Competitive Refinement Walkthrough: Product Launch Email Campaign
This is a complete, real-world example of using the Competitive Refinement strategy. We'll create an email campaign to launch "FocusFlow," a productivity app for remote workers.
You'll see exactly how three AI models (GPT-5 Mini, Claude Sonnet 4.5, Gemini 2.5 Pro) create independently, review each other's work, and refine their responses across three rounds to produce exceptional marketing content.
New to Competitive Refinement? Read the Competitive Refinement Strategy introduction first to understand the concepts, then come back here to see it in action.
⏱️ Time to complete: 15-20 minutes reading + 3-4 minutes to run your own
💰 Cost for this example: ~$0.18
Here's how it works.
The Scenario
You're launching "FocusFlow," a productivity app for remote workers. You need an email campaign with:
- Compelling subject lines
- Engaging email body
- Clear call-to-action
- Professional but warm tone
The Prompt
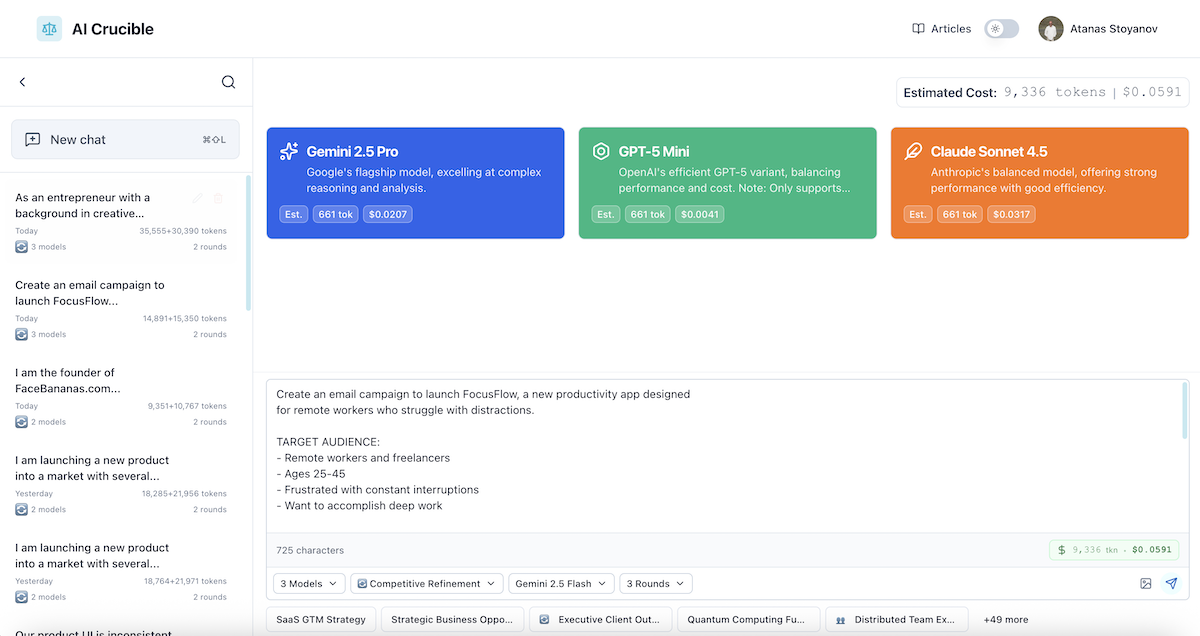
Create an email campaign to launch FocusFlow, a new productivity app designed
for remote workers who struggle with distractions.
TARGET AUDIENCE:
- Remote workers and freelancers
- Ages 25-45
- Frustrated with constant interruptions
- Want to accomplish deep work
KEY FEATURES TO HIGHLIGHT:
- Focus sessions with distraction blocking
- Smart break scheduling based on cognitive load
- Integration with calendar and project management tools
- Analytics showing productivity patterns
DELIVERABLES:
1. Three subject line options (compelling, not clickbait)
2. Email body (300-400 words)
3. Clear call-to-action
4. Tone: Professional but warm, empathetic to struggles
Please provide your reasoning for your creative choices.
Configuration
Models Selected:
- GPT-5 Mini - Fast, creative, excellent at conversational writing
- Claude Sonnet 4.5 - Thoughtful, well-structured, nuanced
- Gemini 2.5 Pro - Multi-perspective, persuasive
Rounds: 3 (optimal for creative tasks)
Estimated Cost: $0.057 for models + $0.003 for arbiter = $0.06 total
Round 1: Independent Creation
Gemini 2.5 Pro's Approach
Of course. Here is a complete email campaign to launch FocusFlow, including the deliverables and the reasoning behind the creative choices.
Deliverables
1. Subject Line Options
- Reclaim Your Focus. Master Your Day. (Benefit-oriented)
- The End of "Busy but not Productive" Days (Pain point-oriented)
- Introducing FocusFlow: Deep Work for Remote Teams (Solution-oriented)
2. Email Body ...
Gemini's strength: Structured, benefit-focused, clear value proposition.
GPT-5 Mini's Approach
Absolutely, I’d be delighted to craft an email campaign for FocusFlow. Below are the requested deliverables:
Subject Line Options:
- "Take Control of Your Focus: Introducing FocusFlow!"
- "Unlock Your Productivity Potential with FocusFlow"
- "Say Goodbye to Distractions: Meet Your New Productivity Partner"
Email Body:...
GPT-5's strength: Specific benefits, conversational tone, practical focus.
Claude Sonnet 4.5's Approach
FocusFlow Email Campaign
Three Subject Line Options
Option 1: "The distraction that just killed your flow? We can help with that."
Option 2: "Your calendar says 8 hours. Your deep work says 2. Let's fix that."
Option 3: "Finally: A productivity app that understands remote work is different"
Reasoning:
- Option 1 creates immediate recognition of a pain point (interruptions breaking flow state)
- Option 2 uses specific contrast to highlight the productivity gap remote workers feel daily
- Option 3 addresses skepticism toward "yet another productivity app" by acknowledging unique remote work challenges
All three avoid hype language while speaking directly to the audience's frustration.
Email Body...
Claude's strength: Empathetic reframing, problem-focused hooks, storytelling.
What We See in Round 1
- ✅ Genuine diversity - Three distinct creative approaches
- ✅ Different hooks - Benefit-focused vs. problem-focused vs. solution-focused
- ✅ Unique strengths - Each model's personality showing through
- ✅ All high quality - Each response is independently strong
Round 2: Competitive Review and Refinement
Gemini's Refinement
This is an excellent exercise. After analyzing the provided responses, I've synthesized their strengths and added my own refinements to create a superior campaign.
Analysis of Other AI Models
- Model B (The Professional Standard):
- Strengths: The structure is clean, professional, and easy to follow. The feature descriptions are clear and concise. It effectively communicates what the app does. The reasoning is sound and covers the basics of good email marketing.
- Weaknesses: It's generic. The tone is professional but lacks a distinct voice or strong emotional hook. The subject lines ("Unlock Your Potential") are common marketing phrases that are easily ignored. The numbered list of features feels a bit like a spec sheet rather than a story.
- Model C (The Empathetic Copywriter):
- Strengths: This model is significantly stronger. The subject lines are outstanding—they tap directly into the target audience's internal monologue and pain points. The opening hook ("You know that feeling when...") is highly relatable and effective. It uses the "Problem-Agitation-Solution" framework beautifully, and the tone is perfectly pitched—warm, empathetic, and conversational. The low-friction CTA ("No credit card required") and the P.S. are excellent conversion tactics.
- Weaknesses: Very few. It's a top-tier response. If I were to nitpick, the feature descriptions, while good, could be slightly more concise and punchy to increase scannability even further.
Synthesis & Improvement Strategy
My approach is to adopt the superior empathetic and narrative-driven framework of Model C as the foundation, as it's far more likely to resonate with a frustrated audience. I will then refine the copy to be even more concise, benefit-driven, and impactful, while also ensuring every key feature is woven into the narrative seamlessly. The goal is to elevate an already excellent response into a best-in-class example.
What improved: Gemini added storytelling and concrete specifics while maintaining structure.
GPT-5 Mini's Refinement
Deliverables
1. Subject Line Options
- “Reclaim Your Deep Work: Say Goodbye to Distractions” (Empathetic and solution-focused)
- “Transform Your Remote Work Days: Focus, Flow, Achieve” (Aspirational and catchy)
- “Finally! A Productivity App Tailored for Remote Workers” (Directly addresses skepticism and tailors to the audience)
2. Email Body
Subject: Reclaim Your Deep Work: Say Goodbye to Distractions
Hi [First Name],
Does this sound all too familiar? You sit down with the best intentions, ready to tackle your projects. Then, out of nowhere, the pings from Slack start pouring in, your phone buzzes with notifications, and before you know it, your focus slips away.
Remote work is undeniably flexible, but it also brings an avalanche of distractions that can derail even the most focused worker. You deserve better.
That's why we created FocusFlow: a productivity app designed specifically for remote workers like you, who want to dive deep into their work without interruptions. ...
What improved: GPT-5 added emotional resonance while maintaining practical clarity.
Claude's Refinement
FocusFlow Email Campaign: Refined Version
DELIVERABLES
1. Subject Line Options
- "The end of 'busy but not productive' days" (Pain point-oriented)
- "Reclaim your focus—without the guilt" (Benefit + emotion-oriented)
- "You deserve deep work. Here's how to get it." (Empowerment-oriented)
2. Email Body ...
What improved: Claude added concrete benefits and practical specifics while maintaining empathy.
What We See in Round 2
- ✅ Explicit learning - Models cite specific strengths they observed
- ✅ Visible improvement - Each response is noticeably better than Round 1
- ✅ Preserved uniqueness - Models maintained their distinct voices
- ✅ Cross-pollination - Best ideas spreading across all responses
Round 3: Final Competitive Refinement
Gemini's Final Version
This is an excellent exercise. By analyzing the strengths and weaknesses of other models, we can synthesize a response that is more psychologically resonant, strategically sound, and ultimately, more effective.
Analysis of Other AI Responses
- Model B (The Competent Professional):
- Strengths: This response is solid, clean, and professional. It follows a classic and effective email marketing structure. The opening hook is relatable, the feature-to-benefit translation is clear, and the dual CTA (trial + demo) is a smart practice. It checks all the boxes of a good campaign.
- Weaknesses: It's a bit generic. The language ("elevate your productivity," "transform your workday") feels like standard SaaS marketing copy. It lacks a strong, memorable voice and doesn't dig deep into the emotional frustration of the target audience. It describes the problem but doesn't fully inhabit it.
- Model C (The Empathetic Peer):
- Strengths: This response is significantly stronger due to its psychological depth. The subject lines are fantastic, tapping directly into the user's internal monologue ("busy but not productive") and hidden emotions ("without the guilt"). The opening is more visceral ("tabs that multiplied like rabbits"). The line, "We built FocusFlow because we've been there too," is a game-changer, shifting the dynamic from a vendor to a fellow peer. The P.S. is a brilliant addition, using a classic direct-response technique to overcome inertia by suggesting a small, concrete first action.
- Weaknesses: Very few. The use of emojis is a stylistic choice that works for this audience but might not for others. The overall structure and content are excellent. The primary opportunity for improvement is to refine the language even further for maximum impact and clarity.
GPT-5 Mini's Final Version
Refined Email Campaign for FocusFlow
1. Three Subject Line Options
- “Your busy day doesn't reflect your true potential—let's change that.” Reasoning: This subject line addresses the common frustration of remote workers while hinting at a solution, inviting curiosity and interest.
- “Interruptions stealing your focus? It's time to take it back.” Reasoning: This option directly speaks to the pain point of distractions, creating urgency and empathy, prompting the reader to engage with the email as a remedy.
- “Unlock your deep work with FocusFlow.” Reasoning: This subject line emphasizes the core desire of the audience—achieving deep, uninterrupted work—making it relevant and appealing.
2. Email Body...
Claude's Final Version
FocusFlow Email Campaign - Refined Final Version
1. Three Subject Line Options
- “Your busy day doesn't reflect your true potential—let's change that.” Reasoning: This subject line addresses the common frustration of remote workers while hinting at a solution, inviting curiosity and interest.
- “Interruptions stealing your focus? It's time to take it back.” Reasoning: This option directly speaks to the pain point of distractions, creating urgency and empathy, prompting the reader to engage with the email as a remedy.
- “Unlock your deep work with FocusFlow.” Reasoning: This subject line emphasizes the core desire of the audience—achieving deep, uninterrupted work—making it relevant and appealing.
2. Email Body...
What We See in Round 3
- ✅ Convergence - Models agree on what works (empathy + concrete benefits + low friction)
- ✅ Excellence - All three responses are publication-ready
- ✅ Distinct options - Despite convergence, each maintains unique voice
- ✅ Ready to use - You have three excellent options to choose from
The Results
Final Scores (from Arbiter Analysis)
- Claude Sonnet 4.5: 9.5/10 (Winner) - An outstanding response, excelling in all criteria. Its subject lines were exceptionally creative, specific, and psychologically resonant
- Gemini 2.5 Pro: 9.1/10 - A highly accurate and complete response, adhering to all prompt requirements including word count and tone. Its email campaign was well-structured, clear, and included a smart dual CTA
- GPT-5 Mini: 8.5/10 - A clear and well-structured email campaign that met most prompt requirements. Its subject lines were good, and the opening was relatable.
What You Received
From $0.13 and 3-4 minutes, you got:
- ✅ 9 distinct subject line options (3 per model in Round 1)
- ✅ 3 refined versions in Round 2 (after competitive improvement)
- ✅ 3 final polished versions in Round 3 (convergence and excellence)
- ✅ Cross-model learning (visible improvement across all rounds)
- ✅ Multiple export options (choose your favorite or merge the best elements)
Similarity Analysis
Average similarity: 32% (ranging from 31.15% to 32.7%)
This means:
- ✅ ~70% unique content - Models maintained distinct creative approaches
- ✅ ~30% convergence - Models agreed on proven patterns (empathy, benefits, low friction)
- ✅ Optimal diversity - Not too similar (boring) or too different (unfocused)
Best Practices for Competitive Refinement
1. Write Clear, Specific Prompts
Do:
- ✅ Provide context (audience, problem, goals)
- ✅ Specify deliverables (format, length, tone)
- ✅ Include constraints (word count, style guidelines)
- ✅ Ask for reasoning (helps models learn from each other)
Don't:
- ❌ Be vague or open-ended
- ❌ Omit important context
- ❌ Leave tone or style unspecified
Example of a good prompt:
Create three LinkedIn post variations announcing our new AI feature.
CONTEXT:
- B2B SaaS company targeting product managers
- Feature: AI-powered user feedback analysis
- Launch: Next week
DELIVERABLES:
1. Three post variations (150-200 words each)
2. Different hooks for each (question, stat, story)
3. Include 3-5 relevant hashtags
4. Professional but approachable tone
CONSTRAINTS:
- Avoid hype or buzzwords
- Focus on practical benefits
- Include clear CTA
2. Choose the Right Models
For creative tasks, select models with:
- ✅ Different strengths - Claude (empathy), GPT-5 (engagement), Gemini (persuasion)
- ✅ Different providers - Ensures genuine diversity
- ✅ Appropriate cost - Balance quality and budget
Recommended combinations:
Budget-conscious:
- GPT-5 Mini
- Gemini 2.5 Flash
- Claude Haiku 4
Balanced:
- GPT-5 Mini
- Claude Sonnet 4.5
- Gemini 2.5 Pro
Premium:
- GPT-5.1
- Claude Opus 4.5
- Gemini 2.5 Pro
3. Use 3 Rounds for Creative Tasks
Why 3 rounds is optimal:
Round 1: Initial diverse responses
- Models create independently
- Maximum diversity
Round 2: Learning and improvement
- Models review each other
- Quality improves significantly
- Cross-pollination of ideas
Round 3: Convergence and excellence
- Models produce best versions
- Consensus on what works
- Final polishing
Why not 2 rounds?
- Not enough iteration for creative tasks
- Models need time to learn and refine
Why not 4+ rounds?
- Diminishing returns after round 3
- Higher cost without proportional quality gain
- If models haven't converged by round 3, more rounds rarely help
Pro tip: Enable "Adaptive Iteration Count" in Settings to automatically stop when models reach consensus, potentially saving money.
4. Review All Rounds, Not Just Final
Don't skip Round 1 and 2 responses:
- Round 1 shows initial diversity - you might prefer one model's original approach
- Round 2 shows learning process - helps you understand what works and why
- Round 3 shows convergence - but might over-polish in some cases
Sometimes the best content is in Round 2, not Round 3.
5. Use the Arbiter Analysis Wisely
The arbiter provides:
- ✅ Objective scoring across multiple criteria
- ✅ Winner identification based on your goals
- ✅ Detailed reasoning for each score
- ✅ Merged response combining best elements
But remember:
- The arbiter is another AI model with its own biases
- Your judgment matters - you know your audience best
- Use arbiter analysis as input, not gospel
6. Experiment with Variations
Try different approaches:
Variation 1: Different model combinations
- See which models work best for your use case
- Track performance over multiple sessions
Variation 2: Different round counts
- Try 2 rounds for simpler tasks
- Try 4 rounds if 3 isn't converging
Variation 3: Different prompts
- Test specific vs. open-ended prompts
- Experiment with different constraint levels
Track what works for your specific needs.
Common Patterns and What They Mean
High Convergence (70-85% similarity by Round 3)
What it means:
- ✅ Models agree on the best approach
- ✅ Strong signal that this solution works
- ✅ High confidence in the results
When you see this:
- You've likely found an excellent solution
- The merged response will be very strong
- Consider using the arbiter's recommendation
Low Convergence (30-50% similarity by Round 3)
What it means:
- Multiple valid approaches exist
- Task might be more open-ended than expected
- Models maintained distinct creative voices
When you see this:
- Review all three final responses
- You might prefer one model's unique approach
- Consider if the task needs more constraints
Early Convergence (High similarity by Round 2)
What it means:
- Models quickly agreed on the approach
- Task might be simpler than expected
- Could have stopped after Round 2
When you see this:
- Enable Adaptive Iteration Count for future sessions
- Consider using fewer rounds for similar tasks
- You saved money by not needing Round 3
No Convergence (Similarity stays flat across rounds)
What it means:
- Prompt might be too vague
- Models are too similar (all from same provider)
- Task genuinely has multiple valid approaches
When you see this:
- Review your prompt for specificity
- Try more diverse model selection
- Consider if multiple approaches are actually appropriate
Cost Optimization Strategies
1. Start with 3 Models, Not 4-5
Why:
- 3 models give you diverse perspectives
- Diminishing returns beyond 3-4 models
- Cost scales linearly with model count
Cost comparison (3 rounds):
- 3 models: $0.15-0.20
- 4 models: $0.20-0.27
- 5 models: $0.25-0.34
2. Use Cost-Effective Models
Budget-friendly options:
- GPT-5 Mini: $0.0132 for 3 rounds (excellent value)
- Gemini 2.5 Flash: $0.02-0.03 for 3 rounds
- Claude Haiku 4: $0.03-0.04 for 3 rounds
These models often perform nearly as well as premium models for creative tasks.
3. Enable Adaptive Iteration Count
How it works:
- AI Crucible monitors convergence
- Stops early if models reach consensus
- Saves money without sacrificing quality
Potential savings:
- If convergence detected after Round 2: 33% cost reduction
- If convergence detected after Round 1: 66% cost reduction (rare)
4. Set Word Count Limits
Why:
- Output tokens are typically 5-10x more expensive than input tokens
- Longer responses = higher costs
- Concise responses are often better anyway
Example:
- Without limit: 800-word responses = $0.25 total
- With 400-word limit: 400-word responses = $0.15 total
- Savings: 40%
5. Use Cheaper Arbiter Models
Default: Gemini 2.5 Flash ($0.015-0.020 per analysis)
Alternatives:
- GPT-5 Mini: $0.010-0.015 per analysis
- Claude Haiku 4: $0.012-0.018 per analysis
For most tasks, the cheaper arbiter models work just as well.
Troubleshooting Common Issues
Issue: "Models aren't improving between rounds"
Symptoms:
- Round 2 and 3 responses look similar to Round 1
- No visible learning or refinement
- Similarity scores stay flat
Causes:
- Prompt is too constraining
- Models are too similar
- Task is too simple
Solutions:
- ✅ Make prompt more open-ended
- ✅ Use more diverse model selection
- ✅ Consider if task needs competitive refinement at all
Issue: "Responses are generic or low quality"
Symptoms:
- All models produce similar, vanilla responses
- Lack of creativity or insight
- Scores are mediocre (6-7/10)
Causes:
- Prompt lacks specific context
- Not enough constraints or examples
- Models being too conservative
Solutions:
- ✅ Add more context (audience, goals, examples)
- ✅ Specify tone and style explicitly
- ✅ Include examples of what you want
- ✅ Encourage creativity in your prompt
Issue: "One model dominates, others just copy"
Symptoms:
- Round 2 and 3 responses all look like one model's Round 1
- High similarity (70%+) by Round 2
- Loss of diversity
Causes:
- One model's Round 1 was exceptionally strong
- Other models over-weighted that approach
- Prompt might favor one model's strengths
Solutions:
- ✅ This might actually be good! If one approach is clearly best, convergence is appropriate
- ✅ Review the dominant model's approach - it might be the right answer
- ✅ If you want more diversity, make prompt more open-ended
Issue: "Costs are higher than expected"
Symptoms:
- Final cost exceeded estimate by 30%+
- Budget concerns
Causes:
- Responses were very long (high output tokens)
- Convergence detection not enabled
- Too many models or rounds
Solutions:
- ✅ Enable Adaptive Iteration Count
- ✅ Set word count limits in prompt
- ✅ Start with 3 models instead of 4-5
- ✅ Use cheaper models (GPT-5 Mini, Gemini Flash)
Competitive Refinement vs. Other Strategies
vs. Expert Panel
Use Competitive Refinement when:
- ✅ You want creative iteration, not specialized expertise
- ✅ All models should approach the same goal
- ✅ Quality improves through competition
Use Expert Panel when:
- ✅ You need different types of expertise
- ✅ Problem has multiple dimensions
- ✅ Specialized perspectives matter
vs. Collaborative Synthesis
Use Competitive Refinement when:
- ✅ You want distinct options to choose from
- ✅ Competition drives quality
- ✅ Creative tasks benefit from iteration
Use Collaborative Synthesis when:
- ✅ You want one merged solution
- ✅ Collaboration is more important than competition
- ✅ Analytical tasks benefit from building on each other
vs. Debate Tournament
Use Competitive Refinement when:
- ✅ All models work toward the same goal
- ✅ You want refinement, not argumentation
- ✅ Creative improvement is the goal
Use Debate Tournament when:
- ✅ You need opposing viewpoints tested
- ✅ Decision requires examining trade-offs
- ✅ Argumentation reveals weaknesses