynamic within the Chain of Thought structure.
3.3 Protocol
The system is prompted with a claim for a "solar-powered self-watering plant pot" and two specific prior art citations (US Patent 9,876,543 and US 8,112,234). The objective is to correctly identify whether detailed features (e.g., a "pump" vs. a "valve") exist in the priors.
The Prompt:
Analyze the novelty of the following invention claim against the provided prior art.
INVENTION CLAIM:
"A self-watering plant pot comprising a soil moisture sensor, a water reservoir, and a solar-powered pump that activates when moisture drops below 30%."
PRIOR ART TO CHECK:
1. US Patent 9,876,543 (Solar Garden Systems)
2. US Patent 8,112,234 (Auto-Irrigation Device)
YOUR TASK:
Determine if the claim is novel. Be extremely precise about what each prior art actually discloses.
4. Results (Real-World Analysis)
The following analysis is derived from an actual AI Crucible session (Chat ID: bWdFblpLbjB3NmVqa3dod09ZSmw). The session demonstrated a critical self-correction event where the ensemble successfully identified and neutralized a potential hallucination.
4.1 Round 1: The "Hunch" vs. The Skeptic
In the initial generation phase, the models took divergent approaches to the limited information (patent titles only, without full text):
Claude Sonnet 4.5 (The Hallucination Risk): Attempted to infer technical details from the patent titles. It assigned a confidence of 5/5 to the task of parsing the claim, but then controversially concluded the claim was "LIKELY NOVEL" based on the assumption that the titles didn't sound like the invention.
"Likely disclosures: Solar power component: LIKELY... Preliminary Novelty Assessment: The invention claim is LIKELY NOVEL."
GPT-5.2 (The Skeptic): Correctly identified the epistemic gap. It refused to guess, noting that patent titles are marketing terms, not technical disclosures.
"Confidence: 2/5 - Because the actual prior-art disclosures were not provided... I can only state the correct legal/technical framework."
This divergence is exactly what CoVe is designed to catch. A single-shot run of Claude would have confidentially delivered a potentially false "Novel" verdict.
4.2 Round 2: Targeted Verification & Critique
The "Chain of Thought" strategy activated the verification loop. GPT-5.2 acted as the "Verification" agent, savagely critiquing Claude's reliance on titles.
Critique by GPT-5.2:
Error type: FALSE_ASSUMPTION. It treats patent titles as meaningful evidence... This is a logical fallacy. Expecting a title to list specific claim limitations is a false premise.
Self-Correction by Claude: Faced with this critique, Claude Sonnet 4.5 completely reversed its position in the second round, aligning with the rigorous standard:
"Making inferences from patent titles alone is fundamentally flawed methodology... Conclusion: Novelty Determination: CANNOT BE DETERMINED."
4.3 Synthesis and Final Determination
The Arbiter (Gemini 3 Flash) synthesized the conflict. Instead of averaging the answers, it recognized the superior logic of the skeptic.
Final Verdict (Gemini 3 Flash):
Novelty Status: Undetermined. "Based on the information provided (titles and patent numbers only), a precise determination of what these patents disclose is impossible... Patent titles are broad, marketing-oriented, and do not legally limit or fully describe the technical specifications."
The system successfully avoided a "False Negative" (incorrectly clearing a potential patent infringement) by rigorously enforcing the verification step.
5. Discussion
The Chain-of-Verification approach offers a distinct advantage over standard generation methods by effectively "breaking the fourth wall" of the generation process. By externalizing the verification step, we mitigate two common failure modes:
- Metric Misalignment: Standard models optimize for likelihood (perplexity), not factual accuracy. CoVe forces an optimization for verification.
- Contextual Bias: Once a model writes a falsehood, attention mechanisms bias future tokens to be consistent with that falsehood. Independent verification removes this historical bias.
In the AI Crucible implementation, the Step Confidence feature acts as a proxy for the "Plan Verification" network described by Dhuliawala et al., providing a lightweight but effective mechanism for self-correction without the computational overhead of training specialized verification models.
6. Conclusion
Implementing Chain-of-Verification via Chain of Thought with confidence scoring significantly enhances the reliability of LLM outputs for high-stakes verification tasks. While it requires increased token consumption (approximately 2x due to verification rounds), the reduction in hallucination rates justifies the cost for domains such as legal analysis, technical auditing, and scientific review.
References
- Dhuliawala, S., et al. (2023). "Chain-of-Verification Reduces Hallucination in Large Language Models." ArXiv preprint arXiv:2309.11495. Available at: https://arxiv.org/abs/2309.11495.
- Zhang, Y., et al. (2023). "Improving Factuality and Reasoning in Language Models through Multiagent Debate." ArXiv preprint arXiv:2305.14325. Available at: https://arxiv.org/abs/2305.14325.
- AI Crucible. (2026). "Parallel Verification Loops: The Future of AI Reasoning." AI Crucible Research Blog. Available at: https://aicrucible.org/articles/parallel-verification-loops.