How Prompt Classification Powers Smarter AI Ensembles
Most AI platforms treat every prompt the same way: paste your question, pick a model, get a response. But not every question deserves the same treatment. A creative writing prompt and a legal compliance query need fundamentally different strategies, models, and iteration depths to produce their best results.
AI Crucible's Prompt Assistant solves this by classifying your prompt in real time and automatically recommending the optimal ensemble configuration — strategy, models, and rounds — tailored to what you're actually asking.
Time to read: 8-12 minutes
The Problem: One Size Doesn't Fit All
When you type a prompt into a multi-model AI platform, you face a cascade of decisions:
- Which strategy? Should models compete, collaborate, debate, or reason step-by-step?
- Which models? Premium reasoning models or fast efficient ones? US providers or Chinese models?
- How many rounds? One pass or iterative refinement?
- What optimization? Speed, cost, depth, or a balanced approach?
Making these choices correctly requires understanding both the nature of your prompt and the strengths of each model. This applies the Prompt Assistant automates.
How Prompt Classification Works
The moment you type a prompt, AI Crucible's classification engine analyzes it through a multi-layered pipeline:
Step 1: Category Detection
Your prompt is scanned against curated keyword dictionaries spanning 14 distinct categories:
| Category | What it Detects | Example Keywords |
|---|---|---|
| Creative Content | Writing, storytelling, artistic work | write, story, poem, narrative |
| Business Strategy | Planning, GTM, competitive analysis | strategy, ROI, revenue, pricing |
| Marketing | Campaigns, branding, social media | ad copy, campaign, SEO, funnel |
| Technical/Coding | Programming, architecture, debugging | code, API, algorithm, deploy |
| Technical Writing | Documentation, guides, API docs | manual, specification, readme |
| Research & Analysis | Deep dives, comparisons, studies | analyze, benchmark, hypothesis |
| Educational | Explanations, tutorials, learning | explain, tutorial, fundamentals |
| Decision Support | Pros/cons, trade-offs, recommendations | should I, options, trade-off |
| Problem Solving | Debugging, troubleshooting, optimization | fix, solve, troubleshoot, bug |
| Communication | Emails, presentations, proposals | email, pitch, announcement |
| Content Strategy | SEO content, editorial calendars | content plan, editorial, topic cluster |
| Product Development | Feature specs, user stories, PRDs | feature, MVP, roadmap, sprint |
| Legal & Compliance | Legal analysis, contracts, regulations | compliance, GDPR, liability |
| Data Science | ML models, statistics, data analysis | machine learning, regression, dataset |
The classifier uses word boundary matching for single keywords and substring matching for multi-word phrases, giving phrase matches double the weight of single-word matches. This means detecting "machine learning" in your prompt carries more signal than detecting "data" alone.
Step 2: Confidence Scoring
Not every classification is equally certain. The system computes a confidence score based on how dominant the primary category is relative to all other matches:
- High confidence (> 0.7): The classification is used directly — no server round-trip needed.
- Low confidence (< 0.7): The system triggers a server-side LLM analysis for more accurate classification.
This two-tier approach keeps the UI snappy for clear-cut prompts while falling back to deeper analysis for ambiguous ones.
Step 3: Complexity Estimation
Beyond category, the system estimates how complex your prompt is across four levels:
| Level | Score Threshold | Recommended Rounds | Characteristics |
|---|---|---|---|
| Simple | < 4 | 1-2 | Single-focus, straightforward |
| Moderate | 4-7 | 2-3 | Multi-aspect, some nuance |
| Complex | 8-14 | 3-4 | Multi-domain, requires synthesis |
| Expert | 15+ | 4-5 | Highly specialized, deep analysis |
Complexity scoring factors in:
- Keyword density — expert terminology adds +3 per term
- Structural indicators — bullet points, numbered lists, requirements
- Prompt length — longer prompts (>500 tokens) score higher
- Complexity keywords — terms like "comprehensive," "multi-faceted," or "systematic"
Step 4: Entity Detection and Sentiment Analysis
The classifier also detects:
- Named entities — industries (SaaS, healthcare), technologies (React, Kubernetes), business concepts (GTM, B2B)
- Sentiment/approach — whether the prompt is analytical, creative, or neutral
- Real-time data needs — keywords like "current," "latest," "2026," or "trending"
- Domain specificity — prompts mentioning multiple specialized entities get flagged
From Classification to Configuration
Once the prompt is classified, the Prompt Assistant maps the result to a complete ensemble configuration through three interconnected systems:
Strategy Mapping
Each category maps to a primary strategy and alternatives:
| Category | Primary Strategy | Why |
|---|---|---|
| Creative | Competitive Refinement | Models compete for the most original approach |
| Business | Collaborative Synthesis | Combines strategic insights from multiple viewpoints |
| Technical | Chain of Thought | Step-by-step reasoning catches errors |
| Research | Expert Panel | Diverse expert perspectives from different angles |
| Decision | Debate Tournament | Structured debate explores both sides thoroughly |
| Problem Solving | Chain of Thought | Systematic reasoning validates each step |
| Legal | Red Team / Blue Team | Adversarial review identifies risks |
| Marketing | Competitive Refinement | Competitive iteration polishes messaging |
| Product Dev | Hierarchical | Structured workflow: strategists → implementers → reviewers |
| Data Science | Chain of Thought | Methodical reasoning validates statistical approaches |
| Educational | Collaborative Synthesis | Clear, synthesized explanations |
| Communication | Competitive Refinement | Models compete for the most effective message |
| Content Strategy | Expert Panel | Multi-perspective: SEO, editorial, marketing |
| Technical Writing | Collaborative Synthesis | Comprehensive, well-synthesized documentation |
Data-Driven Model Selection
Model selection goes beyond static rankings. The system uses a blended scoring formula that combines three signals:
modelScore(model, category) =
0.50 × userVoteApproval(model, category)
+ 0.30 × benchmarkWinRate(model, category)
+ 0.20 × staticExpertRanking(model, category)
User votes (50% weight) — Real approval rates from community voting on model outputs within each category. If users consistently upvote Claude Sonnet 4.5 for creative writing, that signal directly influences recommendations.
Benchmark win rates (30% weight) — Aggregated evaluation scores from AI judge panels across thousands of real sessions. These capture how often a model wins head-to-head comparisons in each category. You can explore the latest results on the Benchmarks Dashboard.
Static expert rankings (20% weight) — Curated rankings based on known model capabilities. This provides a stable baseline and prevents cold-start problems for new models.
Cold-Start Logic
When a model has fewer than 20 votes and fewer than 10 evaluations in a category, the system gracefully degrades:
- Zero data: Falls back to pure static ranking
- Sparse data: Weights shift heavily toward static (80% static, 10% votes, 10% benchmarks)
- Sufficient data: Full blended weights apply
This ensures new models aren't unfairly penalized while established models benefit from rich performance data.
Optimization Priorities
Users can select one of four priorities that further filter the model pool:
| Priority | Models Favored | Max Cost | Max Rounds |
|---|---|---|---|
| Speed | Gemini 3 Flash, GPT-4 Mini, Claude Haiku 4.5 | $0.10 | 2 |
| Cost | DeepSeek Chat, Qwen Flash, Ministral 3B | $0.05 | 2 |
| Depth | Claude Opus 4.5, GPT-5.1, Gemini, Grok 4 | $1.00 | 5 |
| Balanced | Claude Sonnet 4.5, GPT-5.1, Gemini, Qwen Plus | $0.30 | 3 |
Region Preferences
For teams with data sovereignty requirements, the system supports geographic filtering:
- US/European Only — OpenAI, Anthropic, Google, Mistral, xAI, Meta
- Chinese Only — Alibaba Qwen, Moonshot Kimi, DeepSeek
- All Models — Maximum diversity across all providers
- Strategic Mix — Curated selection from both regions
The Enhancement Engine
Classification doesn't just recommend configuration—it actively helps you write better prompts. Based on the detected category, the Prompt Assistant generates contextual improvement suggestions:
Category-Specific Enhancements
| Category | Enhancement | Impact |
|---|---|---|
| Business | Define your target market or audience | High |
| Business | Include budget constraints or range | Medium |
| Technical | Specify programming language or tech stack | High |
| Creative | Specify desired tone or style | High |
| Decision | List your decision criteria or priorities | High |
| Research | Define the scope or focus area | High |
| Problem Solving | Describe what you've already tried | High |
| Legal | Specify the applicable jurisdiction | High |
| Data Science | Describe your data or dataset | High |
Each enhancement includes:
- A placeholder so you can add context inline
- An impact rating (high, medium, low)
- A reason explaining why this improves AI output quality
Universal Enhancements
Short prompts (under 100 characters) always receive a suggestion to add context. Business and problem-solving prompts without timeline mentions get a deadline suggestion. These universal checks apply regardless of category.
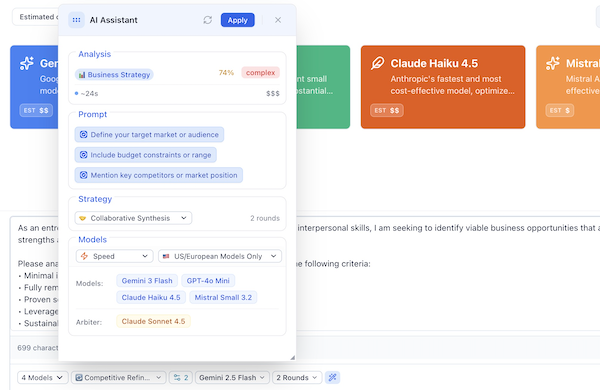
Putting It All Together: A Complete Example
Let's walk through what happens when you type this prompt:
"Design a go-to-market strategy for a B2B SaaS product targeting mid-market CFOs. Include pricing tiers, channel strategy, and competitive positioning against established players."
1. Classification
- Primary category: Business Strategy (matched: strategy, go-to-market, pricing, competitive, positioning, B2B, SaaS)
- Secondary categories: Marketing (matched: channel strategy, positioning)
- Confidence: 0.88 (high — no LLM fallback needed)
- Complexity: Expert (score 18 — multiple structural requirements, expert terms, domain-specific)
- Entities detected: SaaS, B2B, CFO
- Sentiment: Analytical
- Real-time data: Not required
2. Recommended Configuration
| Parameter | Value | Reasoning |
|---|---|---|
| Strategy | Collaborative Synthesis | Business decisions benefit from synthesized perspectives combining strategic insights |
| Rounds | 4 | Expert-level complexity benefits from maximum refinement |
| Models | Claude Sonnet 4.5, GPT-5.1, Gemini 2.5 | Top-scoring models for Business category based on blended data |
| Arbiter | Gemini 3 Flash | Fast, capable synthesis at low cost |
| Priority | Depth | Expert-level task warrants premium models |
3. Suggested Enhancements
The system identifies that the prompt is strong but could benefit from:
- "Include budget constraints or range" — Budget info helps AI suggest feasible pricing tiers
- "Mention key competitors or market position" — Naming competitors enables sharper positioning
4. One-Click Apply
The user reviews the recommendations, optionally adjusts models or rounds, and clicks Apply. The full configuration — strategy, models, rounds, arbiter, and optionally an enhanced prompt — is applied to the chat session instantly.
Why This Matters
For Beginners
The Prompt Assistant eliminates the learning curve. You don't need to know that legal prompts benefit from adversarial Red Team / Blue Team strategies or that technical debugging works best with Chain of Thought reasoning. The system makes the right call automatically.
For Power Users
Even experienced users benefit from data-driven model selection. The blended scoring formula surfaces models that perform well for your specific prompt type based on community votes and benchmark data. This is information no individual user could track across 30+ models and 14 categories.
For Teams
Optimization priorities and region preferences let teams standardize their AI workflows:
- Compliance teams can restrict to US/European models only
- Cost-conscious teams can set budget-friendly defaults
- Research teams can prioritize depth and premium models
The Technical Architecture
The classification system is designed for speed and reliability:
- Client-side first: High-confidence classifications happen instantly in the browser — no network latency
- Server fallback: Ambiguous prompts trigger LLM-powered classification on the backend
- Shared codebase: The classifier runs identically on client and server via shared TypeScript modules
- Cached rankings: Vote and benchmark data are cached with intelligent TTLs to avoid redundant Firestore reads
- Cold-start resilient: New models gracefully degrade to static rankings until sufficient data accumulates
Try It Yourself
- Go to the AI Crucible Dashboard
- Type any prompt in the chat input
- Watch the Prompt Assistant panel appear with real-time classification
- Review the recommended strategy, models, and rounds
- Click Apply to configure your session automatically
Suggested prompt to try:
Analyze the competitive landscape for AI coding assistants in 2026.
Compare GitHub Copilot, Cursor, and Windsurf across pricing,
feature depth, and enterprise adoption. Recommend which tool
a 50-person engineering team should adopt and why.
This prompt triggers Research & Analysis classification with Expert Panel strategy — giving you independent expert perspectives from multiple AI models.
Key Takeaways
- 14 categories cover the full spectrum of professional prompts — from creative writing to legal compliance
- Automatic strategy mapping matches each category to the ensemble strategy that produces the best results
- Data-driven model selection blends community votes (50%), benchmark evaluations (30%), and expert rankings (20%)
- Complexity-aware round counts adjust iteration depth based on prompt sophistication
- Contextual enhancements help you write better prompts before you even start
The Prompt Assistant transforms AI Crucible from a tool you configure into a tool that configures itself — putting the right models, strategy, and iteration depth behind every question you ask.
Related Articles
- Seven Ensemble Strategies — Overview of all available orchestration strategies
- Competitive Refinement Strategy — Deep dive into competitive iteration
- Expert Panel Strategy — When you need specialized perspectives
- Getting Started Guide — Quick start for new users