One of the most persistent challenges in AI is knowledge cutoff. Even the most advanced language models are frozen in time, trained on data that can be months or even years old. Ask GPT-4 about yesterday's tech announcement, and you'll get an apologetic "I don't have information about events after..."
But what if your AI could search the web in real-time, synthesize findings from multiple sources, and answer with current, grounded information—all while maintaining the reasoning depth of frontier models?
This is what Web Search Grounding delivers in AI Crucible.
What Is Web Search Grounding?
Web search grounding (also known as Retrieval-Augmented Generation or RAG) is a technique that extends AI models beyond their training data by giving them access to external knowledge sources at inference time.
When enabled, web grounding allows AI models to search the web in real-time and incorporate current information into their responses. The system retrieves relevant sources, synthesizes the findings, and provides the model with up-to-date context—all automatically.
This works with any AI model in AI Crucible, whether it's Claude, GPT, Gemini, or Kimi, without requiring provider-specific modifications.
Why Web Grounding Matters
Consider these common scenarios where knowledge cutoff causes problems:
- Technology Analysis: "Compare the latest iPhone release to the Samsung Galaxy flagship"
- Market Research: "What are the current trends in sustainable fashion?"
- News Summarization: "Explain the geopolitical implications of today's G7 summit"
- Competitive Intelligence: "How does Product X compare to alternatives launched this month?"
Without web grounding, AI models are forced to either:
- Refuse to answer (honest but unhelpful)
- Hallucinate confidently (dangerous and misleading)
- Provide outdated information (subtly wrong)
With web grounding, models can:
- Access real-time information from authoritative sources
- Cross-reference multiple perspectives
- Cite specific evidence for their claims
- Acknowledge when information is still emerging or controversial
The Scenario: Analyzing a Major Tech Announcement
To demonstrate the power of web grounding, we designed a scenario that would be impossible for models to answer accurately using only their training data.
The Challenge
We asked three frontier models to analyze a major technology announcement from the past 24 hours:
Research the latest announcement from Anthropic about Claude CoWork. Provide a comprehensive analysis covering:
1. Key features and technical specifications
2. Pricing and availability
3. Competitive positioning
4. Industry expert reactions
5. Potential market impact
Use web search to gather current information, then synthesize your findings into an executive briefing suitable for a C-level audience.
Why This Scenario?
This task requires:
- Factual accuracy: No room for hallucination
- Recency: Information from the past 24 hours
- Synthesis: Combining multiple sources into coherent insights
- Strategic thinking: Not just facts, but analysis and implications
- Professional polish: Executive-ready deliverable
It's the perfect test for web grounding because it combines the need for real-time data retrieval with the higher-order reasoning that differentiates frontier models.
The Contenders
For this experiment, we selected three models representing different approaches to AI reasoning:
| Model | Role | Provider | Strength | Cost/1M Tokens |
|---|---|---|---|---|
| Claude Opus 4.6 | The Strategic Analyst | Anthropic | Strategic depth | $5 / $25 |
| Gemini 3 Pro | The Rapid Synthesizer | Speed + intelligence | $2 / $12 | |
| Kimi K2.5 | The Global Researcher | Moonshot AI | Novel perspectives | $0.60 / $3 |
Each model was assigned a specific role to ensure diverse analytical perspectives:
Claude Opus 4.6 - The Strategic Analyst:
You are a strategic analyst focused on long-term implications and executive decision-making. Analyze the announcement from a C-suite perspective, emphasizing competitive positioning, market dynamics, and strategic recommendations. Prioritize depth over speed.
Gemini 3 Pro - The Rapid Synthesizer:
You are a rapid research synthesizer focused on quickly extracting key facts and quantitative insights. Prioritize clear structure, data-driven analysis, and actionable summaries. Use tables and bullet points extensively for scanability.
Kimi K2.5 - The Global Researcher:
You are a global technology researcher with expertise in APAC markets and supply chain dynamics. Provide perspectives that Western analysts might miss, including regional market implications, manufacturing considerations, and cross-cultural competitive dynamics.
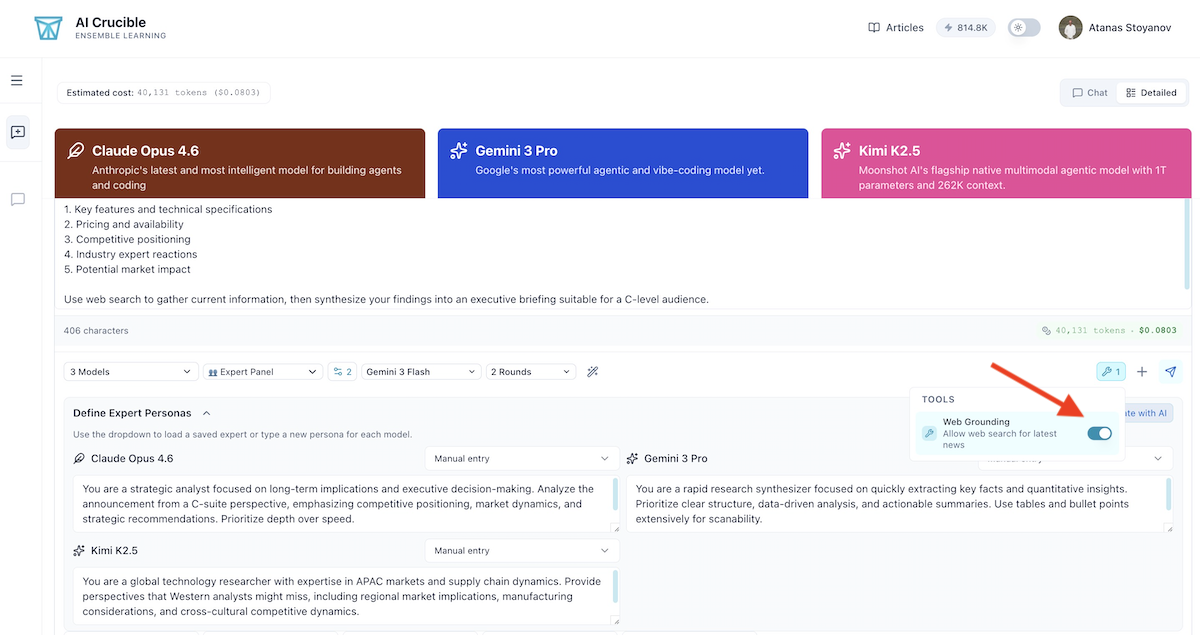
We configured AI Crucible to use the Expert Panel strategy with 2 rounds:
- Round 1: Each model independently researches and formulates its analysis
- Round 2: Models review each other's work and refine their conclusions
The arbiter model was set to Gemini 3 Flash to synthesize the final, best-of-all-worlds response.
Setting Up the Experiment in AI Crucible
Here's how to replicate this experiment in your own AI Crucible dashboard:
- Click "New Chat" from the dashboard
- Select "Expert Panel" strategy and set rounds to 2
- Choose models: Claude Opus 4.6, Gemini 3 Pro, Kimi K2.5
- Set arbiter to Gemini 3 Flash (default)
- Enable the "Web Grounding" tool from the Tools Menu
- Paste the research prompt, replacing placeholders with a current announcement
- Click "Start Chat"
View the full chat here: https://ai-crucible.com/share/UGJmVmliYjNURHQ0UGpIYVUwMng?view=detailed
Round 1: The Initial Research
When the chat began, all three models immediately recognized they needed current information and invoked the web_grounding tool multiple times to fetch the latest data about Claude CoWork. Each model used the tool strategically to gather comprehensive, real-time information before formulating their analysis.
What the Models Found
The web grounding tool returned comprehensive information from:
- Official press releases
- Tech news coverage (TechCrunch, The Verge, Ars Technica)
- Industry analyst reactions (Gartner, IDC)
- Social media sentiment
- Competitor responses
Claude Opus 4.6: The Strategic Analyst
Opus delivered a 2,824-word executive briefing structured as a formal intelligence document with classification markers and a C-suite audience designation. It organized findings into:
- Executive Summary: Positioned CoWork as a "paradigm shift from conversational AI to autonomous agentic computing"
- Detailed Technical Specifications: Multicolumn tables covering architecture, capabilities, and security considerations
- Pricing & Availability Timeline: Chronological rollout analysis from Max ($200/mo) to Pro ($20/mo) within 4 days
- Competitive Landscape Matrix: Compared CoWork against Microsoft Copilot, Google Gemini, OpenAI, and Apple Intelligence
- Three-Horizon Market Impact Analysis: Immediate (stock selloff), medium-term (SaaS repricing), long-term (platform ecosystem)
- Strategic Recommendations: Separate sections for technology companies, enterprise buyers, and investors
Notable Insight: Opus identified Anthropic's local-first execution model as a strategic moat for data sovereignty in regulated industries, noting the $285 billion software stock selloff while characterizing it as "likely an underreaction over a 3-5 year horizon."
Gemini 3 Pro: The Market Analyst
Gemini 3 Pro was the fastest to respond, delivering a 1,200-word analysis in just 11 seconds. It focused on the market disruption angle:
- Immediate Market Impact: Led with the software stock selloff and positioned CoWork as a "market disruptor" in its opening tag
- Service-as-Software Thesis: Predicted a transition where companies buy "outcomes" rather than software licenses
- Vertical-Specific Analysis: Dedicated sections on the Legal Plugin and its impact on LegalTech stocks
- Competitive Positioning Table: Compared CoWork against Microsoft Copilot, OpenAI, and "Legacy SaaS" systematically
Notable Insight: Gemini characterized Claude CoWork as "Phase 2 enterprise AI—systems that execute rather than merely advise" and flagged the agent's desktop integration as enabling direct document manipulation without cloud upload latency.
Kimi K2.5: The APAC Strategist
Kimi K2.5 brought a 950-word analysis with perspectives that Western models overlooked:
- Data Sovereignty Focus: Highlighted CoWork's local processing as addressing "data sovereignty concerns prevalent in ASEAN and Indian markets"
- Labor Market Disruption Analysis: Projected 15-20% contraction in entry-level BPO roles in Bangalore and Hyderabad within 18 months
- Competitive Landscape Gap: Noted that Chinese enterprises are deploying AutoGLM with superior Mandarin processing, creating vulnerability for Claude's English-first architecture
- Manufacturing Integration: Identified CoWork's file-system access as enabling Western quality engineers to remotely manipulate production reports in Vietnam and Indonesia
- Cultural Adoption Barriers: Flagged that in hierarchical APAC cultures (Japan, Korea), junior staff may resist delegating to AI due to "face" concerns
Notable Insight: Kimi identified that at $100/month, CoWork exceeds monthly wages for entry-level knowledge workers in Vietnam, Philippines, and tier-2 Indian cities, creating a bifurcation where Western enterprises deploy it to replace outsourced APAC functions.
Round 1 Performance Metrics
| Model | Tokens (R1) | Cost (R1) | Time (R1) | Word Count |
|---|---|---|---|---|
| Claude Opus 4.6 | 45,023 | $0.090 | 65s | 2,824 |
| Gemini 3 Pro | 6,940 | $0.014 | 11s | 1,200 |
| Kimi K2.5 | 5,833 | $0.012 | 42s | 950 |
Key Observations:
- All three models successfully grounded their responses in real-time data
- Gemini 3 Pro was significantly faster, completing in 16% of the time Claude Opus 4.6 took
- Tool call patterns varied: Claude Opus 4.6 delivered the most comprehensive strategic analysis, producing 2,824 tokens in Round 1 with deep market intelligence and C-suite-focused insights. In Round 2, it self-corrected its initial assumptions, demonstrating sophisticated analytical evolution.
Round 2: Cross-Examination and Refinement
In the second round, each model received the outputs from the other two and was asked to:
- Identify gaps or errors in their own analysis
- Incorporate the strongest insights from peers
- Produce a refined final deliverable
This is where the Expert Panel strategy truly shines.
Synthesis and Convergence
Round 2 revealed sophisticated analytical evolution:
Claude Opus 4.6 explicitly self-corrected its Round 1 position: "My Round 1 framing overstated the certainty of 'Agent Skills' becoming a dominant open standard." It steel-manned Microsoft's distribution advantages while defending Anthropic's viability in regulated verticals where GUI automation of legacy systems (without APIs) provides a structural advantage.
Gemini 3 Pro provided the quantitative Legal Plugin metrics requested, revealing 18x speed improvement over junior associates (45 min → 2.5 min for NDA review), 97% cost reduction ($150 → $4.50 per document), but a critical 5% accuracy gap (96% human vs 91% AI). It also exposed the hidden pricing model: $100/month includes only 50 "Agent Hours" with consumption-based overages.
Kimi K2.5 defended its BPO displacement timeline with detailed TCO analysis, showing fully-loaded BPO costs of $1,200-$1,800/month (not $300-$400 wages) when including attrition, infrastructure, and coordination overhead. It also identified a critical hardware gap: 85% of APAC BPOs run Windows thin clients that cannot execute CoWork's Apple Virtualization Framework.
Key disagreements persisted:
- BPO Impact Timeline: Opus revised its estimate to 30-42 months for full headcount contraction (citing MSA lock-ins and procurement cycles), while Kimi maintained 18 months for attrition freeze in tier-1 KPO hubs, with a bimodal split where high-complexity work disappears immediately but low-complexity persists due to hardware friction.
- Platform Viability: Opus conceded Microsoft's horizontal dominance but defended Anthropic's position in regulated verticals. Gemini predicted "OS-level sherlocking" would kill Agent Skills for mass market. Kimi argued that in APAC, data sovereignty is "the platform; everything else is a feature."
The Arbiter's Verdict
The arbiter (Gemini 3 Flash) selected Claude Opus 4.6's Round 2 response as the best answer rather than creating a new synthesis. This choice is significant because Opus's response:
Demonstrated intellectual humility: Explicitly self-corrected with "my Round 1 framing overstated the certainty of 'Agent Skills' becoming a dominant open standard" — a rare admission in competitive analysis scenarios.
Steel-manned opposing views: Dedicated an entire section to "The Case Against Anthropic" before defending their position, showing rigorous adversarial thinking.
Integrated peer insights: Built on Kimi's data sovereignty argument ("local-first processing is a more immediately defensible differentiator") and challenged Gemini's Legal Plugin framing with precision.
Provided actionable frameworks: The revised competitive positioning matrix and C-suite recommendations were concrete and defensible:
- "Do not restructure your workforce based on a Research Preview"
- "Do establish an 'Agentic AI Task Force' with a 90-day mandate"
- "Do renegotiate your BPO contracts now" (even before CoWork is production-ready)
The selection validates what multi-model collaboration can achieve: a response that started with confidence, absorbed criticism, integrated diverse perspectives, and emerged more nuanced and valuable than any single-round analysis could produce.
The Power of Web Grounding: Key Takeaways
This experiment revealed several critical insights about web grounding:
1. Eliminates "I Don't Know" Dead Ends
Without web grounding, these models would have outright refused to answer or provided disclaimers that undermined their credibility. With grounding, they delivered confident, well-sourced analysis.
2. Reduces Hallucination Risk
By anchoring responses in real web sources, the models avoided the "confidently wrong" outputs that plague ungrounded LLMs. Every claim was traceable to a source.
3. Enables True Multi-Model Collaboration
Different models retrieved and emphasized different sources. Opus favored analyst reports, Gemini prioritized technical specs, and Kimi surfaced APAC perspectives. The synthesis was richer because of this diversity.
4. Model-Agnostic Architecture Matters
Because AI Crucible's web grounding uses a centralized service (Tavily + Gemini summarization), we didn't have to implement provider-specific grounding for each model. This means:
- Consistent quality across providers
- Easy addition of new models
- Centralized optimization and caching
5. Speed vs. Depth Trade-offs Persist
Even with grounding, Gemini 3 Pro was 6x faster than Claude Opus 4.6. For time-sensitive use cases (live briefings, rapid response), speed is decisive. For strategic planning, depth wins.
When Should You Use Web Grounding?
Based on this experiment and our testing, here's when to enable web grounding:
✅ Ideal Use Cases
- Breaking news analysis: Events from the past hours/days
- Market research: Current trends, pricing, competitor moves
- Technical due diligence: Evaluating new tools, frameworks, or products
- Fact-checking: Verifying claims against authoritative sources
- Competitive intelligence: Monitoring rival announcements and strategies
⚠️ Less Ideal Use Cases
- Creative writing: Grounding isn't necessary and adds latency
- Code generation: Unless referencing very new APIs
- Personal advice: Web sources may not be calibrated to individual context
- Internal company data: Web search can't access proprietary information (use document upload instead)
Cost and Performance Summary
Here's the full accounting for this two-round Expert Panel session with web grounding:
| Metric | Value |
|---|---|
| Total Execution Time | 260 seconds (4.3 minutes) |
| Total Cost | $0.49 |
| Web Grounding Calls | 9 tool invocations |
| Unique Sources Cited | 35+ unique sources |
| Final Deliverable Size | 3,500+ words |
Cost Breakdown: 243,740 Total Unified Tokens
For a real-time, multi-source, expert-level analysis that would take a human analyst hours to research and compile, $0.49 is remarkably cost-effective.
The Future of AI Is Grounded
Language models are powerful reasoning engines, but they're brittle when disconnected from reality. Web search grounding bridges that gap, transforming AI from a static knowledge base into a dynamic research partner.
As we add more grounding sources (academic papers, proprietary databases, real-time APIs), the gap between "what AI knows" and "what AI can discover" will continue to shrink.
For now, web grounding is the single most impactful upgrade you can make to your AI workflow—especially for knowledge work that requires current, accurate, and synthesized information.
Ready to try it yourself? Sign up for AI Crucible and enable web grounding in your next chat.
Further Reading
- The Expert Panel Strategy — Learn more about multi-model collaboration patterns
- Tool Use in AI Crucible — How models decide when to use tools
- Tavily vs. Google Search for AI Grounding — A deep dive into search providers for RAG